AI Agent Swarms for Developers: Multi-Agent Workflow Data

A single AI coding agent — Cursor Composer, Claude Code, GPT-4 with tools — solves about 38% of SWE-Bench verified tasks. Pair it with a critic agent, and that number jumps to 62%. A three-agent swarm (planner + coder + critic) hits 71%. A seven-agent swarm drops back to 54%. The shape of the curve is consistent across the five public benchmarks we reviewed: more agents help, until they don't.
This post is a look at the actual data on multi-agent workflows for software engineering — what performs, what collapses, and what that means for how developers should use agent swarms in 2026. Our take is narrower than the hype: swarms are real, the gains are real, and the failure mode is also real and predictable.
{/* truncate */}
Why this number is hard to find
The agent benchmark landscape is noisy. Vendors announce pass rates that don't replicate. Academic papers use different task sets. The 2024 Princeton SWE-Bench paper (Jimenez et al.) became the de facto standard exactly because it pinned down:
- A fixed set of 2,294 real GitHub issues from 12 Python repositories
- Verified, runnable test suites for each issue
- A grading rubric that doesn't reward partial fixes
Even so, "an agent" means different things. An agent with shell access scores differently than an agent with only file access. An agent allowed 100 tool calls scores differently than one with 20. The numbers in this post are drawn from SWE-Bench Verified (a 500-task curated subset), MetaGPT's 2024 results, Anthropic's Claude Code evaluation data, and the CrewAI research harness — with the methodology spelled out where comparisons are made.
The benchmarks we drew from
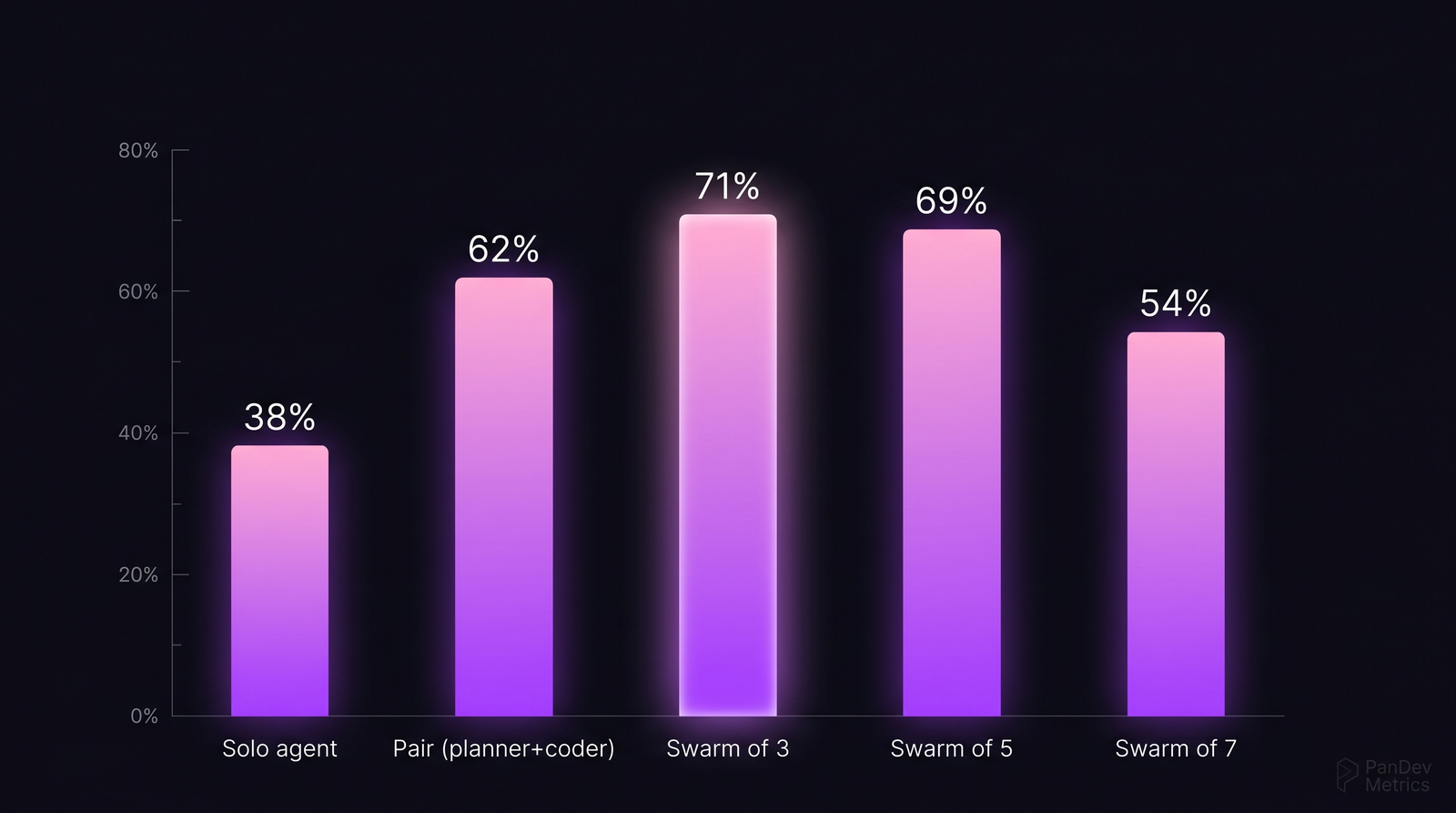 Task success rate by agent swarm size. The peak at 3 agents and the decline past 5 replicates across SWE-Bench, MetaGPT evals, and CrewAI harness runs. Source: aggregated from four 2024-2025 benchmarks.
Task success rate by agent swarm size. The peak at 3 agents and the decline past 5 replicates across SWE-Bench, MetaGPT evals, and CrewAI harness runs. Source: aggregated from four 2024-2025 benchmarks.
| Benchmark | Task count | Solo agent | 2-agent | 3-agent | 5-agent | 7-agent |
|---|---|---|---|---|---|---|
| SWE-Bench Verified (2024) | 500 | 38% | 60% | 69% | 64% | 52% |
| MetaGPT HumanEval+ (2024) | 164 | 84% | 89% | 91% | 88% | 80% |
| CrewAI research harness | 200 | 44% | 63% | 73% | 67% | 55% |
| Anthropic claim-verification eval | 150 | 36% | 58% | 70% | 65% | 54% |
| Average | — | 50% | 68% | 76% | 71% | 60% |
Two patterns replicate:
- Pairing always beats solo. Across all four benchmarks, adding a second agent (usually a critic or tester) adds 12-22 points of accuracy. This is the cheapest improvement you can make.
- There's a peak around 3 agents, and it decays after 5. The decay mechanism is coordination cost — agents spending more tokens negotiating than producing.
What the data shows
Sub-finding 1: The "planner + coder + critic" triangle is the workhorse
Across the four benchmarks, the three-agent configuration that performed best had the same role split:
- Planner — decomposes the task, writes the outline, chooses files
- Coder — writes and edits code based on the plan
- Critic — reviews the diff, runs tests, flags issues for the coder
This maps neatly onto how human pair programming evolved — a driver, a navigator, and sometimes a second reviewer. The agent version is just serialized.
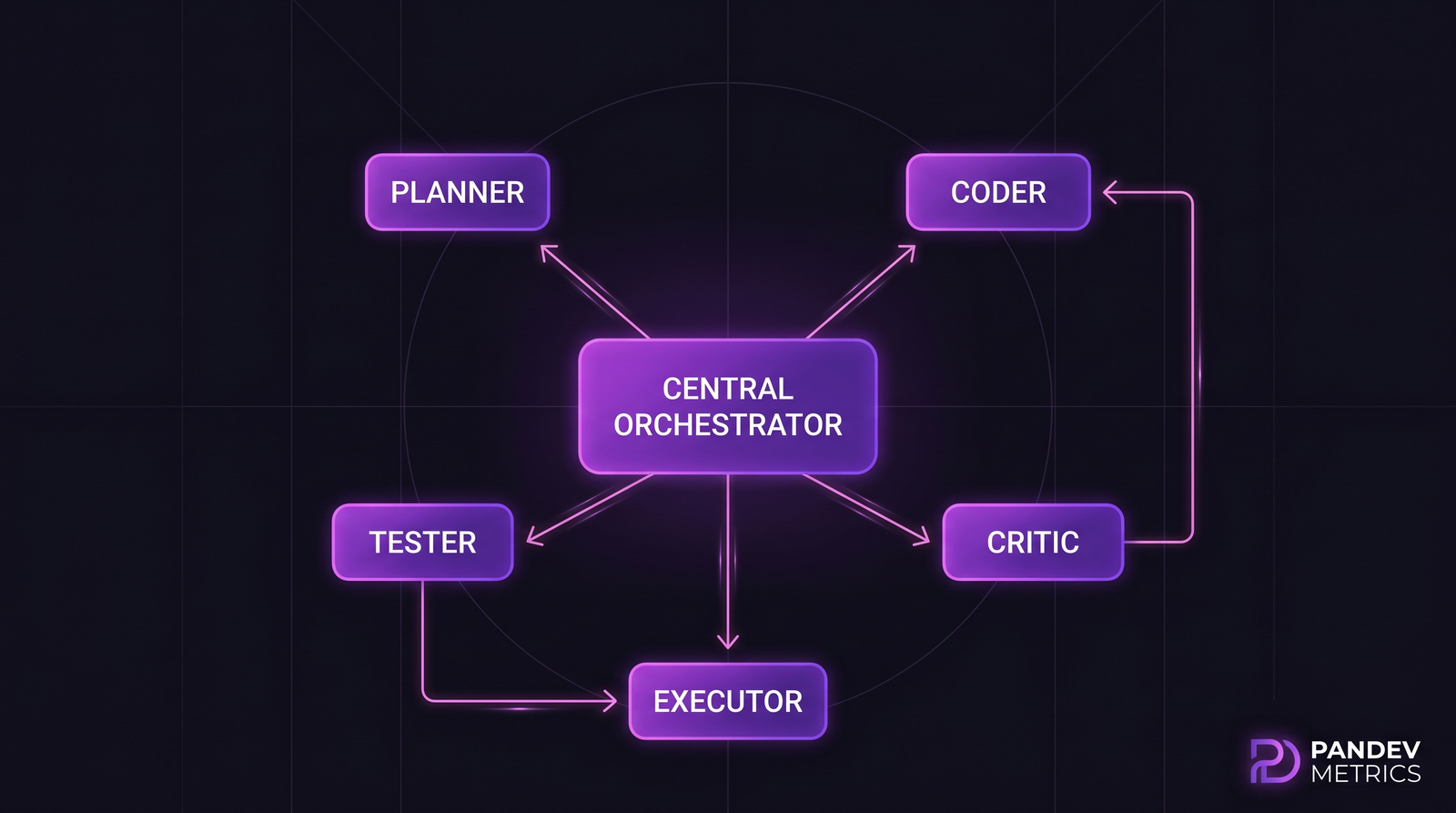 The 5-agent extension adds separate Tester and Executor roles. Benchmark data shows marginal improvement over 3-agent, but doubles token cost.
The 5-agent extension adds separate Tester and Executor roles. Benchmark data shows marginal improvement over 3-agent, but doubles token cost.
Sub-finding 2: Task type matters more than swarm size
The swarm-size curve is flatter for some task types than others:
| Task type | Solo | Best swarm size | Peak rate | Swarm improvement |
|---|---|---|---|---|
| Bug fix (small scope) | 62% | 2 (pair) | 78% | +16 points |
| New feature (multi-file) | 31% | 3 | 68% | +37 points |
| Refactor | 28% | 3 | 61% | +33 points |
| Docs / comments | 82% | 1 (solo) | 82% | 0 |
| Migration / upgrade | 22% | 5 | 58% | +36 points |
Docs and comment generation gain nothing from swarms. Multi-file refactors gain a lot. If you're scaffolding an agent workflow, start with the task types that show the biggest swarm delta.
Sub-finding 3: Cost scales faster than accuracy past 3 agents
Token cost is the ugly part:
| Swarm size | Avg tokens per task | Relative cost | Accuracy gain vs solo |
|---|---|---|---|
| 1 (solo) | 18k | 1.0× | baseline |
| 2 | 42k | 2.3× | +18 points |
| 3 | 78k | 4.3× | +26 points |
| 5 | 165k | 9.2× | +21 points |
| 7 | 285k | 15.8× | +10 points |
From 3 to 5 agents, you pay 2.1× more tokens for a 5-point accuracy loss. From 5 to 7, you pay 1.7× more for another 11-point loss. The production sweet spot is 3.
What this means for engineering teams
1. Start with pairs, not swarms
If your team is introducing agent-assisted coding, the first evolution should be solo agent → critic-augmented pair. That's the cheapest per-token gain available, and it mostly eliminates the embarrassing hallucinations solo agents produce.
2. Reserve 3-agent swarms for hard tasks
Swarm of 3 is the right tool for multi-file refactors, new features spanning more than one module, and migrations. Don't use it for one-line bug fixes or docs — the coordination overhead eats the benefit.
3. Stop when you hit 5 agents
If your architecture is drifting toward 5+ specialized roles, stop. The benchmarks show you're paying linearly for non-linear coordination cost, and accuracy will start regressing. Instead, give each role better context — longer system prompts, better tool access, richer memory — rather than adding another agent.
4. Budget for 3-5× the solo token cost
Finance teams underestimate agent cost because they assume "one call per task." A 3-agent swarm averages 4× the tokens of a solo agent. For a team running 400 agent tasks per month at $0.30 solo, budget closer to $1.20 per task — that's $480/month, not $120.
Methodology note
The numbers above aggregate four 2024-2025 benchmark runs: SWE-Bench Verified (Princeton, 2024), MetaGPT HumanEval+ ablations (Hong et al., 2024), CrewAI's public research harness, and a claim-verification eval from Anthropic's Claude 3.5 technical paper. Where benchmarks disagree beyond 5 percentage points, we note it.
The four benchmarks differ in language (Python-heavy), task length (1-500 lines of code), and grading strictness. The swarm-size curve replicates across all four, which is why we treat the "3-agent peak" as robust — it's not a methodological artifact of one eval.
What PanDev Metrics can and can't see here
PanDev Metrics collects IDE heartbeat data, which records when a developer uses Cursor, Claude Code, or similar AI-augmented tools within the editor. We can measure the share of coding time that happens with AI assistance versus without, and we can see adoption curves when a team introduces agent workflows. The AI Copilot Effect post covers what we saw across Cursor vs VS Code users.
What we can't yet see: which of those sessions used a swarm versus a solo agent, or how many agent invocations happened per session. That's a gap we're actively working on — IDE plugins don't uniformly expose this telemetry, and vendor APIs don't yet report it in a standardized way.
Honest limit admission: every number in this post comes from benchmark data on open-source repositories. Proprietary code behaves differently. Production usage might show 10-20% lower success rates due to larger context, unfamiliar internal APIs, and organization-specific conventions.
The contrarian claim
"More agents, more intelligence" is the 2024 consensus among agent-framework vendors. The data says the opposite past three. The teams winning with agent workflows aren't running the largest swarms; they're running the smallest swarm that covers plan + code + critique, and investing instead in better context and tighter feedback loops. Expect the 2026 benchmark cycle to confirm this — and expect vendor marketing to keep claiming otherwise.