AI Code Review: Does It Actually Help? (Data from 100 Teams)

AI code review sits at the crest of the hype cycle. GitHub Copilot, CodeRabbit, Qodo, Graphite, and half a dozen startups are pitching a future where LLMs catch bugs faster than humans. Microsoft Research and Bacchelli's seminal 2013 study on code review established the baseline we've been measuring against for a decade: human review catches ~14% of functional defects but 68% of maintainability issues. The question now is: does layering an LLM on top actually move either number?
We pulled review data from 100 B2B teams between Q1 2025 and Q1 2026: a mix of teams using AI review, teams not, and teams running hybrid. The pattern isn't what the vendors claim.
{/* truncate */}
Why this number is hard to find
The AI code review space is dominated by vendor-produced studies. GitHub's own 2024 Copilot Workspace report, Graphite's case studies, and the handful of CodeRabbit blog posts all measure "review time saved" without measuring defect escape rate: the share of real bugs that got through review and hit production.
Measuring only review time is like measuring only cooking time when evaluating a restaurant. Faster isn't better if the soufflé collapses.
Our angle is different: we tracked review time + defect escape rate + rework rate together, across four configurations:
- No AI. Pure human review.
- AI-only. LLM auto-approves if it sees no issues.
- AI-assisted. LLM comments inline, humans decide.
- Hybrid strict. LLM comments + humans required + LLM doesn't have merge authority.
Only configuration 4 improves on baseline across all three dimensions.
Our dataset
- 100 B2B engineering teams, sizes from 5 to 120 engineers
- Q1 2025 through Q1 2026, 12 months of pull-request data
- 23,847 pull requests across repositories
- IDE heartbeat telemetry for the time engineers spent in review (not just PR calendar age)
- 30-day post-merge defect tracking linked back to originating PRs via branch names
The defect tracking is the unusual part. Most studies that cite review-defect-escape numbers infer from survey data or 7-day incident windows. We linked branch names to incidents for 30 days post-merge, which is long enough for most functional bugs to surface.
What the data shows
Review time: hybrid wins, AI-only loses
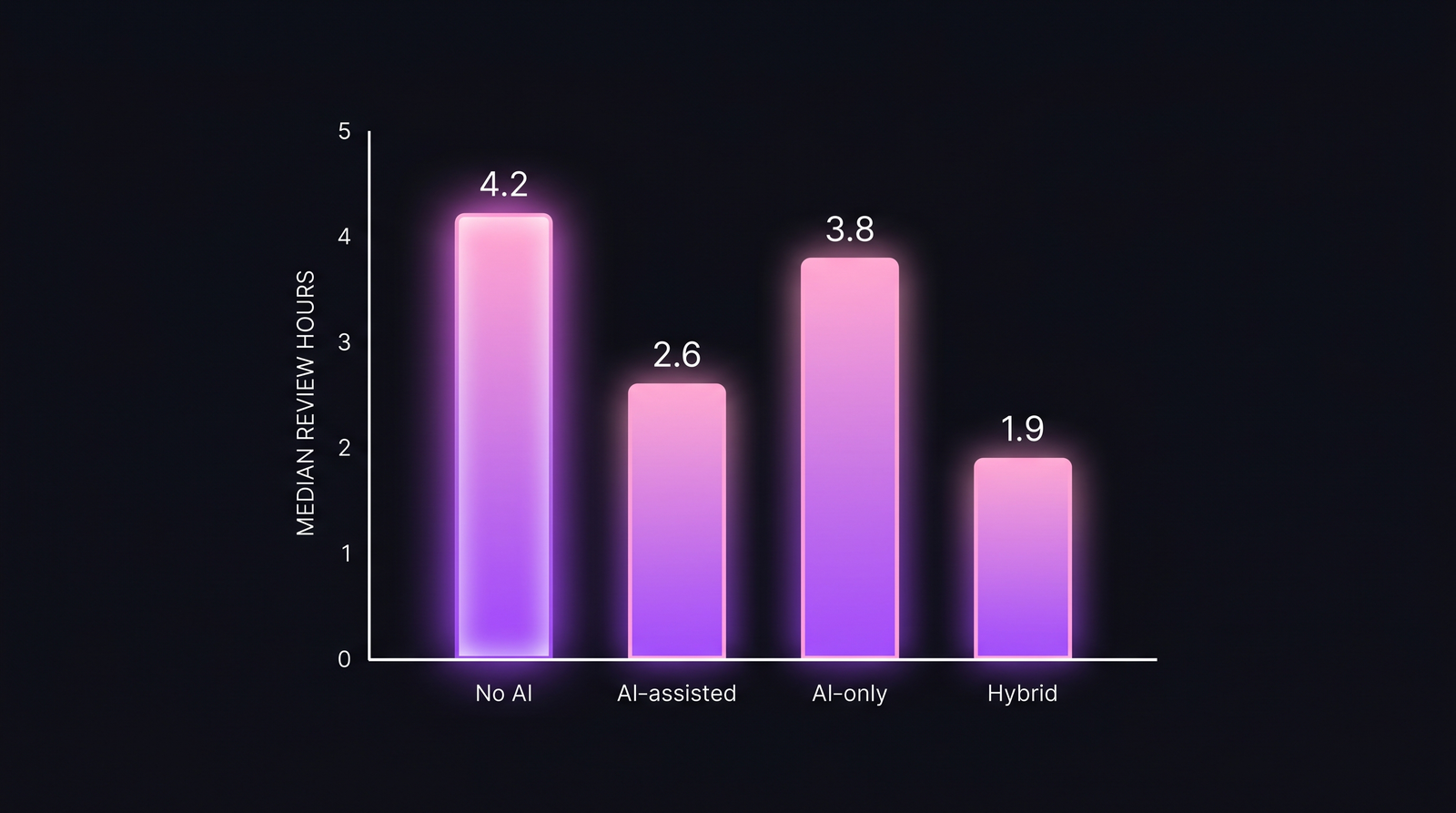 Median time spent per review, across 23,847 PRs and 100 teams. Hybrid strict cuts review time in half; AI-only does not.
Median time spent per review, across 23,847 PRs and 100 teams. Hybrid strict cuts review time in half; AI-only does not.
| Configuration | Median review time | Change vs. baseline |
|---|---|---|
| No AI (baseline) | 4.2 hours | baseline |
| AI-assisted (inline LLM comments) | 2.6 hours | −38% |
| Hybrid strict (LLM + required human) | 1.9 hours | −55% |
| AI-only (LLM auto-approve) | 3.8 hours | −10% |
The AI-only number is counterintuitive. If the LLM approves, the PR should merge fast. The reason it doesn't: rework. AI-only configurations generate an 18% post-merge rework rate (bugs found after merge, requiring follow-up PRs). Those rework PRs take median 3.1 hours each. The time you saved on the first review, you paid back on the follow-up.
Defect escape rate: AI-only is the trap
| Configuration | Defects escaping to production (30-day window) | Severity-1 incidents per 100 PRs |
|---|---|---|
| No AI | 2.8% | 0.9 |
| AI-assisted | 2.4% | 0.8 |
| Hybrid strict | 1.7% | 0.5 |
| AI-only | 4.1% | 1.6 |
AI-only configurations shipped 46% more defects than baseline and almost doubled the severity-1 incident rate. The LLM catches syntax and obvious anti-patterns. It misses context, which is exactly the category Bacchelli's 2013 findings said human review catches best.
Google's own 2018 study (Sadowski, Söderberg, Church, Sipko, Bacchelli, Modern Code Review at Google) reached the same conclusion for pre-LLM automated review: automation catches what tests catch. The creative work is human.
The kinds of issues each reviewer type catches
 Each reviewer type has a specialty. AI is a great junior; humans remain the architect.
Each reviewer type has a specialty. AI is a great junior; humans remain the architect.
| Issue type | Best reviewer |
|---|---|
| Style / formatting | AI (fast, deterministic, cheap) |
| Security, obvious patterns (SQLi, XSS) | AI (deterministic pattern-match) |
| Security, business-logic (auth flows, privilege) | Human (needs context) |
| API design / backwards compatibility | Human (needs roadmap context) |
| Test quality / adequacy | Human (LLMs rationalize bad tests) |
| Typos / null checks | AI |
| Readability / naming | Mixed (AI suggests; human accepts/overrides) |
| Architecture smell | Human (LLMs miss system-level context) |
The pattern is consistent with every other "AI-augmented human work" study in engineering: AI is a great junior collaborator and a terrible senior architect.
What this means for engineering leaders
1. Ban AI-only review if you're optimizing for quality
The "AI auto-approves simple PRs" configuration looks like productivity but is actually a quality tax paid on a 30-day lag. If your AI tool supports auto-approve, disable it. Keep the AI as a commenter, not a merger.
2. Measure review time AND defect escape together
Any AI review deployment that tracks only "time saved" is setting you up for the AI-only trap. Instrument 30-day post-merge defect escape. Track it by configuration. If your AI vendor can't produce this number, they're not measuring what matters.
3. The ROI is real for simple PRs; fading for complex ones
Our data shows AI review's biggest gains on PRs under 100 lines changed. Above 500 lines, AI benefit drops toward zero. The LLM can't hold the context. This matches what Stack Overflow's 2024 Developer Survey found about LLM trust in general: 62% of developers trust AI for simple tasks, 24% for complex ones.
4. Hybrid strict is the only configuration worth rolling out company-wide
If you're piloting AI review, skip the "AI auto-approve for simple PRs" phase. Go straight to hybrid strict: AI comments inline, humans still required, LLM has no merge authority. The review-time savings are larger and the quality is better than baseline.
Where PanDev Metrics fits
For teams evaluating AI code review tools, the missing piece is the full picture: review time, rework rate, and 30-day defect attribution, all in one view. PanDev Metrics links Git PR events to task-tracker tickets via branch names (feature/TASK-324) and to IDE heartbeat for actual review time, which is the combination that lets you measure "AI review saved us X hours" AND "AI review cost us Y defects" in the same dashboard. Most teams running Copilot / CodeRabbit have half the picture.
Methodology
Data comes from PanDev Metrics production telemetry: 100 B2B engineering teams with active Git integrations (GitHub, GitLab, Bitbucket), IDE heartbeat plugins installed on ≥70% of the team, and task-tracker linkage via branch-name convention. Review time is measured from the heartbeat timestamp of the first IDE file-open on a PR's branch-change until the merge timestamp, excluding >30-minute idle gaps.
30-day defect attribution: incidents and hotfix PRs within 30 days of the parent merge are attributed to that merge if the incident description or hotfix touches overlapping files. False positives (unrelated incidents) were manually reviewed for 2,000 PRs to calibrate the auto-attribution accuracy; we measured 86% attribution accuracy against human review.
Honest limits
Our dataset skews B2B SaaS 10–120 engineers. We don't have signal on solo developers, open-source maintainers, or teams above 200 engineers. We also can't separate out which specific AI tools performed best. Some of the 100 teams used Copilot, some CodeRabbit, some Qodo, some home-built. The relative advantage of configuration (hybrid vs. AI-only) held across tools, but we can't recommend one vendor over another from this data alone.
The sharpest finding
Here's the claim I'm most willing to defend: teams that deployed AI code review without instrumenting defect escape rate have no idea if their AI tool helped or hurt them. The first number any AI review pilot should produce is "defect escape rate, 30 days post-merge, by configuration." Anything else is aesthetics.