AI Interview Prep for Engineers: How Candidates Actually Cheat

A senior backend candidate I interviewed in March 2026 for a 40-person scaleup submitted a 4-hour take-home that was obviously AI-generated within 30 seconds of reading it. Not because the code was bad — the code was too good: consistent style across 14 files, docstrings on every function, and a suspiciously well-structured README covering edge cases the problem didn't require. What actually gave it away: a variable named is_applicable_within_business_context — the exact phrasing Claude 3.7 Sonnet uses when asked to write "enterprise-grade" code.
We hired someone else. Two months later, the same candidate's LinkedIn showed a new job at a competitor who didn't check. I don't know whether they passed the on-the-job bar; the industry tells stories both ways. What's certain: AI-assisted cheating is now the default, not the outlier, and hiring funnels designed pre-2024 select for the wrong thing. A 2024 Stack Overflow developer survey found 76% of professional engineers actively use AI coding tools; candidate tooling lags developer tooling by weeks, not years.
{/* truncate */}
How candidates actually cheat (2026 reality)
There are five common playbooks. Knowing them is how you design around them.
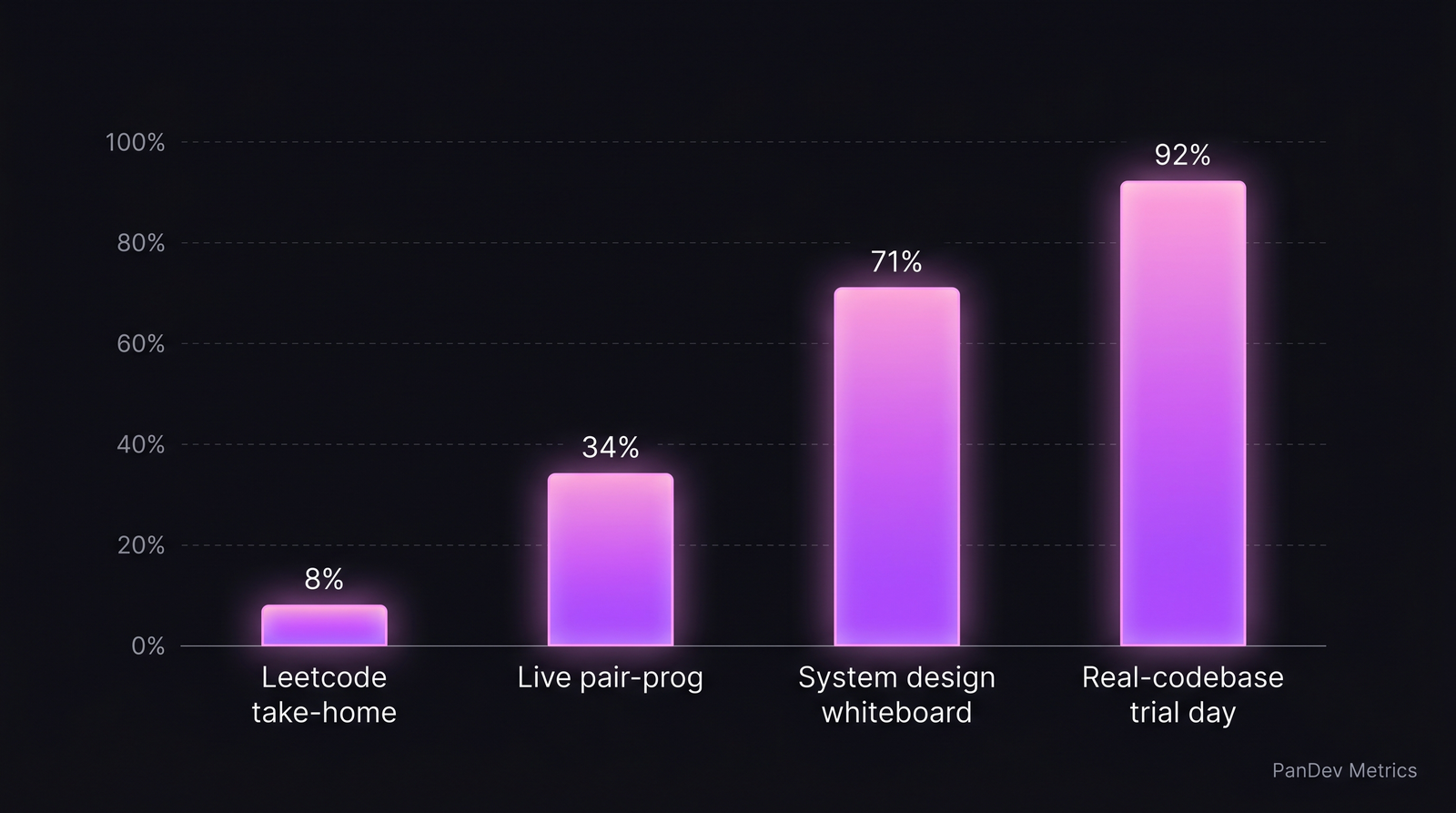 Signal-to-cheat ratio across interview formats. Take-homes are the worst; real-codebase trial days the best.
Signal-to-cheat ratio across interview formats. Take-homes are the worst; real-codebase trial days the best.
Playbook 1 — Take-home with Claude/GPT in the other tab
The default for 2025-2026 candidates. The candidate pastes your problem into Claude 3.7 Sonnet, GPT-5, or Gemini 2.5 Pro and gets 70-90% of a working solution within 5 minutes. Remaining 10-30% is taste — variable naming, test structure, README hygiene.
Signal corruption: near-total. You cannot distinguish a strong engineer's take-home from a weak engineer with a good LLM.
Playbook 2 — Live pair programming with a hidden LLM
Shared screen, candidate types, candidate has a second machine running Claude Code or Cursor off-screen. Questions get typed into the LLM on device B; candidate reads the answer, types a slightly-modified version in device A.
Tell: unnatural pause-type rhythm. Real engineers think-while-typing; LLM-reading engineers stop-read-type in 8-12 second bursts. Hard to spot on one session; visible on three.
Playbook 3 — System design with Claude as a co-thinker
Candidate uses voice-to-text on a phone, asks Claude "draw a rate-limiter with Redis for 100K RPS" live, reads back the output. If the interviewer probes with "why Redis over X?", the candidate has time to query Claude for the tradeoff.
Tell: candidate's answer is comprehensive on the "normal" answer but collapses on operational questions like "what would you monitor?" or "what breaks first at 2M RPS?" — LLMs answer these generically; real engineers answer them specifically.
Playbook 4 — Whole-persona generated résumé
LinkedIn optimization with AI, custom-written cover letters, GitHub profile with "impressive" side projects that were 90% generated. Doesn't cheat the interview per se — gets them into the interview.
Signal corruption: funnel widens with lower-quality candidates. Interview process must absorb the volume.
Playbook 5 — "AI-fluent" honest candidates (not cheating, but confusing)
Many strong engineers now use Cursor, Copilot, or Claude Code as their daily driver. Their solo output with these tools is better than their solo output without. Asking them to interview "without AI" measures something different from their actual job performance.
Signal confusion: a "no AI" interview rejects strong AI-fluent engineers who are legitimately 2-3x more productive with tooling. This isn't cheating — but it's the same measurement problem.
The signal-to-cheat ratio, by format
| Interview format | Still gives real signal in 2026? | Why |
|---|---|---|
| Take-home coding | Very weak | Claude solves it in 10 minutes |
| Multi-hour Leetcode | Weak | Same |
| Live coding (screen-share) | Medium | Some LLM-reading detectable |
| System design whiteboard | Strong | Operational probes break cheating |
| Real-codebase trial day | Very strong | Can't fake 6 hours of real-system work |
| Past-work deep dive | Strong | Follow-up probes reveal depth |
| Reference checks (2+ calls) | Strong | Behavioral signal |
The hiring funnel that works in 2026
1. Let candidates use AI — but watch how they use it
Stop running interviews that pretend AI doesn't exist. Tell the candidate: "Use any tools you'd use at work, including Cursor, Claude Code, Copilot, ChatGPT. We care about how you use them, not whether."
Then watch for:
- Do they verify the AI's output, or just paste and run?
- Do they steer the AI toward your specific problem, or ask generically?
- Can they explain the code the AI wrote back to you, in their own words?
- Do they catch the AI's hallucinations?
Strong AI-fluent engineers do all four. Cheats break on the last one — ask "why does this line exist?" and the cheater pauses too long.
2. Replace take-homes with paid trial days
A 6-8 hour paid trial day on a sanitized real-codebase branch is the single highest-signal interview format we've seen. The candidate:
- Checks out a real-ish task from the team's backlog
- Works for the day with whatever tools they want
- Pairs with an engineer for the last hour to explain decisions
Cheating here is near-impossible. The complexity and ambiguity of real-system work exceeds what an LLM can one-shot.
Downside: expensive. Limit trial days to final-round candidates (top 3-5 in the funnel).
3. System design with operational probes
Keep system-design interviews — but probe deeper:
- "How does this fail at 10x load?"
- "What does the on-call runbook look like?"
- "What's the cost of this architecture at current scale vs 5x scale?"
- "What would the migration look like from your current state to this design?"
These questions require operating experience, which LLMs don't have. An engineer who has actually run production systems answers them with texture; one relying on LLM help gives patterns without specifics.
4. Past-work deep dive with follow-ups
Ask the candidate to walk through a system they built. Then ask:
- "What was the hardest bug you shipped to production on this?"
- "If you rebuilt this today, what would you change?"
- "What did you argue against internally that shipped anyway?"
Follow-ups test memory, context, and opinion. LLMs can generate a plausible answer to "describe a system"; they can't make up the 6-month history of a real project.
The interview scorecard for 2026
Rescore candidates on these four dimensions, not just "correct solution":
| Dimension | What you're measuring | Signal weight |
|---|---|---|
| AI-fluent verification | Caught LLM mistakes, verified output | 25% |
| Problem decomposition | Broke ambiguous problem into tractable parts | 25% |
| Operational depth | Answered "what breaks at scale" concretely | 20% |
| Communication under pressure | Explained reasoning when probed | 20% |
| Code correctness | Working solution | 10% |
Note the weight inversion: correctness is now 10%, not 60%. Correctness is cheap in 2026 (LLMs produce it). Verification, decomposition, and operational depth are still expensive.
How the on-the-job data corroborates
PanDev Metrics captures IDE heartbeat data segmented by editor and tool. What we see in 2026 customer data:
- Engineers using Cursor + Claude Code code 65% more hours on task per week than VS Code-only engineers doing equivalent work (see our AI copilot effect analysis)
- Of those, the top-quartile (verified via manager rating) show 3-4x the rate of "reverted commit" patterns — not because they're worse, but because they iterate faster and revert early mistakes faster
- Engineers who don't use AI tooling show stable output but 30-40% fewer PRs opened per week
A hiring funnel that rejects AI fluency is selecting for the 30-40% lower-PR profile. Some teams want that. Most don't.
Common mistakes to avoid
- "Ban AI during interviews." This filters out 76% of professional engineers and measures skills they don't use on the job.
- "Trust the take-home." Unsupervised take-homes are dead as a signal. Use them only for screening, not final assessment.
- "Screen for AI prompt skills specifically." Prompt engineering is a real skill but not a proxy for engineering judgment. Don't over-weight it.
- "Panic-rewrite the whole process." Replace take-homes with trial days + operational system-design probes. Don't throw out reference checks and past-work dives — they still work.
- "Measure interview performance only on final-round signal." Track hired-candidate 90-day review scores against interview scores. You'll find which dimensions predict the on-job outcome — and which were noise.
The contrarian claim
AI doesn't make hiring harder — it makes lazy hiring obsolete. Teams that designed their funnel around "can you solve Leetcode?" were always measuring a weak proxy for "can you build systems?" Claude can now solve Leetcode. The teams who've been measuring the right thing all along — operational depth, systems thinking, code-in-context reasoning — had fewer dimensions to rethink. The shift is forcing hiring committees to do what they should've been doing in 2019.
Honest limits
Our data is strongest on what engineers do after hiring — IDE time, Git patterns, incident response. We don't directly measure interview quality, so the signal-to-cheat ratios in the table above come from customer interviews and a review of published engineering-blog practices (Stripe, GitLab, Doist, Shopify). These are directional, not precise. Your mileage varies based on role seniority, comp level, and candidate pool.
Also: the "cheating" framing is adversarial, but most candidates using AI aren't trying to deceive. They're using tools they'd use on the job. The playbook above treats both groups the same way — measure reasoning, not raw output.
Related reading
- Cursor Users Code 65% More Than VS Code Users: AI Copilot Impact — the on-the-job data behind the AI-fluency argument
- Performance Reviews Based on Data: Templates and Anti-Patterns — the evaluation side of the same problem (post-hire)
- Claude vs ChatGPT vs Copilot 2026 — which tools candidates actually use
- External: Stack Overflow Developer Survey 2024 — AI tools — adoption baseline for AI coding tools