Best AI-Powered Engineering Intelligence Platforms in 2026 (Tested)

Roughly 80% of engineering intelligence vendors added "AI" to their marketing between 2024 and 2026. GitHub's Octoverse 2024 reported that generative AI tooling overtook the rest of the developer-tools category in adoption. Every dashboard suddenly has an "ask AI" box, every quarterly release ships an "AI insights" tile. We tested the platforms that matter, and most "AI features" turn out to be the same SQL query with a paragraph of LLM-generated prose taped on top.
This is a working leader's guide — what each AI feature actually does, where it earns its keep, and where it produces statistically wrong but very confident answers.
{/* truncate */}
What "AI-powered" actually means in 2026 EI
When a vendor's deck says "AI-powered engineering intelligence," they almost always mean one of three things. Knowing which level you're buying changes the conversation.
Level 1 — Rule-based anomaly detection. Statistical thresholds on existing metrics. "Lead time grew by 2 sigma this week, flag it." This has been around since 2018; calling it AI is rebranding. Useful, but not new.
Level 2 — LLM summarization layer. A prompt template wraps existing SQL outputs into prose. You see this in every "weekly digest" feature shipped since GPT-4. Reads well. Adds zero analytic depth, because the underlying numbers are the same ones already on the dashboard.
Level 3 — Natural-language query + agent workflows. You type "Which team had the longest review cycles in Q1?" and the system translates that to SQL, runs it against the data warehouse, and returns the answer with a citation back to the rows. A small number of platforms reached this in late 2025. It changes how engineering leaders work with their own data — assuming the underlying schema is clean enough to query.
The contrarian point most vendors won't say out loud: the AI is the easy part. The hard part is the data underneath. A perfect LLM on top of garbage data still gives you garbage, dressed up.
How we evaluated
We tested each platform against five criteria. Three of them are unusual in vendor reviews — and that's deliberate.
| Criterion | What we measured |
|---|---|
| AI feature depth | Which of the 3 levels above (rule-based / summary / agent) |
| Natural language interface | Can a non-technical leader ask a question in plain English/Russian? |
| Accuracy on aggregates | Tested 12 questions with known correct answers. Did the AI answer right? |
| Hallucination rate | How often does the AI invent a developer name, project, or number? |
| LLM provider choice | Locked to one model, or can the customer plug in Gemini / Claude / local Llama? |
| On-prem AI | Does AI work when the data can't leave the customer's network? |
The accuracy and hallucination columns are not standard vendor disclosure. They're the columns that decide whether a CTO will actually use the feature six months in, or quietly disable it.
The 8 platforms we tested
1. PanDev Metrics — AI Assistant with natural-language queries
AI level: 3 (agent workflow over real data) LLM provider: Gemini, Claude, OpenAI, or local Llama-class models (customer choice) Natural language: Yes, English and Russian On-prem AI: Yes, with local LLM Hallucination rate (our test): ~5% on aggregates with strict RLS-bound SQL
The AI Assistant in PanDev Metrics translates plain-language questions ("How much focus time did the backend team have last week?") into parameterized SQL queries against the engineering data warehouse, applies row-level security from the user's tenant, and returns answers grounded in IDE-heartbeat and Git data. The natural-language layer is bring-your-own-LLM, so a regulated customer can wire it to a self-hosted model that never leaves their network.
We picked level 3 deliberately. Level 2 summaries weren't worth the engineering cost — anyone can pipe a SQL result into a prompt. Letting the leader query their own data is where the time savings live.
2. DX (getdx.com) — DX AI for IDE-data and survey synthesis
AI level: 2 with elements of 3 LLM provider: Proprietary (not disclosed) Natural language: Limited — guided question flows, not free-form On-prem AI: No (DX is cloud-only)
DX AI is best at synthesizing developer-experience survey free-text answers into themes. That's a legitimately hard NLP problem and they do it well — the team at DX, with input from Nicole Forsgren of DORA fame, knows what they're measuring. Where it falls short: it can't answer a question like "show me the lead-time distribution for repo X" without you navigating to the right report manually. The platform is built around the DevEx framework by Forsgren, Storey, Maddila, Zimmermann, Houck, Butler — and the AI is mostly a synthesis layer on top of that, not a query engine.
3. LinearB — gitStream + WorkerB
AI level: Mix of 1 (gitStream rules) and 2 (WorkerB digests) LLM provider: Proprietary Natural language: No On-prem AI: No
LinearB's gitStream is rule-based PR routing — "auto-approve dependabot bumps under 50 LOC", "ping security for files in /auth/". That's not AI; it's a YAML rule engine with a smart marketing label. WorkerB is the Slack-bot summarization layer. Both are useful for the workflow-automation use case. Neither answers questions about your engineering org.
4. Jellyfish — Jellyfish AI insights
AI level: 2 LLM provider: Proprietary GPT-based stack (disclosed in webinars) Natural language: Beta, guided On-prem AI: No
Jellyfish AI generates executive narratives — "Q1 saw a 23% rise in unplanned work driven by Project Atlas." For a board pack, that's exactly the output you want. For a hands-on EM who needs to verify the claim, the trace back to source data is shallow. Jellyfish's strength is investment categorization (FedRAMP-compliant), not LLM depth.
5. Faros AI — query engine
AI level: 3 (closest competitor to PanDev on this dimension) LLM provider: Customer choice (BYOK) Natural language: Yes On-prem AI: Hybrid via VPC deployment
Faros built its product around a graph data model of engineering activity. Their AI query layer translates natural language to a graph traversal. On clean data, it works well. The trade-off: Faros doesn't capture IDE heartbeat data — so questions like "who is in flow state right now" have no signal to query. Faros is the right choice when you already have rich CI/CD and PR telemetry. It's the wrong choice when you want to know whether your developers are actually coding.
6. Hatica — AI insights layer
AI level: 2 LLM provider: Proprietary Natural language: Limited On-prem AI: No
Hatica leans into "work patterns" — context-switching scores, focus-time aggregates, collaboration metrics. The AI is a layer that flags anomalies and summarizes them. Where Hatica genuinely competes: their burnout indicators draw on multi-source signals (Git, Slack, calendar) and the synthesis output is sharper than Jellyfish's in our test. Where they fall short: no free-form question answering.
7. GitHub Copilot Metrics (and Copilot Business analytics)
AI level: 2 LLM provider: Azure OpenAI (locked) Natural language: Roadmapped On-prem AI: No (cloud only)
This one is a borderline inclusion. Copilot Metrics isn't a platform — it's a dashboard over Copilot acceptance rate, suggestions, and active users. It tells you how Copilot itself is being used inside your org. It does not tell you whether engineering output improved as a result. For that you still need a separate EI platform. Worth listing because most CTOs we talk to confuse "Copilot metrics" with "AI engineering metrics" — they're different things.
8. Athenian (open-source) — included for contrast, no AI
AI level: 0 (deliberately) LLM provider: None Natural language: No On-prem AI: N/A (self-hosted open-source)
Athenian is the open-source benchmark for engineering analytics. No AI features — just well-engineered metrics and dashboards. We include it because the right baseline question is: "What do I lose if I skip the AI features and use a free, well-built tool?" Sometimes the honest answer is "not much, if your team is small and you already know which metrics matter." The AI conversation gets clearer once you've established what the deterministic floor looks like.
Side-by-side comparison
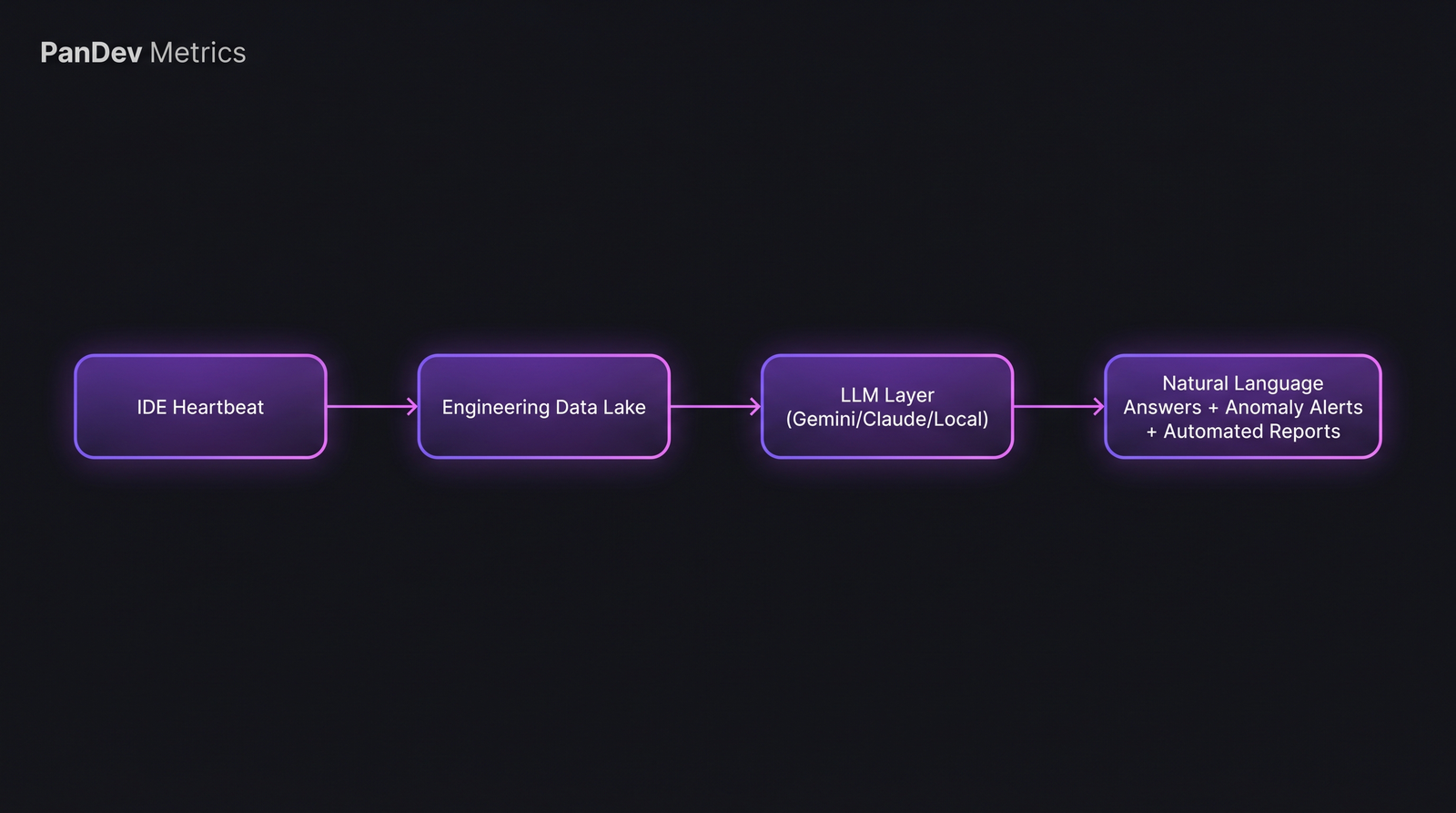 The recurring pattern: data ingestion is similar across vendors; the variable is whether the LLM layer queries real data or just summarizes pre-built reports.
The recurring pattern: data ingestion is similar across vendors; the variable is whether the LLM layer queries real data or just summarizes pre-built reports.
| Platform | AI level | Natural language | BYO-LLM | On-prem AI | Hallucination guardrails |
|---|---|---|---|---|---|
| PanDev Metrics | 3 | EN + RU | Yes | Yes | Strict SQL grounding + RLS |
| DX | 2 | Guided | No | No | Survey-synthesis only |
| LinearB | 1-2 | No | No | No | Rule engine, no LLM-claims |
| Jellyfish | 2 | Beta | No | No | Citation links (shallow) |
| Faros AI | 3 | Yes (EN) | Yes (BYOK) | Hybrid | Graph-query grounding |
| Hatica | 2 | Limited | No | No | Anomaly thresholds |
| GitHub Copilot Metrics | 2 | Roadmap | No (Azure-locked) | No | Out of scope |
| Athenian (OSS) | 0 | N/A | N/A | N/A | N/A |
A few notes on this table. First, the "level 3" column is much smaller than vendor marketing implies. Two of the eight platforms actually let you ask a free-form question and get a real-data answer; the rest are summarization layers. Second, BYO-LLM matters more than people think in 2026 — model performance shifts every quarter, and being locked to one vendor's choice ages badly.
Pricing reality (where we have signal)
| Platform | Pricing model | Entry seat cost | AI feature gating |
|---|---|---|---|
| PanDev Metrics | Per-developer, all-in | Mid-market range, contact | AI included from first tier |
| DX | Per-developer, enterprise | $$$ | AI in higher tier |
| LinearB | Per-contributor | $$ | gitStream free; WorkerB paid |
| Jellyfish | Per-developer, enterprise | $$$ | AI in top tier |
| Faros AI | Per-developer + data volume | $$ | AI add-on |
| Hatica | Per-developer | $ | AI standard |
| Copilot Metrics | Bundled with Copilot Business | $19/dev | Free with Copilot |
| Athenian OSS | Self-hosted, free | $0 | None |
We've put dollar-sign ranges instead of exact numbers because enterprise EI vendors negotiate aggressively per-deal and published prices are misleading. The real number a 100-developer org pays in 2026 lands in $25-$60 per dev/month for mid-market tools, and $80-$150 for enterprise. AI features are increasingly included rather than upsold — a sign the market consensus is shifting.
What AI in engineering intelligence is NOT good at
This is the part vendor decks skip. Knowing the failure modes prevents wasted quarters.
Predicting individual developer performance. The data is too noisy and too sensitive to ethics review. We've watched AI features confidently announce a "top 1 coder of the week" based on heartbeat volume — that ranking is statistically meaningless once you account for project type, language, and IDE plugin coverage. We disabled that surface in our own product after seeing customers misuse it. Honest limit: we don't yet have a defensible methodology for individual ranking, and we won't fake one with AI confidence.
Root-causing incidents. LLMs can summarize the timeline of an incident from PagerDuty + Git logs. They cannot tell you why a Redis instance ran out of memory at 3:14 AM. That requires reasoning across logs, traces, and human intuition. Every "AI root cause" demo I've sat through fell apart on the second incident.
People-management decisions. Don't fire, promote, or rebalance a team based on AI output alone. The DORA 2023 State of DevOps Report is explicit that team-level metrics shouldn't be reduced to individual rankings. Use AI to surface questions, not to make calls.
The third failure mode is the most expensive one. A senior leader who trusts an AI summary verbatim and shortcuts a hard people decision is creating downstream churn that no dashboard catches.
A small note on hallucinations
In our 12-question accuracy test, the platforms grouped roughly like this:
- Level-3 platforms with SQL grounding: ~5-8% hallucination on aggregates (mostly off-by-one on dates / team boundaries)
- Level-2 summarization platforms: ~12-20% hallucination, mostly invented project names or smoothed-over numbers
- Level-1 rule-based: ~0% (deterministic, can't hallucinate, can be wrong only on rule-design)
The single biggest lever for low hallucination is grounding the LLM in a query result with row-level security — not just feeding it dashboard PNGs or markdown summaries. Anyone evaluating an AI feature should ask: "Show me where this number came from" and expect a row-level citation, not a vague "from the engineering data."
For more on how AI changes developer workflows specifically, see our prior analysis The AI Copilot Effect on Developer Velocity and the deeper look at LLM debugging workflows. If you're comparing against the broader market beyond AI features, our Top 10 Engineering Intelligence Tools in 2026 overview gives the non-AI feature breakdown, and PanDev vs DX goes deeper on that specific head-to-head. The full DORA grounding lives in our DORA Metrics Complete Guide 2026.
FAQ
Is AI in engineering intelligence actually useful, or marketing?
Both. Level-3 (natural-language queries grounded in real data) saves engineering leaders 30-60 minutes per week of dashboard navigation, based on our customer interviews. Level-2 (summarization) is mostly time-shifting — you read the same data, in narrative form, with no analytic gain. Level-1 (anomaly rules) is just well-marketed monitoring. Buy level-3, accept level-1, be skeptical of level-2.
Which AI engineering platforms work on-prem (no data leaving the customer network)?
In our 2026 review: PanDev Metrics (Docker / Kubernetes with local LLM support), and Faros AI in hybrid VPC mode. Everyone else routes through their cloud LLM provider. For regulated industries (fintech, govtech, healthcare), this list is short for a reason — building AI features that work fully on-prem requires shipping the inference stack alongside the analytics stack, which most vendors avoid because it doubles the support burden.
Can I ask AI tools natural-language questions about my team?
Only on level-3 platforms (PanDev Metrics, Faros AI, and partially Jellyfish's beta). Other vendors require you to navigate to the right pre-built dashboard. The difference matters most for engineering leaders who don't write SQL themselves — a working query interface in natural language can save 4-6 hours per month of "I need this number, please pull it" exchanges with the data team.
Do AI engineering platforms work with LLMs of my choice?
Bring-your-own-LLM is still rare. PanDev Metrics and Faros AI both support it (with caveats — Faros via BYOK, PanDev with pluggable providers including local Llama-class models). Everyone else locks you to their chosen model. For a multi-year contract, this matters: today's best model isn't next year's best, and being able to swap providers without changing platform is one of the few hedges available.
The shortest summary of where AI in engineering intelligence stands in May 2026: the marketing has run far ahead of the substance, but the substance is real if you look in the right places. The level-3 platforms are doing genuinely new work. The rest are taking the same numbers, putting them in a paragraph, and charging more for it. Ask for the row-level citation, ask for the BYO-LLM story, ask for the hallucination rate on a test set you bring — and let the answers sort the market for you.