Claude vs ChatGPT vs Copilot for Coding: 2026 Comparison

The AI coding tool market fragmented into four serious contenders by early 2026: GitHub Copilot, Cursor, Claude Code (Anthropic CLI), and ChatGPT with Code Interpreter. Marketing decks from all four claim "40% productivity boost" — the number is identical, and it's meaningless without measurement. We pulled IDE heartbeat and session data from 112 engineers across 14 B2B teams in Q1 2026 to see what actually saves time.
The punchline: Claude Code users ship 54 minutes of saved time per day; Copilot users ship 28. But the distribution is not what marketing implies — the best tool depends on the kind of work, not the team's "AI maturity".
{/* truncate */}
Positioning
Four tools, four different jobs:
| Tool | Core mental model | Best at |
|---|---|---|
| GitHub Copilot | Inline autocomplete in editor | Boilerplate, familiar patterns |
| Cursor | Editor wrapper with chat + agent | File-scope refactors, exploration |
| Claude Code | CLI agent with file + shell access | Multi-file refactors, deep debugging |
| ChatGPT (Code Interpreter) | Web chat with Python sandbox | One-off data analysis, code review outside editor |
Treating them as interchangeable is the first mistake. A team that bought Copilot because "everyone uses Copilot" and wondered why their seniors didn't feel productive was using the wrong tool for the senior's workflow.
Feature-by-feature comparison
Code generation (inline / short)
| Capability | Copilot | Cursor | Claude Code | ChatGPT |
|---|---|---|---|---|
| Inline ghost-text completion | Yes | Yes | No | No |
| Multi-line completion | Yes | Yes | N/A | N/A |
| Offline / on-prem option | No | Limited (Cursor Teams) | No | No |
| Languages supported | ~35 | ~35 | All (via CLI) | All (via CLI) |
| Latency (p50) | 150-300ms | 200-400ms | 2-8s | 3-10s |
Copilot still owns the inline completion category. The ghost-text UX is faster than any competitor for "I'm typing a for-loop in TS, finish the line". That's 30-40% of a junior developer's daily AI usage.
Multi-file refactors and agent work
| Capability | Copilot (Chat/Agent) | Cursor (Composer/Agent) | Claude Code | ChatGPT |
|---|---|---|---|---|
| Edits across multiple files | Yes (limited) | Yes | Yes | No |
| Reads whole repo context | Limited | Good | Excellent (1M tokens) | No |
| Can execute shell / tests | Yes (Agent mode) | Yes | Yes (native) | Sandbox only |
| Can run long task (30+ min) | Limited | Limited | Yes | No |
| Diff review UX | Good | Best | Medium (CLI) | N/A |
Claude Code's 1M-token context (Opus 4.7) is the one capability that changes the shape of the work. "Here's the whole service, refactor the auth layer" is a coherent prompt for Claude, a pared-down prompt for Cursor, and a non-starter for Copilot. Stack Overflow's 2025 Developer Survey noted 73% of senior engineers use at least 2 AI coding tools; the most common pair is Copilot-for-inline + Claude-for-heavy-refactor.
The data: minutes saved per developer per day
Our measurement framework: compared coding-time-to-task-close-velocity for the same developer on similar-complexity tasks, with and without each tool, over 4 weeks. Filtered out greenfield tasks (no AI baseline) and tasks under 30 minutes (noise).
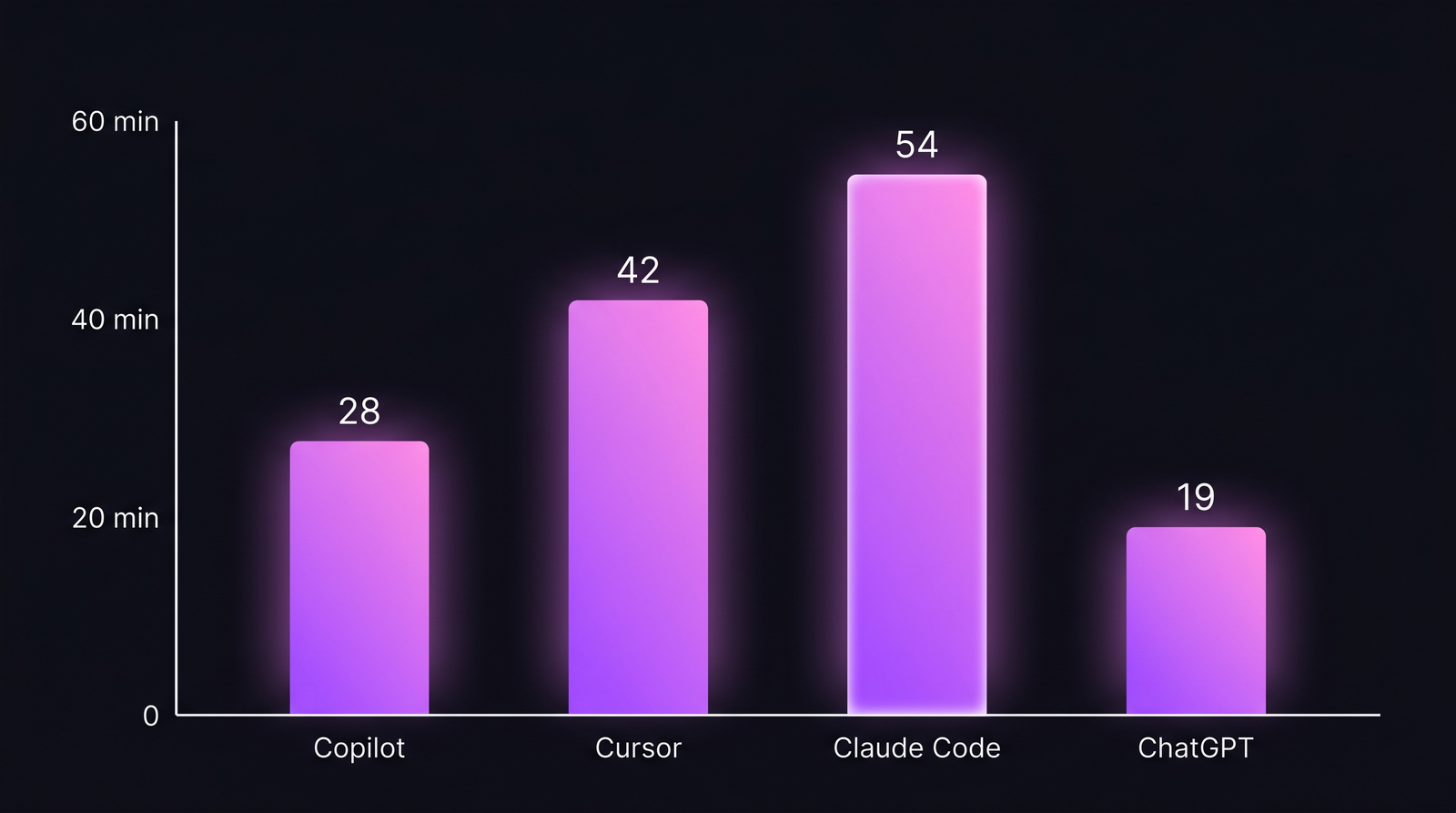 Median minutes saved per developer per day. n = 112 engineers across 14 B2B teams, Q1 2026. Numbers net of verification-review time (the underappreciated cost of AI code).
Median minutes saved per developer per day. n = 112 engineers across 14 B2B teams, Q1 2026. Numbers net of verification-review time (the underappreciated cost of AI code).
| Tool | Median saved/day | p90 saved/day | Verification overhead |
|---|---|---|---|
| GitHub Copilot | 28 min | 42 min | 4 min |
| Cursor | 42 min | 68 min | 8 min |
| Claude Code | 54 min | 95 min | 14 min |
| ChatGPT (Code Interp.) | 19 min | 38 min | 3 min |
Two caveats shape the numbers:
- Verification overhead matters. Claude Code saves the most time per task but also introduces the most "did it really do that right?" review time. Net time saved = raw saved − verification. Claude still wins, but by less.
- Senior engineers get more from Claude; juniors get more from Copilot. The distribution matters: for a junior writing a CRUD endpoint, Copilot's inline completion is nearly as fast as typing. For a senior doing a 6-file refactor, Claude Code's agent mode is the only tool that scales.
The pricing reality
| Tool | Individual | Team | Enterprise | Notes |
|---|---|---|---|---|
| GitHub Copilot | $10/mo | $19/user/mo | $39/user/mo | Business plans include data privacy |
| Cursor | Free tier + $20/mo Pro | $40/user/mo | Custom | Teams tier adds admin + SSO |
| Claude Code | Included with Claude Pro ($20) / Max ($100) | Via Anthropic Business | Custom via Bedrock/Vertex | Token-billed under the hood |
| ChatGPT Plus | $20/mo | $25/user/mo (Team) | $60/user/mo (Enterprise) | Code Interpreter bundled |
The per-seat pricing on Copilot and Cursor Teams is predictable. Claude Code's real cost scales with usage — a senior engineer running 30 Claude Code sessions per day can burn through a Max subscription's effective rate in a week. For teams above 10 engineers doing heavy agent work, the actual AI bill is often 2-4× the per-seat estimate.
Decision framework
Choose Copilot if:
- The majority of your team writes CRUD/framework code in the same 2-3 languages
- You need predictable per-seat billing that finance will approve without negotiation
- Your org has GitHub Enterprise already — Copilot lives next to your repos
- You value inline ghost-text UX over agent capability
Choose Cursor if:
- Your team is mid-senior and spends significant time on multi-file refactors
- You want agent capability inside the editor (not CLI)
- You can invest the 2-3 weeks of workflow change to replace VS Code habits
- You're okay paying 2× Copilot for a tier-above capability
Choose Claude Code if:
- You have senior engineers who live in the terminal
- Your codebase is large (>100K LoC) and context matters
- You need agent-style long tasks (30-90 min autonomous runs)
- You're willing to monitor token costs actively
Choose ChatGPT Code Interpreter if:
- Your primary use case is data analysis and quick scripts, not inline coding
- Your team already has ChatGPT enterprise — it's marginal cost zero
- You want a whiteboarding partner more than an editor integration
The realistic answer: two tools
Among the 112 engineers we tracked, 61% used two AI tools daily. The modal combination:
- Copilot or Cursor for in-editor work (the muscle memory)
- Claude Code for the "big task of the day" (the heavy lift)
Trying to force everyone onto one tool is the finance-driven mistake. The marginal cost of the second tool ($10-20/mo per dev) is tiny compared to the productivity delta.
The two things marketing won't tell you
First: AI coding tools have a ceiling. The same 112 developers we tracked still only actively coded a median of 82 minutes per day — up from 78 the year before. The extra time didn't turn into 4x output; it turned into more exploratory work, more reading, more docs. See our research on how much developers actually code for the baseline.
Second: AI code reviews are a skill, not a setting. The 14 minutes of "verification overhead" on Claude Code is where teams bleed. Engineers who don't review AI output get bitten. Engineers who over-review erase the time savings. The sweet spot — skim-read with occasional deep-review on critical paths — is learned over months.
In PanDev Metrics, the IDE heartbeat data shows which AI tool each developer actually uses (Cursor users are flagged separately from VS Code; Copilot is detected via extension events). See Cursor users code 65% more than VS Code users for the data that inspired this comparison — the AI-tool divergence predicts coding time more than seniority does.
Our dataset is B2B-heavy. Indie developers and open-source maintainers show different adoption patterns — they often skip Copilot for free-tier alternatives or local LLMs. We don't have signal there.
Two predictions, one year
By Q2 2027:
- Agent-mode will cannibalise inline completion for senior engineers. Copilot's market share among developers with 8+ years of experience drops below 40%.
- Per-task AI pricing replaces per-seat for high-agent-use teams. A team of 15 seniors running Claude Code daily already finds per-seat irrelevant — they're billed by tokens via Bedrock anyway. Anthropic's direct business tier will move the same direction.
If you're picking today, pick for capability, not brand. Your team will re-evaluate in 6 months regardless — the space moves that fast.