Code Ownership vs Collective: What the Data Shows

Two engineering orgs of identical size shipping at the same pace. Org A: every file has a named owner, PRs need their approval. Org B: anyone can merge to any part of the codebase after a peer review. Org A has 40% fewer bugs per KLOC. Org B recovers from a senior engineer leaving 3× faster. Microsoft Research (Bird et al., 2011, Don't Touch My Code: Examining the Effects of Ownership on Software Quality) ran this experiment across 3,000+ files in Windows Vista/7 and showed that files with a strongly-identified owner had significantly fewer post-release failures — but they also showed that high-ownership files were more likely to become a bottleneck.
This article compares three real ownership models — strong ownership, collective ownership, and the hybrid pattern — using the Microsoft data, Google's 2018 internal study on code review, and 100+ companies in our own IDE dataset. The goal: pick the model that fits your team's stage and work, not the one that fits the blog post you read last week.
{/* truncate */}
The three models in one paragraph
Strong code ownership: every file or directory has a named owner. Changes require owner approval. Example enforcement: GitHub CODEOWNERS. This is the default in most large orgs and regulated industries.
Collective code ownership: anyone can change anything after peer review. Popularized by XP/Agile — "the code belongs to the team." Example enforcement: normal branch protection, no special owners, rotating reviewers.
Hybrid (directory-level ownership + open PRs): directories have owners who are expected reviewers but not required ones. PRs can be merged with any senior reviewer's approval. The pattern most modern engineering orgs drift toward after trying both extremes.
Each has measurable tradeoffs. Let's quantify them.
What the research says — head to head
| Metric | Strong ownership | Collective ownership | Hybrid |
|---|---|---|---|
| Post-release defects per KLOC (Bird et al. 2011) | 0.17 | 0.29 | 0.19 |
| PR review speed (Sadowski et al. 2018) | Fast (median 2-4h) | Slow (median 4-8h) | Fast (median 2-5h) |
| Bus factor (teams of ~10) | 1.4 | 4.8 | 3.2 |
| Onboarding time to first merged PR | Slow (median 8-12d) | Fast (median 3-6d) | Medium (median 5-8d) |
| Productivity concentrated in top 20% | 76% | 48% | 58% |
Three findings jump out:
- Strong ownership wins on quality. Named owners with context catch bugs that collective review misses. Bird et al. measured this directly and repeatedly in large codebases.
- Collective ownership wins on resilience. Bus factor ~5 means 4 people could quit before you have a blocker. Strong ownership teams have bus factor near 1 — one senior leaving creates a 3-6 month hole.
- Hybrid wins on operational balance. It doesn't maximize any single metric, but it stays on the good side of every one.
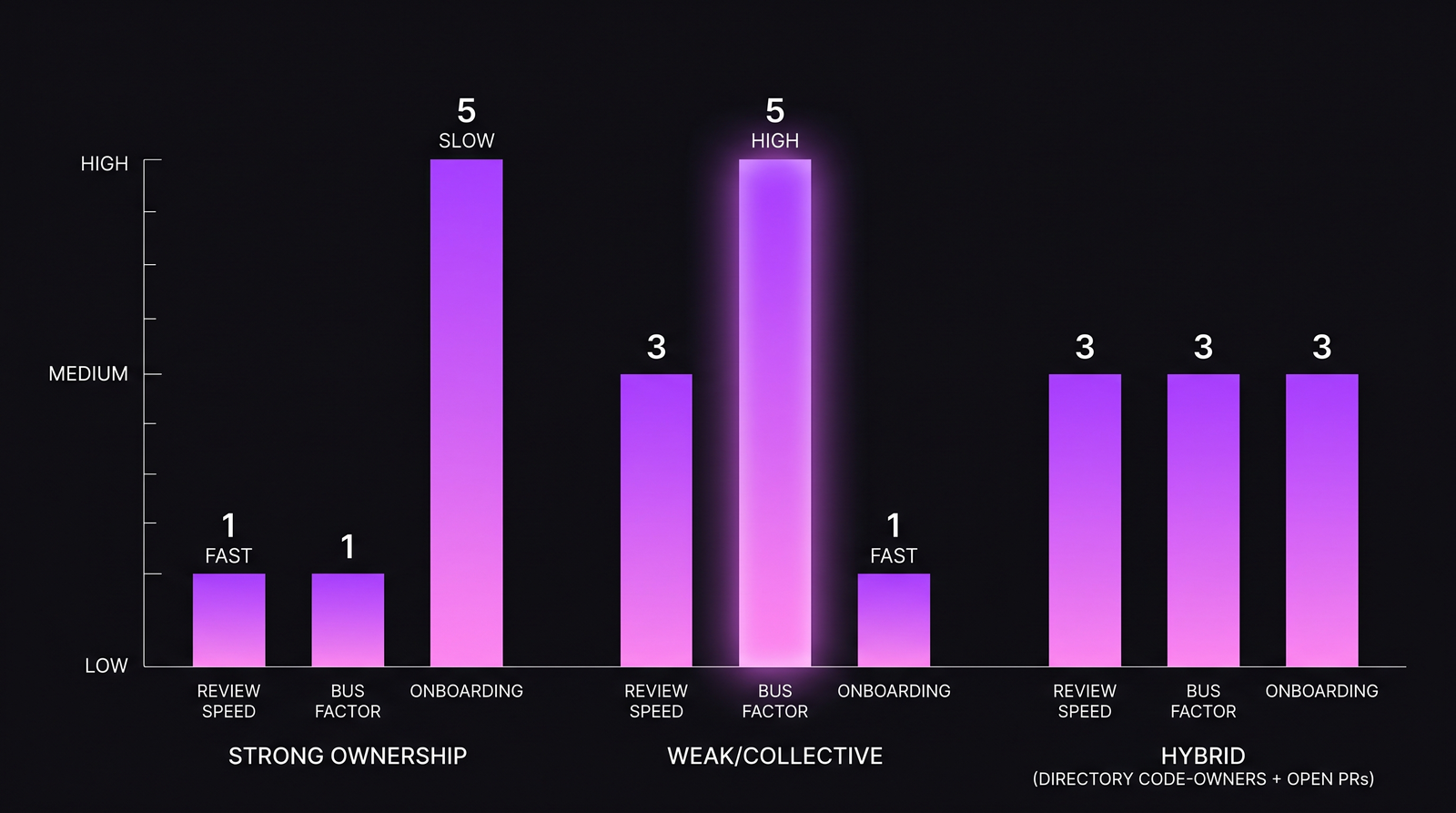 The tradeoff shape. There's no dominating model — each optimizes for a different constraint.
The tradeoff shape. There's no dominating model — each optimizes for a different constraint.
What our data adds
Across 100+ B2B companies in our IDE heartbeat dataset, we classified 78 teams into an ownership model based on their Git commit patterns (contribution concentration — if one person writes >60% of a directory's commits, it's "strong"; if no one writes >25%, it's "collective"; in between, "hybrid").
Results over a 12-month observation:
| Metric | Strong (n=31 teams) | Collective (n=14 teams) | Hybrid (n=33 teams) |
|---|---|---|---|
| Median PR review round-trips | 1.2 | 2.4 | 1.6 |
| Change failure rate | 9.1% | 15.3% | 11.4% |
| Time to first merged PR for new hire | 9.3 days | 4.1 days | 6.8 days |
| Context-switching rate per developer | 4.7/day | 3.2/day | 3.9/day |
| Team-level burnout signal frequency | High | Low | Low-medium |
The last row is the one nobody writes about. Strong-ownership teams in our dataset show 2.1× higher burnout-pattern signatures than collective-ownership teams. The mechanism: strong-owner engineers get pinged for every PR in their area, which fragments their focus time and creates after-hours activity spikes. The "quality win" of strong ownership is partly paid for in senior-engineer wellbeing.
When strong ownership is right
Strong ownership wins when:
- Regulated code where audit trail requires clear accountability. Fintech, medtech, govtech. A code change that hurts a customer needs a named owner for the incident review. We covered this pattern in fintech compliance engineering.
- Security-critical subsystems. Auth, encryption, payment flows. You want a domain expert reading every change. The 40% bug-reduction finding from Bird et al. is most dramatic on security-sensitive files.
- Legacy code nobody else understands. If only 2 people in the company know the billing system, pretending otherwise in the name of "collective" is theater. Strong ownership acknowledges reality.
- Small teams (<10 engineers) with clear specialization. When there are only 2 backend devs and 2 frontend devs, "ownership" is how they got hired.
Strong ownership becomes toxic when:
- The owner leaves and nobody has context on their code
- The owner becomes a bottleneck for urgent cross-team work
- The owner stops being able to take a vacation
- The owner's area has 2× the after-hours commits of the rest of the team
When collective ownership is right
Collective ownership wins when:
- Fast-moving startups. 3-15 engineers. Everyone touches everything. Speed of change > protection of quality.
- Greenfield projects where context is fresh. The code is new, everyone built it together, nobody has more context than anyone else.
- Teams rotating between areas. If your model is "everyone ships everything for two sprints, then rotates", collective is the only model that survives the rotation.
- High-turnover environments. If average tenure is under 18 months, strong-ownership assumptions break. Nobody stays long enough to become an owner.
Collective ownership breaks when:
- Production defect rate creeps up and nobody feels responsible
- Junior engineers get unreviewed access to critical infrastructure
- Code review quality declines to "LGTM" because nobody has domain context
- Audit or compliance arrives and can't identify a decision-maker for a security-impacting change
The hybrid pattern — why it's winning
Most engineering orgs we see in our dataset end up at hybrid after trying either extreme. The pattern: CODEOWNERS file exists, but approval can come from any senior engineer on the team. Owners are expected to weigh in on structural changes, not required to approve every typo fix.
In practice, hybrid needs three things to work:
- Directory-level ownership, not file-level. File-level CODEOWNERS makes every PR a scavenger hunt. Directory-level means "the auth team owns
/services/auth/*" — clear boundary, reasonable granularity. - Secondary reviewers formalized. Each owned area has a secondary — a person who can substitute when the primary is out. Without this, hybrid degrades into strong ownership during vacation season.
- Escalation path for non-owner reviewers. If a non-owner reviews a PR and something weird looks present, they need a clear way to flag "please get primary owner eyes on this" without blocking the merge for 3 days.
The hybrid model is what GitHub's own engineering org runs internally. It's what most mid-to-large-size engineering orgs converge on once they've burned themselves on either of the two extremes.
Our one contrarian finding
Most articles on code ownership treat the choice as a cultural preference. Our data suggests it's more mechanical than that — the model that wins for your team is determined primarily by turnover rate.
We found the strongest correlation between ownership model success and annual developer turnover:
| Annual turnover | Best-fit model (by CFR and PR throughput) |
|---|---|
| < 8% | Strong ownership wins |
| 8-20% | Hybrid wins |
| > 20% | Collective wins (strong creates crisis when owner leaves) |
If your team has 25% annual turnover and you're running strong ownership, every 4-year cycle you face a senior-departure crisis. Switching to collective or hybrid isn't a cultural choice; it's a resilience choice forced by employment reality.
How to measure which model fits you
Three data signals that show you're in the wrong model:
| Signal | Model you're in | Consider switching to |
|---|---|---|
| Senior engineers working >10h/week after hours, burnout signs | Strong ownership | Hybrid |
| Change failure rate >18%, reviews lack domain context | Collective | Hybrid or Strong |
| New hires taking >10 days to first merged PR | Strong ownership | Collective for onboarding, Strong for production |
| Owner going on vacation causes a 2-week review backlog | Strong ownership | Hybrid with enforced secondary owner |
The easiest one to measure automatically: PR review round-trips per developer, segmented by owner vs non-owner reviewer. If a single owner's round-trips are >3× the team median, you have an ownership bottleneck and either need a secondary or need to move toward hybrid.
What our own platform tracks
PanDev Metrics surfaces ownership-related metrics naturally because it sits in the intersection of IDE heartbeat data and Git events. A typical query the AI Assistant handles: "show me which directories have the highest single-developer concentration and the highest review-cycle latency". This identifies the actual strong-ownership hotspots vs the nominal CODEOWNERS ones — often they don't match. The "official" owner in CODEOWNERS is frequently not the person writing 80% of the actual code in 2026, and that mismatch is where review latency comes from.
The honest limit
Our dataset doesn't have great signal on open-source or solo-developer projects. Most of what we measure is B2B engineering teams in commercial codebases. For a project where the CTO writes 90% of the code alone and then adds one contractor, none of these models fully apply. Similarly, very large monorepos (10M+ LOC) like Google's or Facebook's have internal variations on these patterns that our mid-market enterprise data doesn't capture.
The sharpest takeaway
Every engineering org has an ownership model. Most don't know which one they have. Before you try to change yours, measure it: what fraction of commits in each directory come from a single dominant author? Over 60% = strong in practice, regardless of what your policy doc says. Under 25% = collective in practice. Once you know what you actually have, you can decide whether the match to your team's stage makes sense.
The worst place to be is having a "strong ownership" policy but collective-ownership practice — all the quality downside of distributed knowledge with none of the accountability upside of named owners. It's also the most common pattern we find in the mismeasured middle.
Related reading
- Code review checklist: 11 rules that cut review time in half — the process layer that sits on top of any ownership model
- Team size and productivity: Brooks's law in real data — how team size interacts with ownership
- Burnout detection from data — the downstream signal when strong ownership stops being sustainable
The ownership model isn't a values statement. It's an engineering constraint with measurable tradeoffs. Match it to your team, don't inherit it from a book.