Conflict Resolution in Engineering Teams: Data-Driven Approach

Two senior engineers at a 60-person SaaS I mentored stopped speaking for seven weeks. The cause, by their accounts, was "a personality clash." The cause, by the data: engineer A had merged without review into engineer B's service 23 times in 8 weeks; engineer B's review queue had grown from 4 PRs to 31 in the same window. Each had a legitimate grievance neither could cleanly articulate. The moment their EM put the two numbers on a slide, the fight ended — not because anyone won, but because the dispute stopped being about the other person's character.
Most conflict in engineering teams isn't about personalities. It's about process gaps, priority mismatches, and workload inequities that people can't see from inside the conflict. A 2022 Harvard Business Review study on team dysfunction placed "ambiguity about who owns what" as the #1 driver of interpersonal conflict on knowledge-work teams. The resolution isn't better feelings — it's a shared picture of reality. Data is how you build it.
{/* truncate */}
The four conflict types on engineering teams
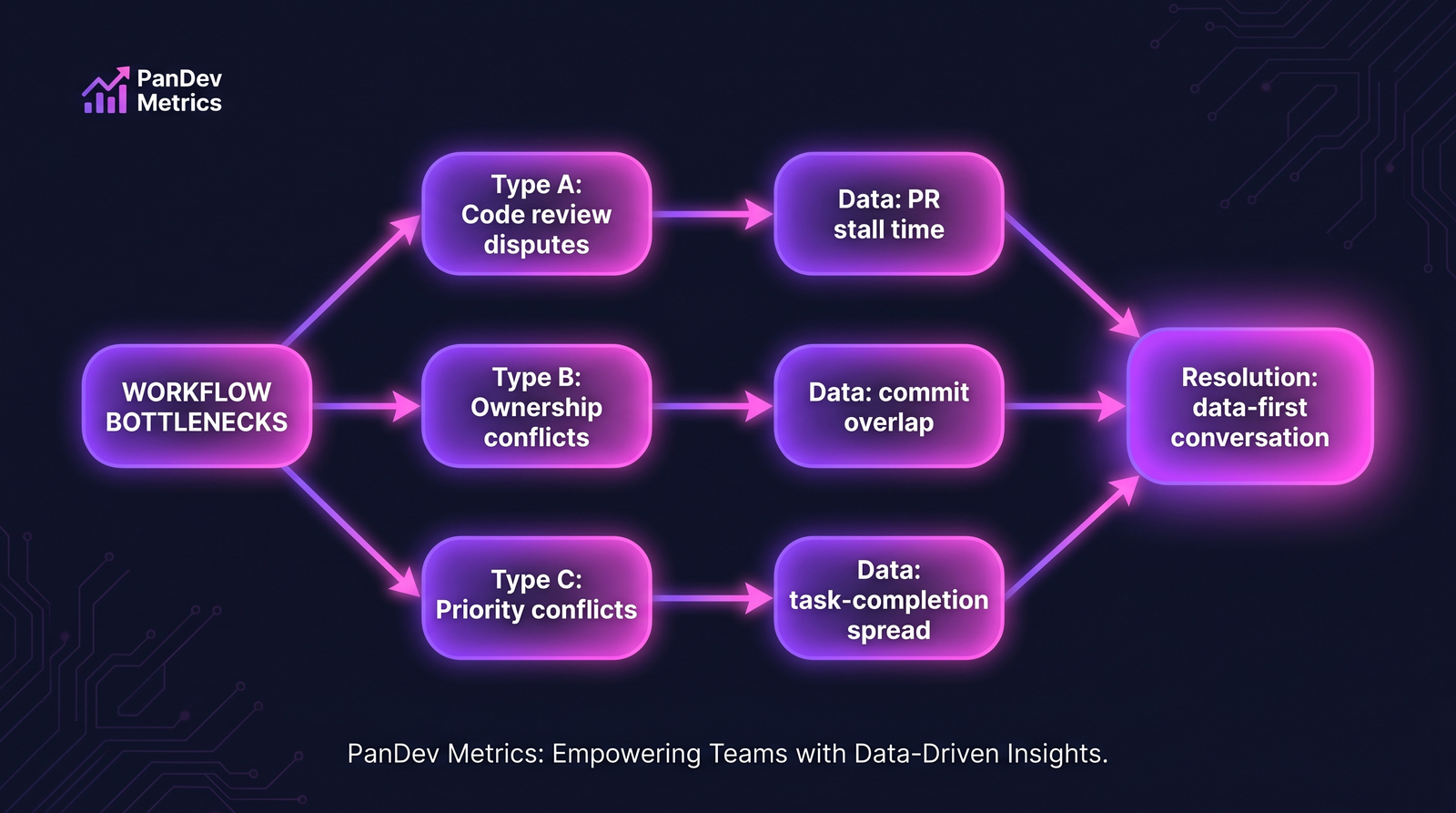 The four common conflict types. Each has a distinct data signature in Git/PR/IDE activity.
The four common conflict types. Each has a distinct data signature in Git/PR/IDE activity.
Most interpersonal friction on engineering teams reduces to one of four underlying conflicts. They look the same from inside — "I can't stand working with X" — but resolve very differently.
| Type | What it looks like | Data signature |
|---|---|---|
| A — Code review dispute | Long re-review cycles, passive-aggressive comments | PR stall time, review-round count per PR |
| B — Ownership conflict | "They keep touching my code without asking" | Commit overlap on shared files, cross-author merges |
| C — Priority conflict | "They don't understand what actually matters" | Task-type split per person (feature vs infra vs fix) |
| D — Workload conflict | "I'm drowning while they're coasting" | Hours distribution, weekend-work pattern |
Diagnosis first, technique second. The wrong technique on the wrong type makes the conflict worse.
Type A — Code review disputes
Surface: "X keeps rejecting my PRs" / "Y writes unreviewable code."
Data to pull:
- PR stall time by author × reviewer. For each merged PR, time from PR-open to merge, broken down by reviewer involvement.
- Review-round count. Average number of re-review cycles per PR between the two engineers.
- Comment density and tone. Count of comments per 100 lines of diff. Tone can't be quantified automatically, but density often proxies "friction."
A healthy pair sits at 1-2 review rounds per PR and a stall time close to the team median. Conflict pairs often show 4-6 rounds per PR or stall times 2-3x team median.
Resolution conversation:
- Show the two numbers to both engineers separately first
- Ask each: "What would have to change for this number to halve?"
- Joint meeting to agree one concrete change — usually either stricter PR-scope discipline (smaller PRs) or a pre-review chat norm
Don't ask "do you have a conflict?" Ask "what's slowing your work?" Data reframes it from feelings to workflow.
A short example
Two engineers were stuck at 4.2 review rounds per PR. After data conversation, agreed: PRs over 400 LOC require a 10-minute pre-review call. Within 6 weeks, rounds dropped to 1.8. The "conflict" resolved because the cause (PRs too big for async review) resolved.
Type B — Ownership conflicts
Surface: "X keeps touching my service without asking" / "Y gatekeeps everything."
Data to pull:
- Commit overlap per shared file. Which files in the last 60 days have commits from both engineers? Which files are "owned" by one (80%+ of recent commits)?
- Cross-author merge events. How many times did engineer A merge into engineer B's owned files without engineer B's review?
- Task-to-file mapping. Were the cross-author changes driven by in-scope tasks or ad-hoc decisions?
Healthy shared ownership shows bidirectional edits with review. Pathological patterns: one-way incursion (A commits into B's service 20x; B commits into A's service 0) or gatekeeping (A requires re-approval on changes that have nothing to do with A's service).
Resolution conversation:
- Draw the service-ownership diagram explicitly (even if informal before)
- Agree on the review rule: does cross-service change require owner review or just notification?
- If workload on the "incursion" was driven by emergency, discuss whether the staffing is right
Code ownership has to be an explicit team decision. Implicit ownership is where type-B conflicts live.
Type C — Priority conflicts
Surface: "X always picks the glamour work" / "Y does nothing but refactor."
Data to pull:
- Task-type distribution per person over last quarter: % feature / % refactor / % bug fix / % infra / % on-call response.
- Strategic allocation vs actual. If the team agreed "30% refactor quota this quarter," who hit it and who didn't?
- Correlation with career path. Refactor-heavy engineers may be signaling for senior/staff promotion; feature-heavy may be signaling for high-output recognition.
The conflict is often about fairness of the work mix, not about the work itself. An engineer doing 80% refactor feels undervalued when promotion talk centers on feature shipping; an engineer doing 80% feature work feels like they're doing all the "real" work while others "just refactor."
Resolution conversation:
- Show the distribution (by person) publicly to the team
- Ask the team: "Does this match what we agreed to?"
- If not — either the agreement was wrong, or the staffing is wrong
- Name which work is career-compounding and make sure every engineer gets a share
Priority conflicts resolve when the team agrees (publicly) what mix is desired, then tracks it. Not when individuals argue their preferences.
Type D — Workload conflicts
Surface: "X works nights and weekends, I don't" / "Y never responds on Slack."
Data to pull:
- Coding-time distribution weekly, per engineer.
- After-hours and weekend work hours.
- PR throughput and review-completion rate.
Healthy team: weekly coding-time median within 20% range across engineers, after-hours < 5% of total, weekend work rare.
The hardest conflict type: often one engineer's self-story is "I work harder" and the other's is "I work smarter." Data reveals the reality is usually neither or both.
Resolution conversation:
- Show the weekly distribution and after-hours pattern
- If the hard-worker is logging 55-hour weeks, ask the EM: is this the expected load? Can we add headcount or cut scope?
- If the "coaster" is actually shipping equivalent output in 35 hours, that's a pattern to protect and learn from, not punish
- If the distributions are similar but throughput gaps are real, the conflict is type A or C in disguise
The burnout signal. If after-hours work is > 15% of total weekly hours for either engineer, the conflict is a symptom of a burnout pattern — fix that first.
The data-first conflict conversation template
Run this template when you spot any of the four signatures:
| Step | What | Purpose |
|---|---|---|
| 1 | 1:1 with each engineer separately | Hear each side's self-story without contradiction |
| 2 | Pull the relevant data behind closed doors | Identify which type (A/B/C/D) applies |
| 3 | Share the data with each engineer separately | Remove defensive reflex |
| 4 | Ask "what would make this better?" | Let each propose |
| 5 | Joint 30-min meeting, data on screen | Agree ONE concrete change |
| 6 | 4-week check-in | Verify movement, not perfection |
The key inversion: most managers start at step 5 (joint meeting) with emotional data. Start at steps 1-3. The joint meeting is the easy part once the data exists.
The numbers that matter across all four types
| Metric | Healthy range (weekly, per engineer) | Warning threshold |
|---|---|---|
| PR stall time (median) | 8-48 hours | > 96 hours |
| Review rounds per PR | 1-2 | > 3 |
| Cross-author PR % | 10-30% | < 5% or > 50% |
| Coding-time variance across team | < 25% (coefficient of variance) | > 50% |
| After-hours hours | < 5% of total | > 15% |
These are anchors. When any metric lands in warning territory between specific pairs of engineers, a type-A/B/C/D conflict is likely forming — address it before it becomes the "I can't stand X" conversation.
How PanDev Metrics surfaces the signal
PanDev Metrics segments IDE and Git activity per-person and per-pair. For EMs, the useful view is the pairwise activity matrix: for each engineer pair on the team, their PR stall time, review rounds, cross-author commit overlap, and coding-time difference. When one cell turns warning-colored, the EM has a data-backed reason to open the conversation before it surfaces as interpersonal complaint.
We also track weekly focus-time and after-hours patterns — the two signals most predictive of type-D conflicts. The burnout detection patterns are the same underlying signal, interpreted at the individual level instead of the pairwise level.
Common mistakes to avoid
- Waiting until the complaint reaches HR. By then, the data has been obvious for months. Watch the matrix quarterly.
- Using data as evidence against one person. Data resolves conflict when it's shared with both engineers, not about one. If you present data as "here's why engineer X is the problem," you've made the conflict worse.
- Confusing correlation with causation. A review-stall pattern might be caused by PR size, not personalities. Ask before concluding.
- Skipping the 1:1 step. Joint meeting without individual prep turns into a debate.
- Expecting resolution in one meeting. The pattern took months to form. A 4-week check-in is where you verify the fix is real.
The contrarian claim
Most engineering-team "personality conflicts" are actually process failures in disguise. Teams and managers over-index on EQ and under-index on measurable workflow friction. When you fix the process (PR size, ownership clarity, priority agreement, workload balance), the personality conflict often disappears — not because anyone grew up, but because the underlying friction went away. The rare case where it's actually about personality is the minority, not the majority. Don't start the conversation there.
Honest limits
We can see pairs of engineers' Git and IDE activity. We cannot see their Slack DMs, their body language, or the 15-year dynamic between them if they worked together before joining your company. Some conflicts are irreducibly personal, and the data won't resolve them — it'll just tell you that the work patterns look normal, which means the issue is elsewhere. Combine data review with 1:1 conversations; neither alone suffices.
Our dataset on pairwise conflict is observational, not experimental. The four types above are inductive categories from customer conversations + our own observations across 100+ B2B companies — not a published taxonomy. Use them as hypotheses, not certainties.
Related reading
- 5 Data Patterns That Scream 'Your Developer Is Burning Out' — the individual-level signals underlying type-D workload conflicts
- How to Run Data-Driven 1:1s With Your Developers — the 1:1 template that makes step 1 of this article's conversation template work
- Engineering Metrics Without Toxicity: How to Track Productivity Without Breaking Trust — the meta-rule: data to help, not data to judge
- External: Harvard Business Review — The Hidden Costs of Team Conflict (2022) — role ambiguity as the top driver of interpersonal conflict