Dependency Management: npm vs pip vs Go Modules Playbook

A mid-size JavaScript service imports 47 direct dependencies and ends up resolving 2,500+ transitive packages. The same service ported to Go imports 12 direct modules and resolves 42 total. The pip equivalent sits near 180. These are not preferences — they are the shape of each ecosystem, and your dependency strategy has to start from that reality.
Your supply-chain exposure, lockfile discipline, and upgrade cadence should be different in each. This is a playbook for doing that well across npm, pip, and Go modules — the three ecosystems that cover about 84% of production backend code according to the 2025 Stack Overflow Developer Survey.
{/* truncate */}
The problem: one strategy doesn't fit three ecosystems
Most engineering orgs write a single "dependency policy" doc, apply it to every repo, and wonder why it feels wrong everywhere. It is wrong everywhere, because the three ecosystems have fundamentally different tradeoffs:
- npm optimizes for breadth. Tiny packages, deep trees, fast install, and a history of supply-chain incidents (
event-stream,ua-parser-js,node-ipc,xz-style attacks). Sonatype's 2024 State of the Software Supply Chain reported that npm accounted for 68% of observed malicious package uploads in 2023. - pip optimizes for scientific compute and system-level bindings. Fewer packages, but frequent C extensions, platform wheels, and "works on my machine" resolution failures.
- Go modules optimizes for minimal version selection and reproducibility. Smaller trees, cryptographic sum file, and version pinning baked in.
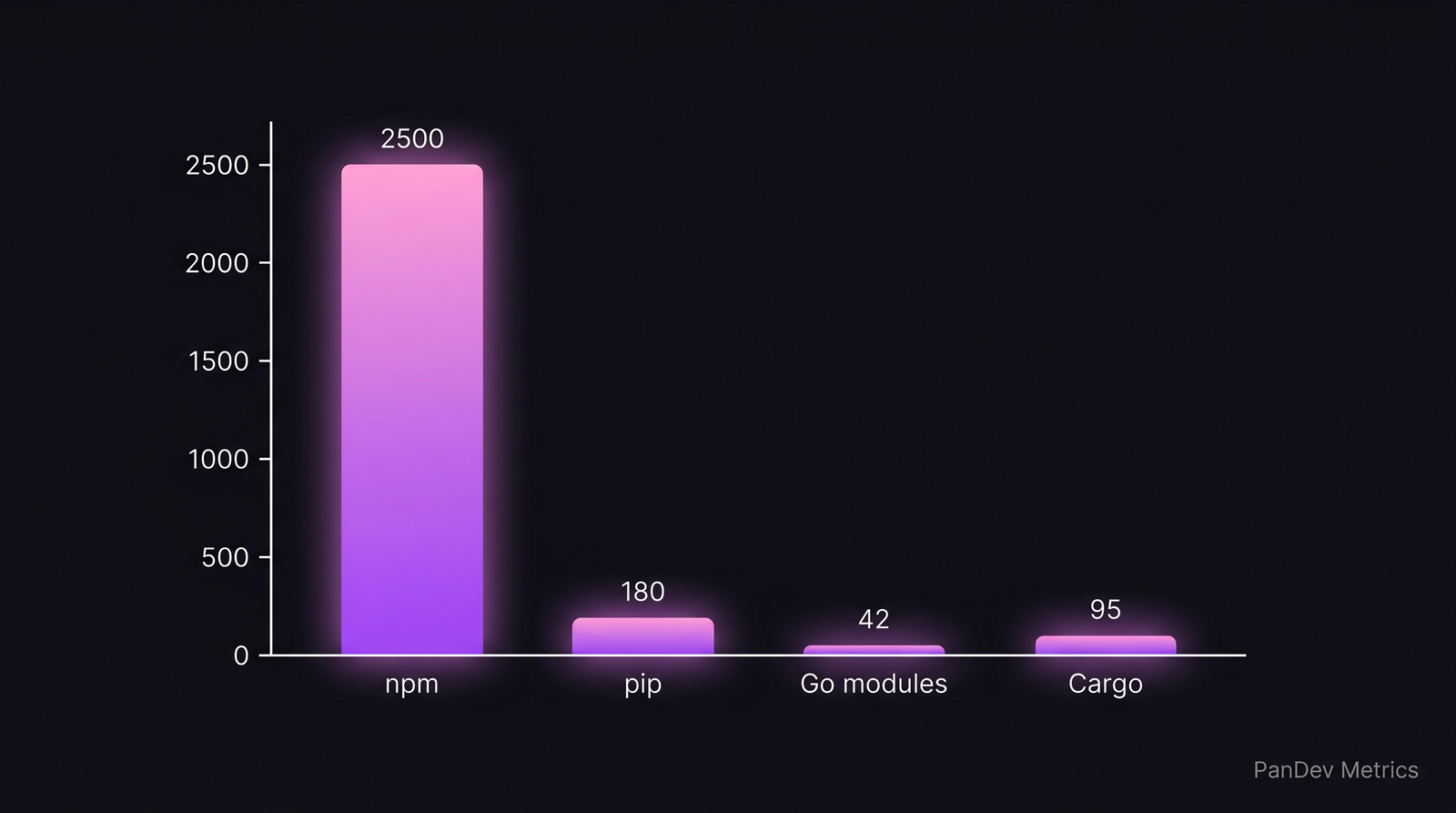 Average transitive dependency counts for a typical backend service. The shape of each ecosystem dictates the shape of your policy.
Average transitive dependency counts for a typical backend service. The shape of each ecosystem dictates the shape of your policy.
These are not failures of one or strengths of another. They are different answers to different problems, and a policy copy-pasted across them will miss the actual risk in each.
The framework: 6 steps that adapt per ecosystem
Step 1 — Inventory what you actually depend on
Before you improve anything, list every direct dependency across every service. For each, capture:
| Field | Why it matters |
|---|---|
| Name + version | Baseline identity |
| Direct or transitive | Direct is yours to fix; transitive is what you inherited |
| License | GPL contamination in a proprietary repo is a real risk |
| Last release date | Anything untouched >24 months is a red flag |
| Maintainer count | Single-maintainer is a bus-factor risk |
| Download trend | A falling package often signals abandonment |
Tools that do most of this automatically: npm ls --all, pip list --format=json + pipdeptree, go list -m all. For licenses: license-checker (npm), pip-licenses, go-licenses.
Step 2 — Choose a lockfile discipline per ecosystem
| Ecosystem | Lockfile | Commit it? | CI enforcement |
|---|---|---|---|
| npm | package-lock.json | Yes | npm ci (not npm install) |
| pnpm | pnpm-lock.yaml | Yes | pnpm install --frozen-lockfile |
| pip | requirements.txt + hashes, or uv.lock / poetry.lock | Yes | pip install --require-hashes |
| Go | go.sum | Yes | go mod verify in CI |
The contrarian part: do not use npm install in CI. It silently updates package-lock.json when the dev machine disagreed with the lockfile — this is exactly how a compromised version sneaks in without a PR. Always npm ci.
Step 3 — Set an upgrade cadence per tier
Not all dependencies deserve the same attention. Tier them:
| Tier | Example | Upgrade cadence | Auto-merge? |
|---|---|---|---|
| Runtime & security-critical | openssl, express, django, golang.org/x/crypto | Within 72h of CVE | No (review) |
| Core framework | react, fastapi, gin | Minor/patch within 2 weeks | Yes, if tests pass |
| Build tooling | webpack, ruff, goreleaser | Monthly batch | Yes |
| Low-risk utilities | lodash.chunk, humanize-duration | Quarterly batch | Yes |
Microsoft Research's 2023 paper "Keeping Dependencies Updated" (Mirhosseini et al.) found that teams who batch-upgraded weekly had 2.8× fewer broken builds from dependency drift than teams who upgraded on-demand. The mechanism is obvious once you see it: small diffs are easier to bisect.
Step 4 — Wire a bot, but configure it differently per ecosystem
Dependabot and Renovate are both fine. Renovate is more configurable, Dependabot is free and integrated into GitHub. Either way:
# renovate.config.json sketch
{
"packageRules": [
{ "matchManagers": ["npm"],
"matchDepTypes": ["devDependencies"],
"groupName": "npm dev deps",
"automerge": true,
"schedule": ["before 5am on monday"] },
{ "matchManagers": ["pip_requirements"],
"matchPackageNames": ["cryptography", "urllib3", "requests"],
"automerge": false,
"labels": ["security-review"] },
{ "matchManagers": ["gomod"],
"matchUpdateTypes": ["patch"],
"automerge": true,
"groupName": "go patches" }
]
}
The asymmetry is intentional: Go patches rarely break anything, npm dev-deps can be batched, pip crypto-adjacent libs always deserve human eyes.
Step 5 — Gate the pipeline with SCA, not just lockfiles
Software Composition Analysis (SCA) catches what lockfiles don't: known CVEs in the resolved tree. Minimal viable gates:
- npm:
npm audit --audit-level=high+osv-scanner - pip:
pip-audit(PyPA-official) +safety check - Go:
govulncheck(official, static-analysis driven — ignores unreachable code paths, which matters for Go's big transitive trees in stdlib-adjacent modules)
The quiet superpower is govulncheck. Because it reads your actual call graph, it tells you "this CVE exists in your dependency but your code never reaches it." That kills a massive amount of noise. npm and pip don't have anything equivalently precise yet.
Step 6 — Archive instead of shallowly updating
When a dep hasn't been touched in 24+ months and its tests are flaky against the current runtime, don't "just bump the version." Decide:
- Replace — find the maintained equivalent (e.g.,
moment→date-fnsorTemporalAPI in Node). - Vendor — for small utilities, copy the source into your repo under a
vendor/folder and own it. - Archive the service — if the service itself isn't worth modernizing, stop wasting time patching it.
The painful truth: 30% of dependency upgrade tickets in mid-sized repos should be vendor-or-replace decisions, not upgrades. Teams rarely make that call because upgrading feels like progress.
Common mistakes to avoid
| Mistake | Why it hurts | Fix |
|---|---|---|
npm install in CI | Lockfile drift, silent version changes | Use npm ci |
| Merging bot PRs without tests | 18% of dep upgrades break something (IEEE 2023) | Require green CI, no exceptions |
| Upgrading everything at once | Can't bisect the breakage | Tier + batch weekly |
| Ignoring transitive CVEs | Most exploits land via transitive deps | Wire SCA, not just lockfile review |
| Pinning to exact versions everywhere | Brittle, stuck at CVEs | Pin app deps, range library deps |
| Treating npm, pip, Go the same | Different ecosystems, different risks | Different policies per manifest |
How to measure if this is working
Track these per repo, per month:
- Mean time to patch critical CVE — target under 48h for runtime deps. DORA's Accelerate book ties this to change-failure rate indirectly.
- Lockfile drift in CI — number of PRs where lockfile changes unexpectedly. Target zero.
- Percentage of direct deps >24mo stale — keep under 10%. Above 20% is a slow-burning modernization debt.
- Transitive count growth month-over-month — flat or decreasing is healthy.
PanDev Metrics surfaces the "time-to-patch" metric by tying commit activity to CVE disclosure dates through Git events — when the package-lock.json or go.sum changes in response to a known advisory, it's visible in the dashboard alongside the engineer's other work, without requiring a separate security tool. For teams that already track DORA via our platform, dependency hygiene drops into the same view.
When this framework doesn't fit
- Pure-research Python codebases — scientific reproducibility often means freezing on an old version forever. The tiering above doesn't apply; use
uv/condalockfiles and accept the debt as the cost of reproducing a 2022 paper. - Solo open-source maintainers — most of this is overhead when you're one person. Dependabot +
npm auditin CI is enough. The "tier your deps" step starts to matter past ~5 contributors. - Extremely regulated environments (HIPAA, DO-178C) — the story is different: you need an SBOM pipeline, approved-vendor lists, and provenance signatures (SLSA, Sigstore). See our MedTech engineering metrics guide for where that fits.
A candid admission: our own IDE telemetry can tell you how much time engineers spend on dependency-related commits, but it can't tell you whether a given upgrade was strategically worth it. That judgment still belongs to humans reading release notes.