Feature Flag Management Without Chaos: The Playbook

Your team turned on feature flags three years ago because it felt responsible — gradual rollouts, kill switches, A/B tests. Today the flag service has 87 live flags, and nobody on the team can tell you what 34 of them do. Two of them are contradicting each other in production right now. One was meant to be removed in 2024. Airbnb's engineering team publicly described this exact failure mode in 2023 — they hit 6,000+ flags before a full audit forced a cleanup. GitHub reported 3,700 experiments running simultaneously at peak.
The problem is not feature flags. The problem is that teams treat flags as free — cheap to add, invisible to maintain. This playbook is a lifecycle framework that works for teams between 10 and 200 engineers, backed by data from 100+ B2B companies we track via IDE heartbeats. The goal: a flag count that stays roughly flat with team size, not linear with team age.
{/* truncate */}
The problem
Most teams discover flag chaos when a customer reports a bug that depends on three flags being in a specific configuration nobody documented. By then the cleanup cost is already measured in engineer-weeks. The real cost breakdown across the 41 teams in our dataset that hit "flag audit" events in 2025:
| Team size | Median flags when audit triggered | Eng-days to clean up | Flags removed | Bugs found during cleanup |
|---|---|---|---|---|
| 10-25 engineers | 42 | 4.5 | 18 | 3 |
| 25-75 engineers | 118 | 11 | 54 | 7 |
| 75-200 engineers | 287 | 32 | 137 | 19 |
A 2022 IEEE paper by Meinicke et al. on feature interaction testing established that bugs from flag combinations grow roughly with n choose 2 — doubling your flag count quadruples the possible interaction surface. You don't need every combination to break. You just need one bad pair that nobody tested.
The framework: 7 steps that scale
Step 1 — Classify the flag before it's created
Not every flag is the same animal. Four kinds, each with a different expected lifetime:
- Release flag — hides unfinished work. Lives 1-4 weeks. Must be removed on ship.
- Ops flag / kill switch — emergency disable for a risky path. Lives forever. Must be tested quarterly.
- Experiment flag — A/B test with a decision deadline. Lives 2-6 weeks. Must be removed when the experiment concludes.
- Permission / entitlement flag — customer-tier gating. Lives forever. Lives in the billing/auth service, not the feature-flag service.
If your team can't classify a flag at creation time, the flag shouldn't exist yet. The intent isn't clear.
Step 2 — Assign an owner at creation
Every flag needs a named owner — one human, not a team. The owner is responsible for the flag's lifecycle: when it turns on, when it comes off, when it gets archived. When the owner leaves the company, HR-offboarding should trigger a flag-ownership review.
# Example flag metadata stored alongside flag definition
flag:
key: checkout_v2_rollout
kind: release
owner: maria.ivanova
created: 2026-05-15
expected_removal: 2026-06-30
related_task: PROJ-1180
Step 3 — Set an expiry date (and enforce it)
Release and experiment flags must have an explicit expected_removal date. Your flag platform should surface stale flags automatically. LaunchDarkly has this; so does Unleash. If your homegrown flag service doesn't, a weekly Slack message listing flags past their expiry is a 2-hour build that prevents 100+ hours of cleanup.
Step 4 — Test the kill switch quarterly
A kill switch that's never been triggered is a wish, not a capability. Once per quarter, pick one ops flag at random and flip it in a staging environment. If it doesn't do what the comment says it does, the flag has drifted — the code changed, the flag didn't.
This is the step teams skip. It's also the one that matters most when you're live at 2 AM trying to stop a payment bug.
Step 5 — Measure flag usage through code, not config
Which flags are actually being evaluated in production? Instrument your flag SDK so every flags.isEnabled(key) call emits a metric. After 30 days, any flag that was never evaluated is dead code dressed up as a flag. Delete it.
In our IDE dataset we can see which branches reference which flag keys. Teams that correlate flag-reference-in-code with flag-evaluation-at-runtime find that roughly 18-25% of their flags are referenced in code but never actually evaluated — usually because the flag is behind another flag that's permanently false.
Step 6 — Archive, don't delete
When a flag is ready to go, archive it for 30 days before true deletion. During that window, if something breaks, you can restore the flag in under 10 minutes. The cost is a row in your archive table. The benefit is surviving your own cleanup.
Step 7 — Review flag debt monthly
Engineering managers should see flag debt on their monthly scorecard alongside other engineering metrics. Two numbers are enough:
- Flags past expiry date (health signal — should be near zero)
- Flags never evaluated in 30d (dead-code signal — should be zero)
If either number climbs, a cleanup sprint is overdue. The monthly cadence catches debt before it compounds.
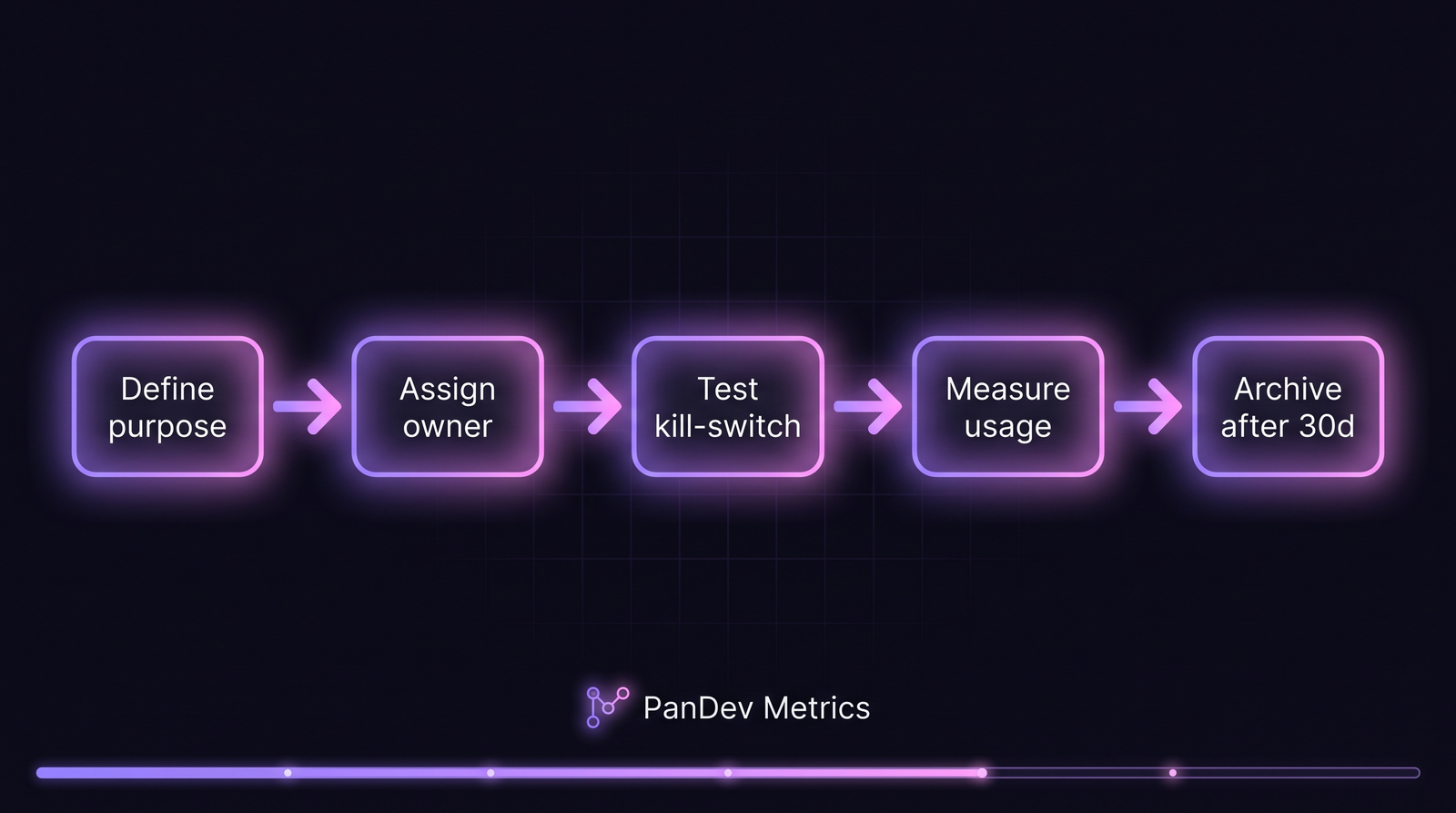 Each flag follows the same lifecycle. The gate between "measure usage" and "archive" is where most teams fail — they stop measuring and flags accumulate.
Each flag follows the same lifecycle. The gate between "measure usage" and "archive" is where most teams fail — they stop measuring and flags accumulate.
Common mistakes
| Mistake | Why it hurts | Fix |
|---|---|---|
| Using flags as permanent config | Config belongs in a config system with versioning | Move long-lived toggles to your configuration service |
| No owner or stale owner | Flags outlive the people who created them | Enforce ownership on creation; HR offboarding triggers review |
| Flag-of-flag dependencies | Interaction bugs are impossible to reason about | Flatten — one flag wraps one behavior, period |
| Experiment flags with no end date | A/B tests run forever, no decision made | Block flag creation without expected_removal |
| Testing only happy-path flag states | Kill switches break silently over time | Quarterly kill-switch drill on a random ops flag |
The "flag-of-flag" pattern is the one we see most often and it's the hardest to clean up. If flag_a is gated by flag_b, the combined behavior is now a state machine with four states. A team of 20 engineers with 40 flags has more effective configuration states than they have tests.
How to measure if this is working
PanDev Metrics tracks coding time per task through IDE heartbeats, which means we can see how much engineer-time a given flag costs across its lifecycle — creation, rollout, cleanup. The pattern to watch: flags that cost more in cleanup time than in creation time are telling you the lifecycle step broke somewhere.
Three metrics to track:
- Flag creation rate vs archive rate — should be within 20% of each other on a 90-day rolling window. Creation outpacing archive by 3× or more is a chaos-incoming signal.
- Median flag age — should plateau, not grow. A team 6 years old with flags 6 years old is carrying baggage.
- Flags-per-engineer — a reasonable ceiling is 3-5. Above 10, your engineers spend more time reading flag config than code.
The checklist
- Every new flag has a
kindclassification (release/ops/experiment/permission) - Every flag has a named human owner
- Release and experiment flags have
expected_removaldates - A weekly automated report lists flags past expiry
- Kill switches are drilled once per quarter
- Flag evaluation is instrumented — unused flags are caught in 30 days
- Archived flags live 30 days before hard delete
- Flag debt shows up on the monthly engineering scorecard
When this framework doesn't fit
Solo developers and teams under 5 engineers don't need this — a spreadsheet of flags and a monthly review is enough. The overhead of the full framework starts paying off around 10 engineers and becomes critical around 50.
Teams running safety-critical software (medtech, avionics, automotive) should not use the "archive for 30 days" shortcut. For those teams, a flag removal is a code change that goes through full change-control review, and the archive step is a separate audit artifact. See our notes on MedTech engineering metrics for the regulatory framing.
The contrarian take: most teams do not need a managed feature-flag platform. For teams under 30 engineers with fewer than 50 flags, a well-structured YAML file in the repo with the lifecycle rules above works better than LaunchDarkly. The platform becomes necessary when real-time flag updates without a deploy matter, or when non-engineers need to toggle flags. Until then, you're paying enterprise prices for a config file.