Insurtech Engineering: Regulated Speed, Scalable Risk

An insurtech CTO once told me: "We're not a SaaS company. We're a SaaS company that sells a financial derivative." The distinction matters because insurance software doesn't just ship features — it ships risk models that regulators will probe on a five-year horizon. A bug in a claims service is a customer-support ticket. A bug in a pricing model is a filed regulatory complaint, a potentially mis-priced book of business, and a cleanup that measures in quarters rather than sprints.
Deloitte's 2024 Global Insurance Outlook reported that 47% of insurers cite legacy system modernization as their #1 engineering constraint. The teams doing that modernization are walking a tightrope: the regulators (EIOPA in the EU, NAIC in the US, Bank of Russia and Kazakhstan's AFSA in CIS markets) don't care that you adopted continuous deployment. They care that you can prove which version of your actuarial model priced a policy on a given date.
{/* truncate */}
Why insurtech engineering is different from fintech
Fintech and insurtech get lumped together in "regulated financial software" buckets, but the engineering constraints diverge sharply.
Fintech lives in transaction-time. A payment succeeds or fails in seconds. The regulator (FCA, OCC, CBR) audits via transaction logs and reconciliation reports. Engineering metrics revolve around DORA-style velocity with audit-trail discipline.
Insurtech lives in contract-time. A policy sold today might pay a claim in 2041. The regulator audits via model documentation, pricing justification, and a historical reconstruction of every parameter change. Engineering metrics revolve around reproducibility — not just "can we ship fast?" but "can we reconstruct the model state from February 17 at 14:30:12?"
That shift in time-horizon reshapes the toolchain:
| Regulation / Standard | What it requires | Where it hits engineering |
|---|---|---|
| Solvency II (EU) | Documented governance of internal models and data quality | Every actuarial model deployment needs cryptographic attestation of inputs/code/outputs |
| NAIC Model Law (US) | Cybersecurity risk assessment, model governance | Dev access to actuarial models must be least-privilege and logged |
| GDPR / CCPA | Right-to-erasure over policyholder data | Data-lineage tracking from claim submission to ML model retraining |
| Model Risk Management (MRM, OCC SR 11-7) | Independent validation of all models used in decision-making | Separate code review / test lineage from model developers to validators |
| ICS (IAIS, global) | Group-wide solvency consistency | Cross-subsidiary deploy coordination — a change in one subsidiary's pricing engine affects group-level reporting |
None of these rules say "track lead time for changes." They all implicitly assume you can — and penalize you if you can't answer basic engineering-hygiene questions about your production code.
The reference architecture (and what gets measured where)
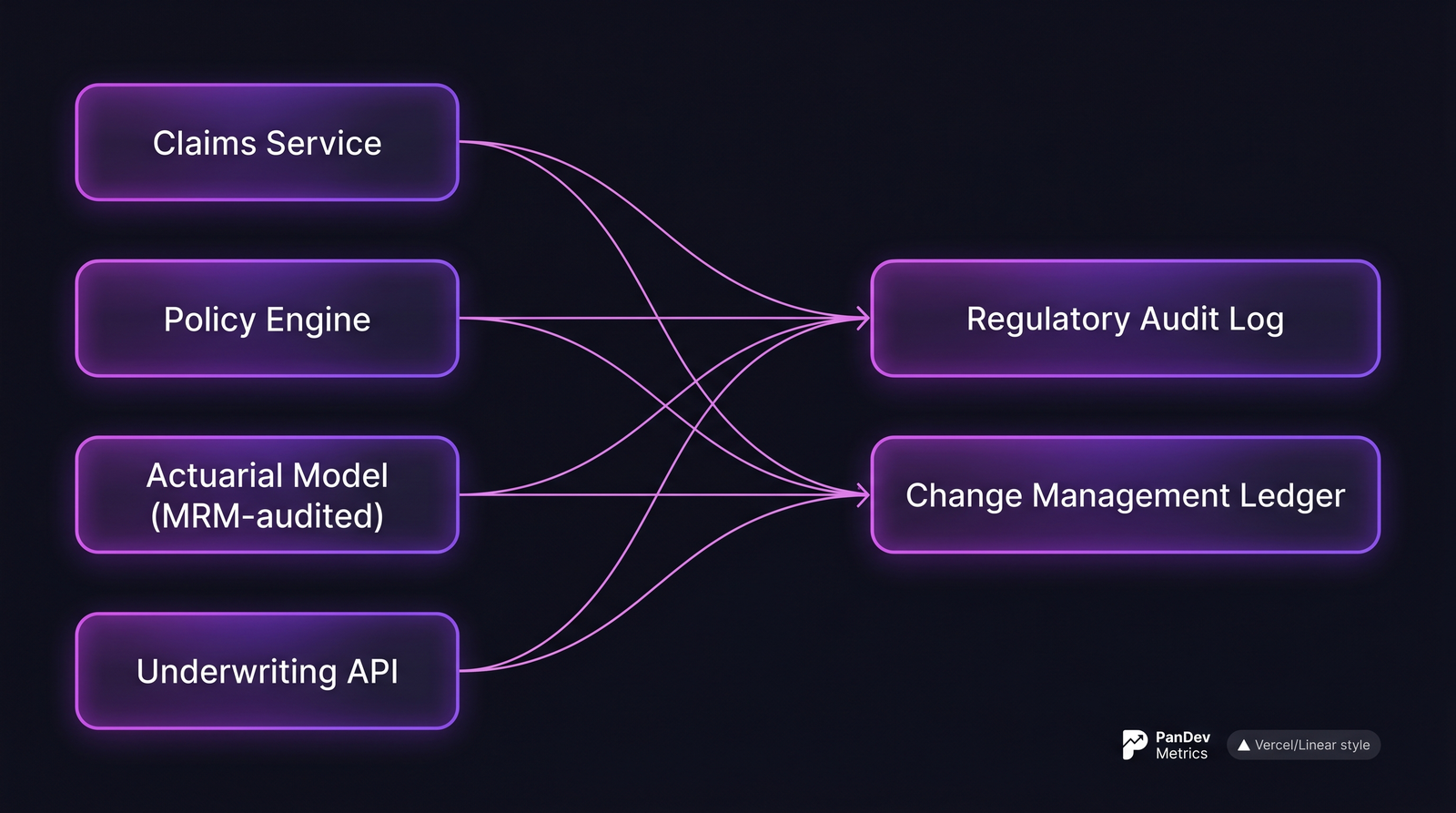 A typical insurtech platform. The audit log and change ledger are where compliance lives. Your engineering metrics must feed both.
A typical insurtech platform. The audit log and change ledger are where compliance lives. Your engineering metrics must feed both.
The "change management ledger" is the insurtech-specific artifact. Every production change — from a UI tweak to a discount-rate constant — has to map to:
- the ticket that authorized the work,
- the engineer(s) who wrote the code,
- the reviewer(s) who approved it,
- the deployment event that activated it in prod,
- the rollback path (if applicable),
- the downstream policies/claims affected.
If your engineering metrics tool can't feed that ledger, it's the wrong tool for this industry.
The 5 metrics that matter in insurtech
1. Model change lead time (not just code lead time)
In SaaS, "lead time for changes" is the DORA-standard commit-to-deploy duration. In insurtech, the more useful metric is model change lead time: the time from actuarial-team signoff on a new pricing assumption to that assumption going live in production.
This includes intervals regulators care about:
- Actuarial peer-review time (MRM requires independent validation before production use)
- Integration testing against historical policy data
- Parallel-run period (new model runs alongside old model; outputs compared for divergence)
Target benchmark: 4-8 weeks for pricing-model changes in large insurers, 1-3 weeks in API-native insurtechs. Anything under a week on a pricing change without explicit regulator pre-approval is a red flag, not a brag.
Why self-report fails for this: engineers code the change in hours, then it sits in validation queues for weeks. A timesheet won't capture the cycle; the IDE telemetry + Git events + ticket state will.
2. Change failure rate, segmented by blast radius
A global DORA "change failure rate" averages across all deploys. Insurtech needs segmented failure rates because the business impact varies by 4-5 orders of magnitude:
| Deploy type | Acceptable CFR | Blast radius if wrong |
|---|---|---|
| Marketing site | 20-30% | Bounce-rate drop for an hour |
| Policy search UI | 10-15% | Quote abandonment |
| Underwriting API | 3-5% | Mispriced policies written for hours |
| Actuarial model | Under 1% | Book-of-business mispricing visible at quarter-end |
| Claims settlement logic | Under 0.5% | Wrongful denials → regulatory complaints |
A single CFR number across these is meaningless. Segmentation is a first-order design decision, not a dashboard tweak.
3. Audit-trail completeness
Can you produce, for any production deploy of the last 7 years (standard retention for most insurance jurisdictions), a complete chain of:
- Ticket → branch → commits → PR → reviewer approvals → CI/CD run → deploy event → first claim/policy affected?
Teams typically score themselves 90%+ on this dimension and measure 60-75%. The gap comes from branches without task IDs, direct-to-main merges, hotfixes that skipped the ticket system, and deploys where the CI/CD metadata got overwritten by a retry.
What to track: percentage of production deploys where the full chain reconstructs without manual intervention. Below 95% means a future audit will be painful.
The one Git-workflow rule that matters here: branch names must contain task IDs (feature/POL-1480, fix/CLM-2117). Insurtech is the industry where that rule pays for itself first — it's the anchor that makes the entire chain reconstructible.
4. Separation of duties (the MRM test)
Model Risk Management guidance (OCC SR 11-7 in US, similar PRA SS1/23 in UK) requires independent validation of models used in decision-making. Operationally: the people who write pricing models cannot be the people who validate them for production.
The engineering metric: for every production deploy touching actuarial or pricing logic, was the approver distinct from every committer? In legacy shops with small teams, this breaks all the time — the modeler also writes the review comment because they're the only one who understands the code. That's a finding in every MRM audit.
Target: 100% separation for anything tagged actuarial/, pricing/, or underwriting/. If you can't get to 100%, document the exceptions and the compensating controls, because the regulator will ask.
5. Parallel-run divergence time
When a new pricing model goes live, it runs in shadow mode alongside the old one — both score every incoming quote, but only the old one's output goes to the customer. The engineering metric is how long the shadow run takes before divergence between old and new stabilizes to an explainable delta.
Target: stable divergence within 2-4 weeks for most pricing changes. Longer means the new model is drifting in ways nobody understands; shorter means the new model is functionally identical to the old one and you just burned validation budget on a no-op.
This metric is almost invisible in typical engineering dashboards. Yet it's the single best predictor of whether a pricing change will clear regulator review without a re-filing.
How compliance changes measurement
Three practical consequences of operating under insurance regulation:
Data retention beats data freshness. A SaaS engineering team cares about 90-day trends. An insurtech team cares about 7-year reconstruction. This means your engineering metrics platform must retain raw event data — not just aggregates — for the full regulatory retention window. Most SaaS metrics tools roll up after 180 days. That's a compliance landmine.
On-prem or sovereign-cloud beats multi-tenant SaaS. GDPR, CCPA, and jurisdiction-specific data residency rules (Kazakhstan's Law on Personal Data, Russia's Federal Law 152-FZ) mean engineering telemetry often can't leave the country of operation. Multi-tenant SaaS metrics platforms lose this battle by default. At PanDev Metrics we see this regularly: regulated financial customers request the on-prem Docker or Kubernetes deployment specifically so engineering telemetry stays inside their regulated perimeter.
Reproducibility beats real-time. A dashboard that says "your DORA metrics look green today" is less valuable than one that says "on November 3, 2024, your deploy-to-quote-update latency was 87 minutes, here is the commit chain that produced it." Insurtech engineering tooling is judged on historical reconstruction, not on dashboard polish.
Typical insurtech engineering team profile
| Parameter | Typical range (2026) |
|---|---|
| Team size | 40-250 engineers |
| Tech stack | Java (legacy Spring), Scala or Kotlin (new), Python for actuarial ML, React/Angular for agent portals |
| Deploy cadence | Daily for marketing/UI, weekly for APIs, monthly for pricing engines |
| Primary pressure | Regulatory reproducibility + multi-jurisdiction localization |
| Model governance | Separate actuarial-science org, typically 10-40 people |
| Toolchain | GitLab or GitHub Enterprise, Jira + ServiceNow, Jenkins or GitLab CI, Vault, PagerDuty |
| Data retention | 7 years minimum (varies by jurisdiction) |
What to track differently from a standard SaaS team
- Audit trail over velocity. Don't publish lead-time improvements to leadership if the audit chain has gaps. Faster broken process is worse than slower traceable process.
- Deploys segmented by risk class. A single "deploy frequency" number hides the fact that marketing deploys are daily and pricing deploys are monthly — and that's correct, not a problem to fix.
- Model drift metrics. Beyond engineering: parallel-run divergence, calibration stability, fairness across protected attributes. These belong in the engineering dashboard for the actuarial and ML teams, not just in data-science notebooks.
- Cross-subsidiary coordination. Groups operating in multiple jurisdictions deploy the same feature at different cadences because regulators differ. Track deploy-gap time across entities; it reveals where group-level engineering coordination is failing.
Common pitfalls
- "We use DORA, we're fine." DORA is necessary, not sufficient. A team with great DORA scores and broken separation-of-duties will fail its next MRM audit regardless of green dashboards.
- Treating actuarial models as "just code." They're not. They need separate code review lineage, separate validation records, and separate rollback procedures. Your CI/CD pipeline for pricing-model repos should not look like your CI/CD pipeline for the marketing site.
- Trying to hit fintech deploy cadence on pricing engines. A team that went from monthly to daily pricing deploys in 2023 and got audited in 2024 spent a quarter rebuilding every audit chain the engineer-hours had skipped. Speed is the wrong optimization target for the pricing path.
- Storing engineering telemetry in multi-tenant SaaS. Not a pitfall universally, but one that a regulator can weaponize during an exam. Know your jurisdiction.
The contrarian point: most insurtech engineering leaders think their biggest risk is velocity. Actual audit data suggests it's traceability. The teams that get sanctioned are rarely the slow ones; they're the ones who couldn't reconstruct how a specific production state came to be.
The honest limit
Our dataset is strong on B2B SaaS engineering behavior and decent on fintech. Insurtech-specific signal is thinner — we have visibility into roughly a dozen insurance-adjacent customers, mostly in EU and CIS jurisdictions. The benchmarks above draw more on regulatory-document analysis and interviews with insurtech engineering leaders than on our telemetry alone. Teams in US P&C or reinsurance segments may see materially different numbers; treat the benchmarks as starting points for your own measurement.
Where PanDev Metrics fits
PanDev Metrics runs as an on-prem Docker or Kubernetes deployment — the configuration most insurance customers need for data-residency compliance. The IDE heartbeat telemetry plus Git + tracker integration gives the traceable commit-to-deploy chain that MRM audits demand. What we don't do: model-governance workflows (those belong in dedicated tools like Domino or Dataiku) or actuarial model validation. We're the engineering-intelligence layer beneath those workflows, not a replacement for them.
Related reading
- DORA Metrics for Fintech: Proving Process Maturity to Regulators — the sibling industry, with overlapping but distinct engineering constraints
- MedTech: Engineering Metrics in a Regulated Environment — another regulated vertical, with different retention windows and validation demands
- Change Failure Rate: Why 15% Is Normal and 0% Is Suspicious — the baseline CFR conversation that insurtech must segment rather than average
- External: OCC SR 11-7 Model Risk Management Guidance — the US reference document most insurtech engineering leaders eventually read