Kubernetes Engineering Observability: What to Track in 2026

A platform team running 11 production Kubernetes clusters has 94,000 metrics scraped every 15 seconds, 2.4 TB of logs per day in Loki, and a Grafana instance with 340 dashboards. When their VP of Engineering asked "are our teams shipping reliably on K8s?", nobody could answer in under an hour. They had cluster observability. They had zero engineering observability.
These are two different problems. Cluster observability tells you whether pods are healthy. Engineering observability tells you whether engineering on top of those clusters is healthy — whether deployments are fast, whether rollbacks are rare, whether developers are waiting on infrastructure or fighting with it. Most K8s shops have solved the first and ignored the second. The 2024 CNCF annual survey reported that 68% of enterprise K8s users struggle with "making observability actionable", which is a polite way of saying they have metrics but no decisions come out of them.
{/* truncate */}
The problem cluster dashboards don't solve
Cluster dashboards answer: "is my infrastructure healthy right now?"
Engineering observability answers:
- Are we shipping to these clusters faster or slower than last quarter?
- When developers push to main, how long until the change is serving traffic?
- Which services are eating the most developer time vs delivering the most value?
- Which teams are stuck fighting K8s and which are actually using it?
These aren't Prometheus queries. They come from correlating cluster events (deploys, rollbacks, HPA scaling, pod restarts) with engineering events (commits, PRs, incidents, on-call pages). Most tools do one side. Few do both.
The CNCF 2024 State of Observability found that teams with correlated cluster-and-engineering signals had 34% faster MTTR on production incidents than teams using only cluster metrics. The delta isn't because the tools are better — it's because you don't have to screen-share between Grafana and Jira during an incident.
The stack that actually works in 2026
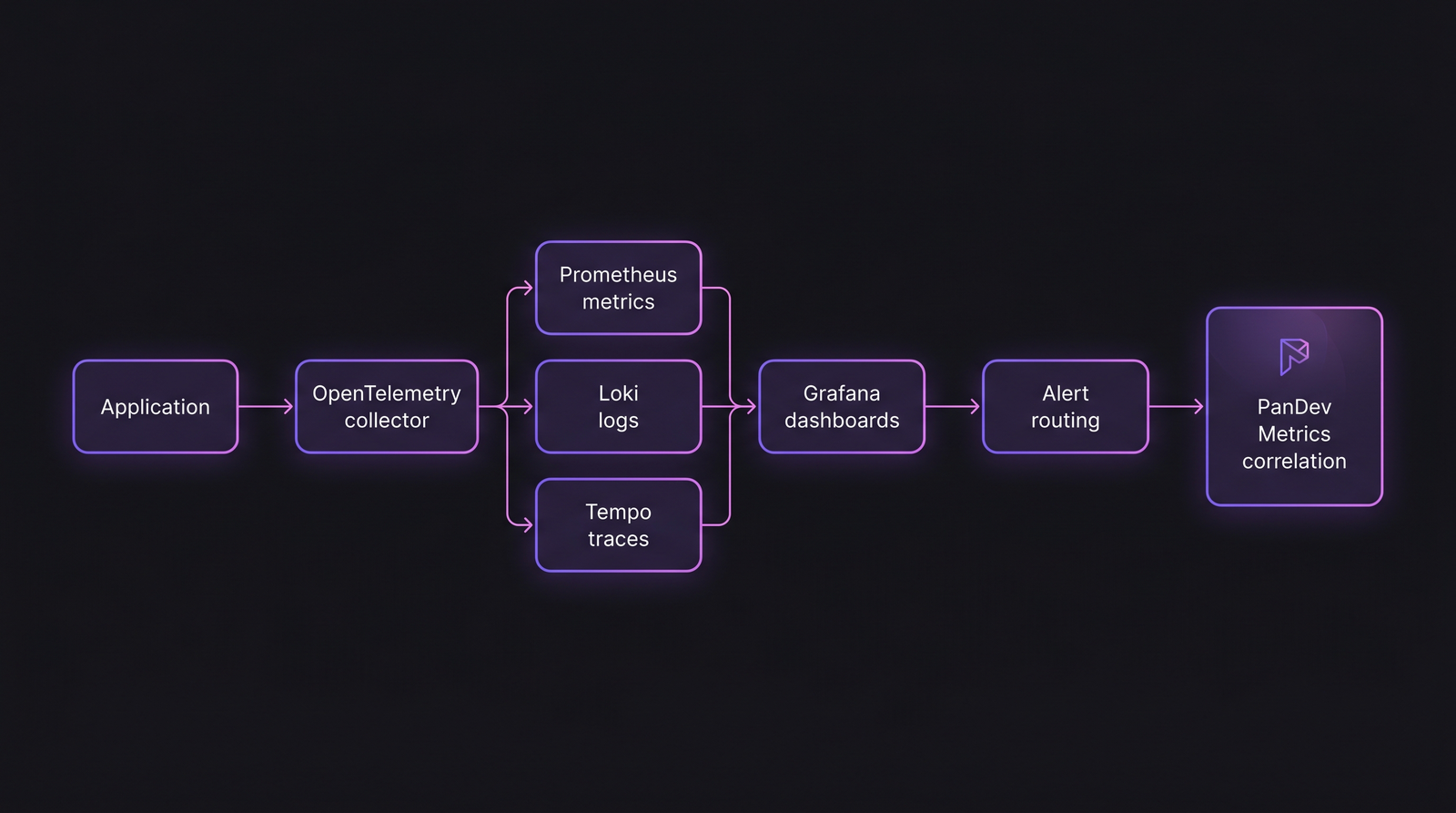 The typical 2026 observability stack. The layer most teams miss: correlating cluster telemetry with engineering telemetry at the boundary.
The typical 2026 observability stack. The layer most teams miss: correlating cluster telemetry with engineering telemetry at the boundary.
The foundation (everyone has this)
| Component | Purpose | Defaults worth knowing |
|---|---|---|
| Prometheus | Metrics storage | 15s scrape, 15d retention default (raise to 30d+) |
| Grafana | Dashboards + alerting | Tempo/Loki panels natively available since v10 |
| Loki | Log aggregation | Label-based, cheaper than ELK at scale |
| Tempo / Jaeger | Distributed tracing | Tempo default in CNCF stack, Jaeger still fine |
| OpenTelemetry | Instrumentation standard | By 2025, the clear winner over vendor SDKs |
| kube-state-metrics | K8s object state | Different from metrics-server; you need both |
If you're still running the Prometheus Operator without OpenTelemetry collectors, you're one stack upgrade behind. The 2024 KubeCon trend was explicitly OpenTelemetry-first — not because Prometheus is bad, but because OTel lets you switch backends without reinstrumenting apps.
The layer most teams miss
Engineering-aware observability. Cluster metrics alone don't answer "are we shipping well?". You need to correlate deploys with:
- Git commits (who wrote what, tied to which task)
- PR lead time (from open to merge)
- Deploy success/rollback rates
- Error rate delta per deploy (not overall error rate — the change after each deploy)
- On-call interruption frequency per service
This is where the measurement gets interesting. A service with 99.95% uptime but 40 on-call pages per week is not healthy — it's surviving through human labor. A cluster dashboard won't show that. An engineering-correlated view will.
What to track, grouped by who's asking
For SREs / platform engineers
| Metric | Target | Red flag |
|---|---|---|
| P99 pod scheduling latency | <2s | >10s (scheduler saturation) |
| Crash loops per day | <3 per cluster | 10+ per day (unstable platform) |
| HPA effectiveness (scaled up when needed?) | >95% | <80% (reactive scaling failures) |
| Image pull P95 | <30s | >2 min (registry / network issue) |
| etcd latency P99 | <100ms | >500ms (cluster-wide slowdown imminent) |
For engineering leaders
| Metric | Target | Red flag |
|---|---|---|
| Deployment frequency (per team) | Daily+ | Weekly (or less) |
| Lead time from PR merge to prod | <30 min | >2 hours |
| Change failure rate (deploys triggering rollback) | <15% | >25% (DORA elite threshold) |
| Mean time to restore (MTTR) | <1 hour | >4 hours |
| % of deploys rolled back via automation | >80% | <50% (manual rollback signals maturity gap) |
For engineering managers (team-level)
| Metric | What it reveals |
|---|---|
| Engineer time lost to infra (per sprint) | Platform friction |
| PRs reverted within 48h | Deploy confidence issue |
| Services on-call per engineer | Cognitive load |
| Services with no owner | Bus-factor / orphan risk |
| Container rebuild failures per day | CI reliability |
The last metric is the quiet one. A team doing 50 container rebuilds/day with 8% failure rate loses 4 rebuild cycles to nothing every day. At 15 minutes per cycle, that's an hour of engineering time per day, per team — invisible on Grafana, very visible on payroll.
How PanDev Metrics correlates this
Where our product plugs in: we pull git commit data (via GitHub/GitLab/Bitbucket integrations), IDE heartbeat data (so we know which service engineers were working in), and deployment events from CI/CD systems (GitHub Actions, GitLab CI, Jenkins). We correlate those against cluster events — specifically rollbacks, HPA scaling, and pod restarts.
The result: a view that answers "which services took the most engineering time this quarter, and what was the deploy-to-incident ratio?". A service that eats 220 engineering hours per quarter and rolls back every 3rd deploy is being held together by the team, not by the platform. That's a signal most cluster dashboards won't give you.
One caveat we're honest about: our cluster-side integrations cover Prometheus webhook events and Kubernetes Event webhooks. We don't run an agent inside the cluster. Teams needing deep in-cluster metrics (eBPF-level traces, container-runtime telemetry) still need Prometheus + OTel in parallel. We're the correlation layer, not the replacement.
Anti-patterns we see often
1. "Dashboard per team" explosion. 40 teams, 40 dashboards, nobody knows which is authoritative. Consolidate into role-based dashboards (SRE view, EM view, CTO view) and let people filter.
2. "Alerts on everything" fatigue. A 2024 PagerDuty benchmark showed that teams paging more than 14 times per engineer per week have alert fatigue and actually respond slower than teams with fewer, higher-quality alerts. Threshold: alert on symptoms users feel, not on causes you assume.
3. "Tracing without sampling strategy". Head-based sampling at 1% is the default. In a high-RPS service, 1% means you miss the long-tail outliers (which are the incidents). Tail-based sampling + head-based for volume is the 2026 best practice, enabled in OTel Collector since v0.100.
4. "No SLO, just uptime". SLOs ground alerting in user experience. A service with 99.9% uptime might be unusable if P99 latency is 8 seconds. Measure the experience-defining metrics and set error budgets against them.
The contrarian claim
Most K8s observability pain in 2026 is cultural, not technical. The tools (Prometheus, Grafana, OTel, Tempo, Loki) have been production-solid for 2+ years. What's broken is who owns the dashboards, who gets paged, and what counts as "healthy". Three teams we've worked with fixed their observability not by buying new tools but by deleting 60-80% of their dashboards and consolidating the rest.
Honest limit: our view is biased toward teams running both IDE plugins and cluster integrations — probably 40-50 companies in our customer base at the time of writing. That's a specific slice (mostly B2B SaaS and fintech), not the full K8s market. Teams running EKS at FAANG scale have different problems, and our signal there is thinner.
Related reading
- How to Implement DORA Metrics in Your Team in 2 Weeks
- MTTR: Why Speed of Recovery Matters More Than Preventing All Failures
- On-Premise Deployment: PanDev Metrics With Docker and Kubernetes
If your K8s observability stack is costing you a full FTE just to keep green, the problem isn't the stack — it's the scope.