Monorepo vs Polyrepo: Team Productivity Impact (Real Data)

Your 40-engineer team maintains 34 repositories. Sound reasonable? We see this shape often. A typical developer in that configuration triggers 11.4 context switches per day between repositories — almost all invisible to the EM, each costing roughly 23 minutes of refocus time, per UC Irvine's Gloria Mark (The Cost of Interrupted Work, 2008) and subsequent replications. The same team post-monorepo migration: 3.2 switches per day. The productivity math is obvious; the cost math is where it gets interesting.
Both architectures work. Google runs the largest known monorepo (2 billion+ lines of code, ~85,000 engineers). Netflix runs thousands of polyrepos. The question isn't which is better in the abstract — it's which fits your team size, your CI budget, and your tolerance for coordination overhead.
{/* truncate */}
Positioning
Monorepo: single version control root containing multiple projects, services, and libraries. Atomic cross-cutting changes, shared tooling, unified dependency graph. Examples: Google (Piper / google3), Meta (hg-based), Uber (Go monorepo), Shopify (Rails monorepo).
Polyrepo: each service/library/application in its own repository, independently versioned. Clear ownership boundaries, independent CI pipelines, repository-level access control. Examples: Netflix, most AWS teams, typical microservices shops.
Neither is inherently better. Each trades a different class of problem.
Feature-by-feature comparison
Developer experience day-to-day
| Capability | Polyrepo | Monorepo |
|---|---|---|
| Clone fresh machine setup time | Fast per repo; painful across 20 repos | Slow once, then done |
| Cross-cutting refactor | Coordinated PRs across N repos | Single atomic PR |
| Find "where is this used?" | Grep each repo, painful | Single grep |
| Dependency version drift | Common, often painful | Enforced single version |
| Onboarding: "which repo is this in?" | 30 minutes of Slack queries | Self-evident |
| IDE indexing time | Small | Can be massive (Google built custom IDE support) |
Team coordination
| Capability | Polyrepo | Monorepo |
|---|---|---|
| Ownership boundaries | Repo-level, clear | Path-based CODEOWNERS, slightly less clear |
| Cross-team API change | Versioning dance | Atomic cut-over |
| Breaking downstream consumer | Consumer catches up at their pace | Breaker fixes all callers now |
| Code review across teams | Rare | Common (and sometimes unwelcome) |
| Shared libraries upgrade | Per-consumer schedule | Committed in one PR |
| Deployment coordination | Independent | Requires trunk-based discipline + feature flags |
CI and build infrastructure
| Capability | Polyrepo | Monorepo |
|---|---|---|
| Baseline CI cost | Low | Medium to high |
| CI cost at scale | Linear with repo count | Flat-ish with smart caching |
| Build tool complexity | Standard (npm, Maven, etc.) | Often requires Bazel / Nx / Turborepo / Pants |
| Incremental build | Limited | Core requirement |
| Test selection | Run all tests per repo | Must compute affected tests |
| Cache infrastructure | None needed | Remote cache essential (Bazel RBE, Nx Cloud) |
Deployment
| Capability | Polyrepo | Monorepo |
|---|---|---|
| Deploy a single service | Trivial | Requires path-filtering pipelines |
| Atomic multi-service release | Hard (orchestration tool) | Single merge, multi-service rollout |
| Rollback blast radius | Per service | Can be broader if not disciplined |
| Feature flagging requirement | Recommended | Effectively mandatory |
What our data shows
Context-switching is where the two architectures diverge most clearly in our IDE telemetry. Across 100+ B2B engineering teams, segmented by repository strategy:
| Team repo config | Median context switches/day | Median focus time/day | Coding time lost to re-orientation |
|---|---|---|---|
| Monorepo | 3.2 | 2h 58m | ~11% |
| Polyrepo 3-5 repos | 6.8 | 2h 12m | ~19% |
| Polyrepo 6-10 repos | 9.1 | 1h 47m | ~26% |
| Polyrepo 10+ repos | 11.4 | 1h 24m | ~32% |
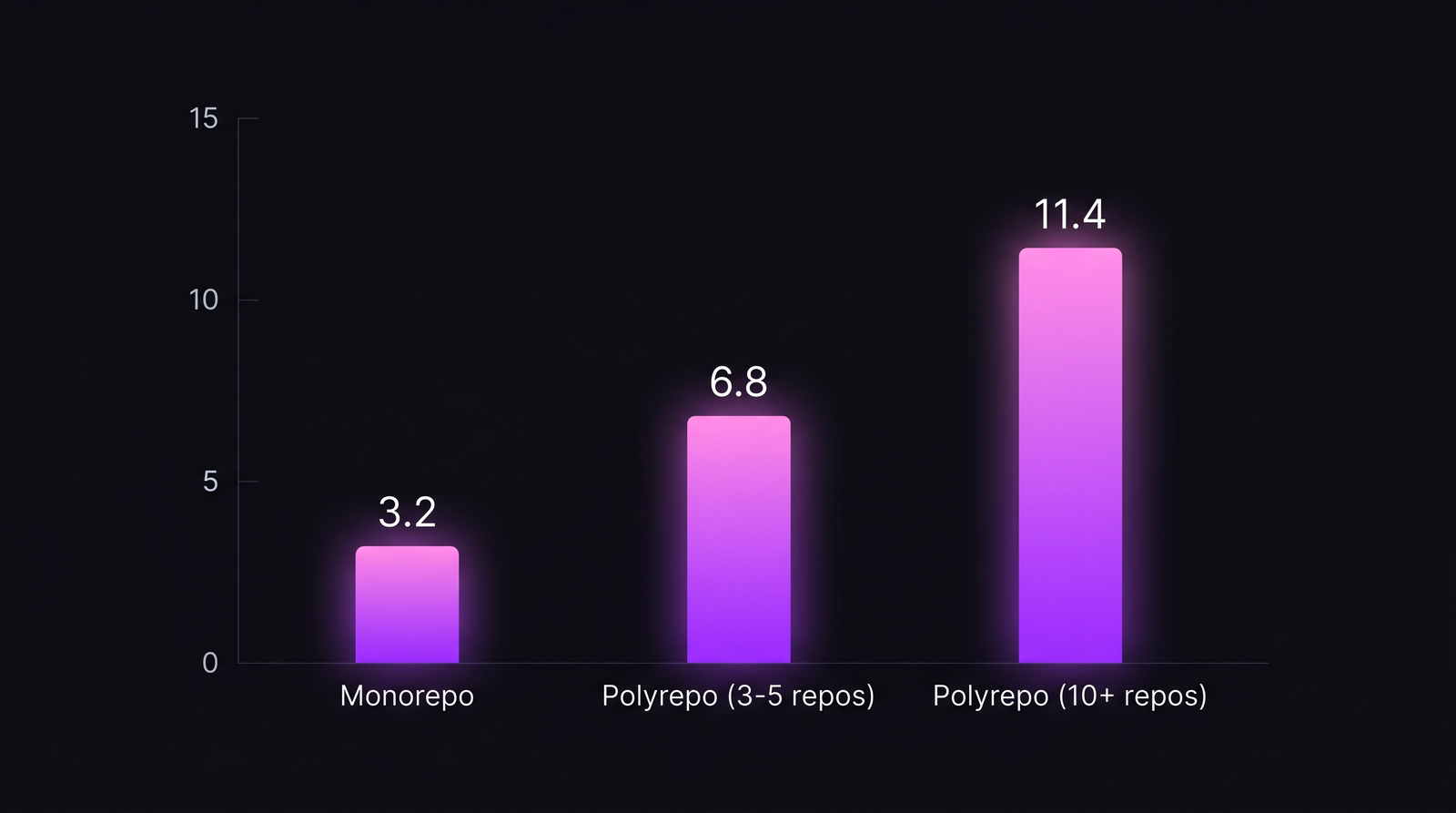 The productivity gap narrows for polyrepo shops with under 5 repos; it collapses past 10.
The productivity gap narrows for polyrepo shops with under 5 repos; it collapses past 10.
This tracks with the classic 40% context-switching tax research we've published — context switches cost the same whether they're between projects on a task tracker or between repositories on Git. The polyrepo pattern just generates more of them structurally.
Where monorepo taxes show up
| Metric | Polyrepo | Monorepo | Source |
|---|---|---|---|
| Median CI time per PR | 8-12 min | 18-35 min | Our team samples + GitHub Octoverse 2024 |
| Clone + setup time on new laptop | 10-15 min per repo | 20-45 min total | Self-reported from onboarding surveys |
| Initial cost to migrate (engineering weeks) | N/A | 12-40 weeks for mid-sized org | Various published case studies |
| Build infrastructure investment | Minimal | $50K-$500K/year depending on scale | Google / Microsoft / Uber public talks |
| Remote cache miss latency impact | N/A | Large — 5-10× slower builds | Bazel RBE, Nx Cloud docs |
Google's 2016 paper (Why Google Stores Billions of Lines of Code in a Single Repository, Potvin & Levenberg) acknowledged the CI cost openly — they built Piper and Bazel specifically because off-the-shelf tooling broke at their scale. Smaller organizations borrowing the monorepo pattern often underestimate this investment by 3-5×.
The pricing reality
Polyrepo doesn't have a monorepo-style sticker cost, but its tax lives in engineer-hours. Context switching, "which repo does that live in" Slack messages, version-drift debugging, and the infamous cross-repo refactor coordination each consume significant time invisibly.
Monorepo has an explicit tooling line-item. Reasonable ranges for mid-market teams:
| Team size | Monorepo annual infra cost (honest range) |
|---|---|
| 10-25 engineers | $10K-$30K (Nx Cloud / Turborepo Cloud, small CI fleet) |
| 25-80 engineers | $50K-$150K (Bazel RBE or similar, larger CI fleet) |
| 80-200 engineers | $150K-$400K (custom build cache, significant devprod team) |
| 200+ engineers | $400K+ (dedicated devprod team, multiple build engineers) |
Ballpark figures — actual costs depend on CI provider, build cache storage, test volume, and whether your org already has a developer-platform team absorbing some of the work.
Decision framework
Choose polyrepo if:
- You have under ~15 engineers and under ~5 services; coordination overhead is low
- Your services are genuinely independent (different languages, different teams, different deploy cadences)
- You don't have a developer-platform team (or headcount to build one)
- Strict repo-level access control is a regulatory requirement (some fintech, healthcare, defense)
- Your teams are geographically / timezone-distributed enough that rare cross-cutting changes are actually rare
Choose monorepo if:
- You have 30+ engineers working on tightly coupled domains
- Cross-cutting refactors happen more than once a month
- Shared libraries or design systems are core to your product
- You can commit to the tooling investment (build cache, remote execution, test selection)
- Your team skews language-uniform (most monorepos we see are single-primary-language)
Choose hybrid if:
- You want repo boundaries at the org-level (backend, frontend, mobile) but atomic changes within each
- "Platform / core" lives in a monorepo; independent product teams live in their own repos
- You're migrating gradually — starting with front-end or shared-library consolidation
The 80/20 analysis
Most teams under 20 engineers should stay polyrepo. The monorepo tooling investment dominates the productivity gain at that scale. Most teams above 80 engineers benefit from at least a partial monorepo — the coordination cost crosses the tooling cost around that size.
The mid-band, 20-80 engineers, is where the debate actually happens. Our data suggests the tipping point is less about engineer count and more about cross-cutting change frequency — teams doing 2+ cross-repo refactors per quarter gain meaningfully from a monorepo; teams doing fewer don't.
Common migration pitfalls
- Migrating without a build cache. Just concatenating repos into one makes CI explode. Bazel, Nx, Turborepo, or Pants are not optional; they're the migration itself.
- Ignoring CODEOWNERS rigor. Without path-based ownership, monorepo ownership becomes a mud puddle and PR review-routing breaks.
- Keeping per-service version tags. Monorepo loses most of its benefit if you re-introduce version boundaries internally. Pick: trunk-based with feature flags, or don't migrate.
- Underestimating IDE pain. IntelliJ can index a 500K-file Java monorepo; it doesn't do it fast. Budget for developer-platform time to maintain custom indexing configs.
- Not measuring before and after. Without IDE telemetry or equivalent, the claimed productivity gains are self-reported and noisy. Our IDE heartbeat data is the least-biased signal for before/after comparisons.
Summary table
| Area | Winner for < 20 eng | Winner for 20-80 eng | Winner for 80+ eng |
|---|---|---|---|
| Developer day-to-day | Polyrepo (simpler) | Depends on cross-cut freq | Monorepo |
| Coordination | Polyrepo | Depends | Monorepo |
| CI / build cost | Polyrepo | Depends | Monorepo (with tooling) |
| Ownership clarity | Polyrepo | Tie | Tie (with CODEOWNERS) |
| Cross-cutting refactor | Polyrepo painful | Monorepo | Monorepo |
| Infra investment burden | Polyrepo | Depends | Monorepo (acceptable) |
| Overall | Polyrepo | Cross-cut frequency decides | Monorepo |
The contrarian take
Most migration case studies we read claim monorepo "just works" after 6 months. Our data doesn't agree. Teams that migrate without a committed platform-team investment see productivity regress for 9-15 months, not the 3-6 months promised in conference talks. The monorepo win is real, but it's conditional on tooling maturity and a budget for a small devprod team. If you can't fund that, stay polyrepo and fix coordination with better cross-repo tooling (Shipyard, Bit, Dagger). The tool doesn't fix the organizational problem; the commitment to devprod does.
Where PanDev Metrics fits
We track context switches per developer directly via IDE heartbeat — when a dev switches between repositories, the telemetry captures it as a project-switch event. This lets teams measure the real productivity impact of migration across the cutover. A typical monorepo migration in our dataset: context switches fall within 4-6 weeks, focus time recovers by month 3, and CI frustration (measured via "waiting" time in the IDE) temporarily spikes around the cutover before stabilizing. You can see the curve, not just the destination.
An honest limit
Our data tilts toward teams of 20-150 engineers. We have fewer observations of Google/Meta-scale monorepos, so the "elite monorepo" configuration relies more on published case studies than on our direct measurement. At the other tail, solo-dev or 2-person teams rarely matter for this question — repo strategy doesn't move the needle at that size.