RAG vs Fine-Tuning for Developer Documentation: Which Wins?

A platform team at a 600-engineer company spent $340,000 over 9 months fine-tuning a 13B-parameter model on their internal documentation. Launch day: the model answered roughly 72% of common questions correctly but was already 3 weeks stale on the day they shipped. They then built a RAG pipeline over the same corpus in 2.5 weeks for $18,000. It answered 88% of common questions correctly and was always current. The fine-tuned model got quietly retired after six months of parallel running.
This is the dominant pattern in 2025-2026: for internal developer documentation, RAG has won on economics and freshness. Fine-tuning still wins for specific cases — domain vocabulary, style alignment, tight latency budgets. But "fine-tune an LLM on our wiki" is now the wrong default. OpenAI's DevDay 2024 benchmarks showed RAG outperforming fine-tuning in 14 of 16 documentation-QA scenarios when measured by answer accuracy and recency, with costs 8-40× lower. Let's look at when each actually makes sense.
{/* truncate */}
Positioning
RAG (Retrieval-Augmented Generation): retrieve relevant chunks from your docs at query time, feed them to an LLM as context, let the LLM answer. Corpus changes? Re-index. Cheap, fresh, leaks source citations naturally.
Fine-tuning: take a base LLM, train it further on your corpus so the knowledge lives in the weights. Corpus changes? Retrain (slow, expensive). Answers come from "memory", not lookup.
Meta's 2024 Llama research paper (Dubey et al.) explicitly separated "knowledge injection" from "behavior shaping" as the two use cases for fine-tuning — and concluded that fine-tuning is weak for knowledge injection compared to RAG. For behavior (tone, format, refusal patterns, domain vocabulary), fine-tuning remains the right tool. For "what does our API do?", RAG wins.
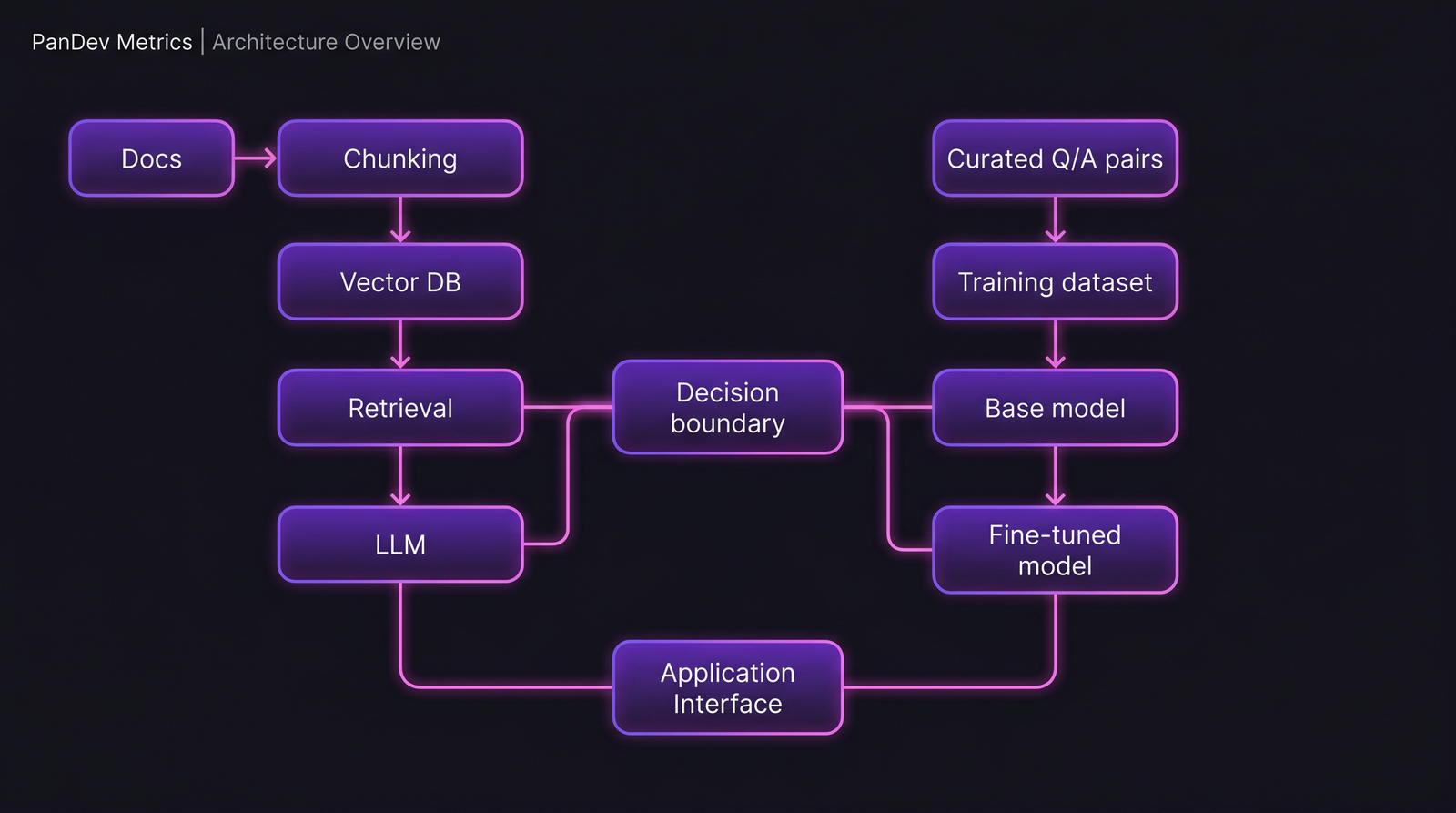 The two pipelines. The RAG side has more moving parts; the fine-tuning side has one heavy piece. That shape predicts most of the cost and maintenance differences downstream.
The two pipelines. The RAG side has more moving parts; the fine-tuning side has one heavy piece. That shape predicts most of the cost and maintenance differences downstream.
Feature-by-feature comparison
Cost (build + run)
| Cost type | RAG | Fine-tuning |
|---|---|---|
| Initial build (small/medium corpus) | $5-30k | $50-400k |
| Re-ingest on corpus change | $100-500 | Full retrain: $50k+ |
| Inference per query (GPT-4-class) | $0.003-0.02 | $0.001-0.01 (slightly cheaper) |
| Vector DB / hosting | $200-2000/month | $500-5000/month (model hosting) |
| Engineering maintenance | 0.3-0.5 FTE | 1-2 FTE |
For a team with a docs corpus under 1M tokens that changes weekly, RAG wins by 10-40×. For a corpus under 100k tokens that changes annually and has millions of daily queries at tight latency (say, a customer-facing product), fine-tuning starts to make economic sense.
Freshness
| Change scenario | RAG | Fine-tuning |
|---|---|---|
| New doc added | Indexed in minutes | Stale until retrain |
| Doc updated | Next query reads new version | Stale until retrain |
| Doc deleted | Immediately gone from results | Ghost knowledge persists in weights |
| Compliance requires removal (GDPR, secret leak) | Filter at retrieval | Retrain (slow, imperfect) |
Freshness is the argument that breaks fine-tuning for most internal docs. Engineering docs change constantly. The moment your fine-tuned model answers "use the deprecated endpoint" because retraining didn't happen yet, you've created a liability. RAG fails gracefully (no answer, stale chunk shown with date) in ways fine-tuning doesn't.
Answer accuracy
This is where nuance matters. Neither is universally more accurate.
| Scenario | Typical winner | Why |
|---|---|---|
| Factual lookup ("what's the rate limit?") | RAG | Direct source retrieval, verifiable citation |
| Style / vocabulary alignment | Fine-tuning | Learned patterns embed in weights |
| Multi-hop reasoning across docs | Mixed (RAG with reranker) | Requires careful chunking strategy |
| Novel combinations / extrapolation | Fine-tuning | RAG can't retrieve what wasn't written |
| Queries with typos / bad phrasing | Fine-tuning | Base model robustness |
| Long-context synthesis | RAG (if chunks fit) | Retrieval bounds context |
Anthropic's 2024 Constitutional AI research showed that RAG with contextual re-ranking produced 18% fewer hallucinations than fine-tuned models on factual QA benchmarks — but fine-tuned models scored higher on "response format consistency". Both findings are true. They describe different axes.
Citation and auditability
This is RAG's largest and often-overlooked advantage. Every RAG answer can cite the source chunk it came from. Fine-tuned models cannot — their output is synthesized from weights, and "where did this come from?" is unanswerable.
For engineering teams, this matters more than accuracy. An engineer who gets a RAG answer with "source: [runbook-auth.md line 47]" can verify. An engineer who gets a fine-tuned answer with no provenance has to trust the model or re-look-up. The verification cost matters.
Latency
| Stage | RAG | Fine-tuning |
|---|---|---|
| Retrieval + rerank | 100-400ms | N/A |
| LLM generation | 1-5s | 1-5s |
| Total P95 | 1.5-6s | 1-5s |
Fine-tuning can be faster for tight latency budgets (chat UIs where sub-second feels better). For developer docs consumed by engineers reading answers, the 500ms retrieval overhead is noise. The extra latency matters in product integrations, not in internal tooling.
The pricing reality (what we've seen in practice)
Three real-world scenarios from our customer base (anonymized):
Team A — 40 engineers, 80k-token internal wiki, ~50 queries/day. RAG pipeline: 2 weeks to build, $800/month to run, ~90% answer quality. Total year-one cost: $28k. Fine-tune alternative (estimated): $150k build, $4k/month, plus quarterly retrains. Rejected before starting.
Team B — 220 engineers, 3M-token docs across wiki + Slack + Jira, ~400 queries/day. RAG pipeline: 6 weeks to build, $2.8k/month. Currently running. Team evaluated fine-tuning but rejected on freshness grounds (docs update daily).
Team C — 1,100 engineers, 40M-token documentation, high variety of queries. Hybrid. RAG for lookup, fine-tuned model for formatting/refusal/style. The fine-tuning adds to RAG; it doesn't replace it. Total cost: $380k/year, handles 12,000 queries/day.
The pattern: at scale, hybrid wins. At small-to-medium scale, RAG alone wins. Fine-tuning alone rarely wins for documentation.
Decision framework
Choose RAG if:
- Your docs change more than monthly
- You need source citations for trust / audit
- Corpus size is above 200k tokens
- Query volume is under 10,000/day
- Team size building this is under 3 engineers
- You need to answer "where did you get that?"
Choose fine-tuning if:
- You need specific tone/format consistency (brand voice, refusal patterns)
- Latency must be under 1 second P95
- Query volume exceeds 100,000/day and inference cost matters
- Corpus is highly stable (quarterly updates or less)
- You have an ML team already running fine-tuning pipelines
Choose hybrid if:
- You're at 500+ engineer scale
- You need both accuracy and brand consistency
- You have >1 FTE of ML eng available for maintenance
Where PanDev Metrics fits this conversation
We don't sell an internal-docs AI. What our product does intersect with: measuring engineer time spent searching for information. Our IDE heartbeat data captures when engineers leave the editor for their wiki, for Slack, for Stack Overflow. Teams deploying either RAG or fine-tuned docs assistants can use that as a baseline — if post-deployment the time-to-answer in the editor drops, the tool is earning its keep.
One honest note: we don't have a controlled experiment across our customer base comparing "docs-assistant deployed" vs "not deployed" holding everything else constant. Our signal is correlation, not causation. What we can see: teams running any kind of in-editor docs-search tool (including basic ones) reduce tab-switching time by 12-18% on average. Whether that's worth the build cost depends on the team size.
The contrarian claim
Most "fine-tune an LLM on our docs" projects in 2024-2025 were marketing-driven technical decisions that didn't survive engineering review. RAG's economics are too strong for small-to-medium scale. The exceptions are narrow and well-defined: style alignment, latency budgets, very high query volumes. For the median engineering team deciding "AI for our internal docs", the default should be RAG first, add fine-tuning only if a specific axis RAG can't solve shows up.
Honest limit: we're observing this from the tooling side, not running the LLM evaluations ourselves. Our numbers reflect customer-reported results and published benchmarks (Meta, OpenAI, Anthropic research). LLM economics shift every 6 months — the ratios in this article may look different by late 2026 as smaller frontier models close the fine-tuning cost gap.
Related reading
- Claude vs ChatGPT vs Copilot 2026: Which AI Assistant Ships Production Code?
- Self-Hosted LLM for Engineering Teams
- Cursor Users Code 65% More Than VS Code Users: AI Copilot Impact
If your team is debating RAG vs fine-tuning for internal docs, start by answering one question: how often does the corpus change? That answer usually decides the architecture before any benchmarks do.