Self-Hosted LLMs for Engineering Teams: Cost, Privacy, Latency

A 40-engineer fintech I spoke to last month was paying $960/month for GitHub Copilot Business across their team, but their legal department had just blocked it after a compliance review flagged code-completion telemetry flowing through Microsoft's cloud. Their CTO asked me a deceptively simple question: "Can we self-host something equivalent?"
The answer is "yes, but only if you pass three filters." Stack Overflow's 2024 Developer Survey found 76% of developers use or plan to use AI tools, but adoption in regulated industries lags by 20-30 points. The gap isn't skepticism — it's infrastructure. Most engineering teams want private inference but underestimate what "self-hosted" actually costs in GPU capex, SRE time, and model-quality compromise.
This is the decision framework we hand teams considering the switch: when self-hosted LLMs beat the cloud, when they don't, and the three breakpoints that tip the math.
{/* truncate */}
The problem: cloud LLMs fail three use-cases
Copilot, Cursor, and Claude Code are excellent products for the use cases they fit. They fail predictably in three environments:
Compliance-heavy code. Banking, insurance, defense, healthcare — industries where sending production code to a third-party cloud provider violates either regulation or contract. BigCo lawyers don't want customer PII accidentally appearing in training data, and they cannot fully rule that out even with enterprise plans.
Air-gapped or data-residency-restricted environments. Government contractors, EU companies with GDPR strict-mode clients, CIS companies under local data-residency laws (Russia's 152-FZ, Kazakhstan's Law on Personal Data). These can't send bytes to api.openai.com regardless of price.
High-usage teams where per-seat pricing becomes irrational. Above ~200 engineers on heavy-completion plans, per-seat pricing exceeds the amortized cost of running your own inference cluster. The math flips.
If none of these apply to your team, stay on cloud. Self-hosting is not virtuous by itself — it's a response to specific constraints that only some teams have.
The honest cost comparison
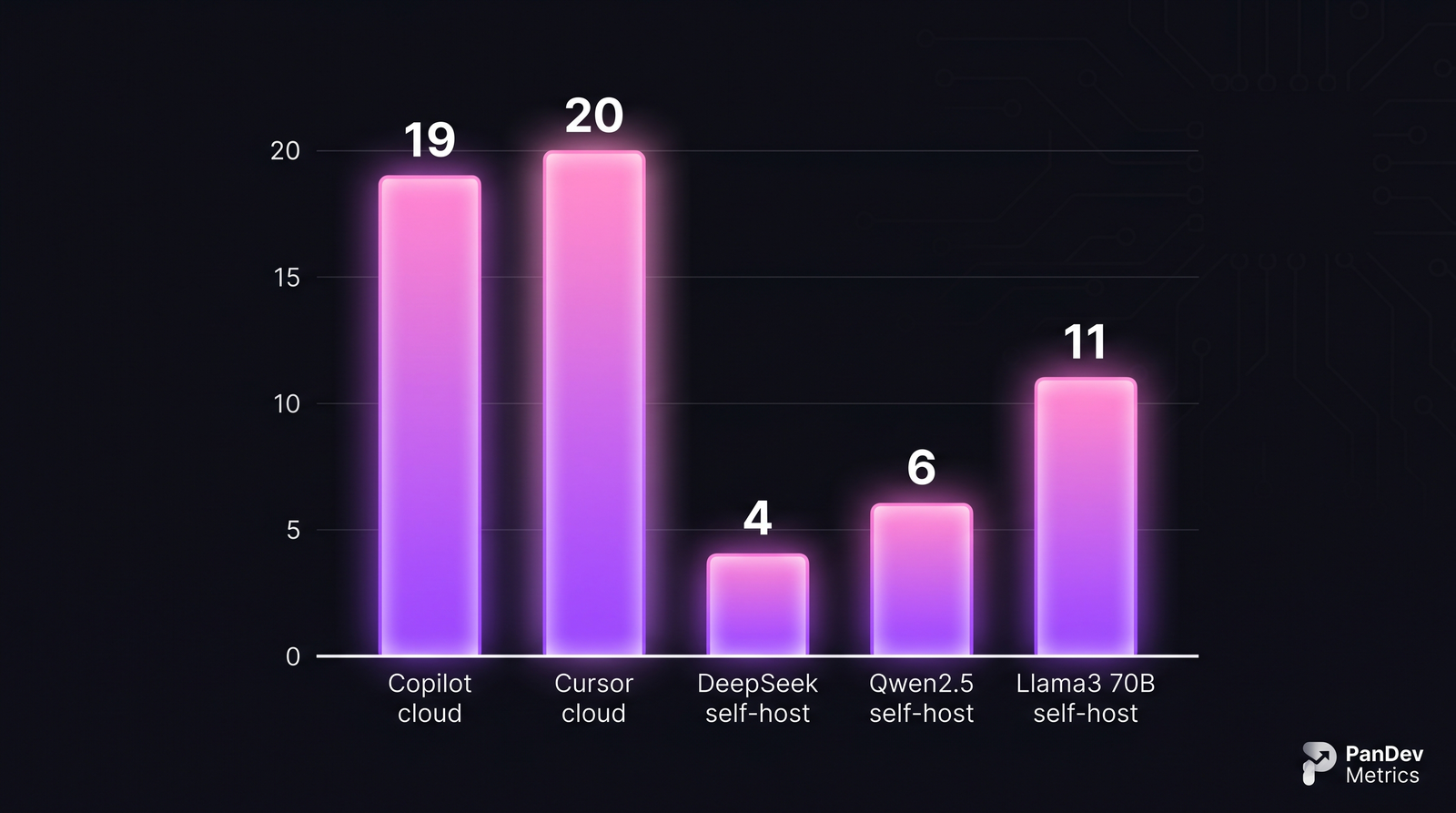 Amortized monthly cost per developer at team size of 50, assuming 24/7 inference availability. Self-hosting wins on cost only after amortization — the upfront GPU spend is real.
Amortized monthly cost per developer at team size of 50, assuming 24/7 inference availability. Self-hosting wins on cost only after amortization — the upfront GPU spend is real.
The $4-$11 self-hosted numbers are not achievable day one. They assume:
- 30-month GPU amortization. An H100 costs ~$30K; an L40S or Ada 6000 costs $6-9K. Your finance team needs to be comfortable with the capex shape.
- Power and cooling already paid for. Teams running in a colo or corporate data center have this covered; teams without infrastructure are comparing cloud-hosted inference to cloud-hosted inference, which defeats the purpose.
- One SRE at ~20% allocation. Self-hosted LLM inference needs a named owner, not "the platform team, loosely." Model updates, prompt-cache warm-ups, GPU monitoring, failover — this is real work.
If any of the three assumptions breaks, add 50-150% to the per-developer cost and re-run the math.
Per-model trade-offs (late 2026 baselines)
| Model | Licensed use | Code completion quality | RAM / VRAM required | Typical inference latency |
|---|---|---|---|---|
| DeepSeek Coder V3 236B | Commercial | Excellent (competitive with GPT-4o) | 4× H100 or 8× L40S | 300-700ms first token |
| Qwen2.5-Coder 32B | Apache 2.0 | Very good for most tasks | 1× H100 or 2× L40S | 150-400ms |
| Llama 3.3 70B Instruct | Meta License | Very good (generalist) | 2× H100 | 200-500ms |
| StarCoder2 15B | BigCode OpenRAIL | Good for FIM completion | 1× L40S | 80-200ms |
| Code Llama 34B | Meta License | OK (aging, 2023 model) | 1× H100 or 2× L40S | 250-600ms |
License matters more than most teams think. Meta's community license has headcount and revenue clauses that large enterprises sometimes cannot satisfy. Apache 2.0 (Qwen) and MIT (DeepSeek weights as of 2025) are cleanest for commercial use. Always involve legal before picking a base model for a regulated workload.
The 3-breakpoint framework
When you should self-host, in order of which test to run first:
Breakpoint 1: The regulatory test
Question: Does your compliance or legal team need to attest that production code does not traverse a third-party provider?
If yes, cost and quality are secondary. Self-host, period. The question is which model, not whether. Continue to Breakpoint 3 for model selection.
If no, continue to Breakpoint 2.
Breakpoint 2: The scale test
Question: How many developers, and how heavy is their AI usage?
Formula (rough): annual cloud cost = developers × plan_price × 12. Annual self-host cost = capex / 30 × 12 + opex × 12.
| Team size | Light users (~5 completions/day) | Medium (~50/day) | Heavy (~500/day, Cursor Pro style) |
|---|---|---|---|
| 20 engineers | Cloud wins clearly | Cloud wins | Close, cloud slightly ahead |
| 50 engineers | Cloud wins | Close | Self-host wins |
| 100 engineers | Close | Self-host wins | Self-host wins clearly |
| 200+ engineers | Self-host starts winning | Self-host wins clearly | Self-host dominates |
The table assumes single-model self-hosting. If you need two models (e.g., a fast small model for autocomplete, a large model for chat), break-even shifts up by 30-50 engineers.
If scale justifies self-host or regulatory does, continue.
Breakpoint 3: The latency + quality test
Question: What's your acceptable first-token latency, and what's the minimum completion quality your team will tolerate?
Self-hosting almost always increases first-token latency relative to Copilot (which has global POPs and aggressive caching). A 150-400ms latency is acceptable for most chat flows; for inline autocomplete, developers notice anything above ~200ms.
Your options:
- Autocomplete use case: pick Qwen2.5-Coder 32B or StarCoder2 15B. Small enough to respond fast.
- Chat / refactoring use case: pick DeepSeek Coder V3 or Llama 3.3 70B. Slower but qualitatively stronger.
- Both use cases: run both models. This is the configuration most enterprise self-hosts land on.
Model quality changes faster than this post can stay current. By the time you read this, DeepSeek Coder may have released V4 or been outclassed by a new Qwen. The framework holds; the specific picks won't. Check benchmarks (HumanEval, MBPP, SWE-bench) from the last 60 days before committing.
The step-by-step setup (practical playbook)
Step 1 — Pick the inference runtime
Your model will run on one of:
- vLLM — the default for most teams. Fast, well-maintained, supports OpenAI-compatible API.
- TGI (Text Generation Inference, Hugging Face) — stable, good for teams already in HF ecosystem.
- SGLang — newer, strong with structured output; worth evaluating if you're building tools on top of the LLM.
- llama.cpp server — for CPU-only or modest-GPU setups; quality ceiling is lower but cost is radically lower.
For production, start with vLLM unless you have a specific reason not to.
Step 2 — Pick the developer-facing interface
Your engineers are used to Copilot. They will not adopt a "paste into a web UI" workflow. You need an IDE-integrated client that points at your self-hosted endpoint. Good options:
- Continue.dev — open-source VS Code + JetBrains plugin, supports any OpenAI-compatible backend. The default choice in 2026.
- Tabby — full stack (model serving + IDE plugins), opinionated but gets you running in an hour.
- Cody Enterprise (Sourcegraph) — commercial, can point at self-hosted models; good if you already use Sourcegraph.
Your engineering team's adoption depends almost entirely on this layer, not on the model. A great model with a clumsy IDE experience gets abandoned in two weeks.
Step 3 — Build the observability loop
You will not know if the LLM is helping until you measure. Track:
- Completion acceptance rate (fraction of suggestions the developer keeps)
- Latency distribution (p50, p95, p99 first-token)
- Usage by team/project (which teams adopt, which don't, why)
- Error rate (hallucinated imports, wrong syntax for the language, out-of-context completions)
Our customers doing this well see acceptance rates of 25-40% for autocomplete on Copilot-class models; significantly lower (10-20%) on first-gen self-hosted setups before tuning. A low acceptance rate is fixable; invisible acceptance is not. The data PanDev Metrics surfaces via IDE heartbeat telemetry plus completion-event tracking makes the loop closable — you see which IDE/project/team is actually benefiting.
Step 4 — Warm the cache aggressively
Self-hosted LLMs without cache warming have brutal cold-start behavior — the first request after model swap or node restart takes seconds. vLLM and SGLang both support prefix caching; enable it and pre-warm common prompts at deploy time.
Teams that skip this step get the feedback "self-hosted LLM is slow" and blame the model. It's almost always cold cache.
Step 5 — Establish a fine-tune or RAG layer
Out-of-the-box base models don't know your internal APIs, coding conventions, or library choices. Two paths:
- Fine-tuning (Qwen2.5-Coder and Llama 3 both support LoRA adapters) — good if you have >10K repo-internal examples.
- Retrieval-augmented generation (RAG) — feed the model your internal code and docs at inference time. Simpler, less maintenance, usually works better for smaller orgs.
Most teams underestimate this step and over-deliver Step 1. A generic Qwen2.5-Coder answering questions about your 5-year-old internal Python framework produces confident wrong answers. RAG against your codebase fixes 70% of that without fine-tuning.
Common mistakes to avoid
| Mistake | Why it hurts | Fix |
|---|---|---|
| Buying H100s before piloting | Capex before signal — you don't know what model fits | Start on 2× L40S or a cloud GPU instance for 60 days |
| Letting engineers pick the model informally | 10 engineers, 7 different models, no adoption | Central decision by platform team; one or two models org-wide |
| Skipping the IDE-integration layer | Model works, nobody uses it | Budget at least as much time on Continue.dev/Tabby as on model serving |
| No RAG / no fine-tune | Confident hallucinations on internal APIs | Minimum: vector search across the top 50 repos |
| Running inference on dev-team GPUs | Contention kills latency | Separate inference cluster, full-time dedicated |
How to measure success
If you can't answer these questions 90 days after rollout, the project is in trouble:
- What's your completion acceptance rate? If under 15%, the model or the prompt layer needs work.
- What percentage of active engineers use it weekly? Under 50% is a signal the IDE integration or latency is hurting adoption.
- What's the cost-per-active-user? Comparing to the cloud alternative is the CFO-facing justification.
PanDev Metrics tracks IDE session activity including whether AI-assist plugins are installed and actively emitting events; we also see which languages and projects get heavy AI-completion activity versus which don't. The data lets an engineering leader answer "is the LLM helping team A but not team B, and why?" — which is a more actionable question than "what's the average acceptance rate?"
The contrarian claim
Most "self-hosted LLM for developers" guides talk about model quality. I claim quality is the third most important factor, after IDE integration and cache warming. A mid-tier model with excellent tooling beats a top-tier model with a clunky plugin, every time. Teams that fail at self-hosted LLMs usually fail at the workflow layer, not the weights layer.
Corollary: if your engineering team has been using Copilot or Cursor for 6+ months, your implicit baseline for "good AI coding assist" includes the IDE experience, not just model quality. Match that baseline or adoption collapses.
When self-hosting doesn't fit
Three scenarios where staying on cloud is the right call:
- Under 50 engineers with no regulatory constraint. Cloud cost is lower, quality is higher, your team has better things to do.
- Team without a platform engineer or SRE. Self-hosted LLMs need an owner. If nobody has 20% capacity, don't start.
- Organization where AI tool adoption is still debated. Don't solve infrastructure problems before you've solved adoption problems. Use cloud to prove value, then consider the move.
The honest limit
Our dataset covers IDE usage patterns, plugin adoption, and language distribution across 100+ B2B companies. What we don't have is direct telemetry on completion acceptance rates for self-hosted LLMs at scale — that data lives in the inference stack (vLLM, TGI), not in the IDE heartbeat. The acceptance-rate numbers above come from customer interviews and public vendor data (Tabby, Continue.dev benchmarks). Treat them as starting references, not measured truth in your environment.
Related reading
- Cursor Users Code 65% More Than VS Code Users: AI Copilot Impact — the measured impact of cloud AI tools on coding volume
- VS Code vs JetBrains vs Cursor 2026 — which IDE environment your self-hosted model will need to integrate with
- On-Premise Deployment: PanDev Metrics With Docker and Kubernetes — the deployment model compliance-heavy customers use for engineering-intelligence telemetry
- External: vLLM documentation — the canonical reference for high-throughput LLM serving in 2026