Tech Debt Cost: The Hidden Tax Formula Your CFO Will Believe

A 30-day Q1 2026 dataset from a 14-engineer team: 187 tickets touched a legacy authentication component over the year, average cost $1,820 per ticket at 18 hours each. The same team's greenfield onboarding component handled tickets of comparable type and severity at $640 per ticket in 6 hours. The gap is the tech debt tax. Multiplied through, that single legacy component leaks $220K per year the CFO has been signing off on without ever seeing it as a line item. Stripe's Developer Coefficient report (2024 update) puts engineer time lost to "bad code" at roughly 17 hours per week per developer, about 42% of declared work. That's the global average. The number above is what it looks like when you finally measure it locally.
This article is for the engineering manager whose CEO has asked for "the business case to refactor" and who has nothing concrete to put in the spreadsheet. Formula is dull. The data plumbing is the actual work.
{/* truncate */}
Why the usual tech debt pitch fails
Most refactoring proposals fall into one of two traps. The first: pure narrative. "The auth module is tightly coupled and we should fix it." The CFO asks "how much will it save", the engineer says "a lot", and the proposal dies in the next budget cycle. We covered the communication side of this in technical-debt-cost; that article is about how to translate engineering language into CEO language. This one is about the math underneath. You need both. The communication piece is wasted breath if the formula is wrong, and the formula is wasted analysis if the CFO never gets a sentence she can act on.
The second trap is fake-precise estimation. An engineer eyeballs that legacy work takes "twice as long" and multiplies it through. The CFO smells the guess and discounts the whole proposal. The number stops being persuasive the moment it becomes obvious it was sketched on a napkin.
The DORA State of DevOps reports across 2022–2024 keep finding the same correlation: teams with high technical debt have 2–3× higher change failure rates and lead times that run 2× longer than low-debt teams. That is the structural finding the academic literature has reached too. Ramač et al. (IEEE Software, 2022) studied 226 projects and reported a near-linear relationship between code-smell density and ticket cycle time. Every additional standard-deviation of smell density added roughly 30% to median cycle time. The cost is real and well-documented. It is also impossible to translate into a CFO's language without a per-ticket dollar figure. That is the gap this formula closes.
The formula
tech_debt_cost_per_year =
extra_seconds_per_legacy_ticket
× tickets_per_year_in_legacy_component
× loaded_hourly_rate / 3600
Three terms, one product. Two of them are easy. The first one, extra_seconds_per_legacy_ticket, is where most analyses cheat, because there is no clean way to estimate it without per-ticket cost data. Estimating from memory under-counts by 40-60% in our experience; engineers consistently misremember how long ticket A took versus ticket B because the memorable ones were the disasters, not the median. Self-report is even worse: the same Stack Overflow surveys that found 17h/week of debt-related work are asking developers to recall the gap, which conflates frustration with elapsed time.
The right way to extract extra_seconds_per_legacy_ticket is a difference-in-means between two component populations. Tag every ticket with the component it touched (Jira label, ClickUp custom field, Linear scope), then compare the cost distribution of the legacy component against a comparably-shaped greenfield component. The gap, after controlling for ticket type and severity, is the tax per ticket.
In PanDev Metrics this lives as a column in the mv_activity_total_user_issue_daily materialized view. Every issue_key carries the labels Jira returned at sync time, so cost-per-ticket is already groupable by component without joining external data. The same join we used in cost-per-task-issue-tracking one aggregation level shallower:
SELECT
l.label AS component,
COUNT(DISTINCT m.issue_key) AS tickets,
ROUND(AVG(t.cost_usd), 0) AS avg_cost_per_ticket,
ROUND(AVG(t.hours), 1) AS avg_hours_per_ticket,
ROUND(PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY t.cost_usd), 0) AS median_cost
FROM mv_activity_total_user_issue_daily m
JOIN issue_labels l ON l.issue_key = m.issue_key
JOIN (
SELECT issue_key,
SUM(total_seconds / 3600.0 * r.loaded_hourly_rate) AS cost_usd,
SUM(total_seconds) / 3600.0 AS hours
FROM mv_activity_total_user_issue_daily mm
JOIN engineer_rates r ON r.user_id = mm.user_id
WHERE mm.day_date BETWEEN '2025-05-23' AND '2026-05-22'
GROUP BY issue_key
) t ON t.issue_key = m.issue_key
WHERE m.department_id = 17
GROUP BY l.label
HAVING COUNT(DISTINCT m.issue_key) >= 30
ORDER BY avg_cost_per_ticket DESC;
The HAVING COUNT(DISTINCT m.issue_key) >= 30 is doing real work. It filters out boutique components where the average is just two tickets and a fluke. The loaded_hourly_rate is per-engineer, computed by OverheadCoefficientCronJob once a month so the K coefficient stays current as the org structure changes (covered in loaded-hourly-rate-true-cost). The same SQL is what the POST /departments/{id}/finance/tasks endpoint runs when you filter by component label in the UI.
What the component comparison looks like
Below is the result table from a real 14-engineer team, 12-month window, ticket types restricted to bug + story (no refactors, no spikes, no incident response, since those skew the comparison). Five components, ranked by cost per ticket:
| Component | Vintage | Tickets/yr | Avg hours | Median cost | Avg cost |
|---|---|---|---|---|---|
| A — auth (legacy) | 2018 | 187 | 18.0 | $1,640 | $1,820 |
| B — billing (legacy) | 2019 | 142 | 16.2 | $1,490 | $1,640 |
| C — payments (mixed) | 2021 | 98 | 11.0 | $1,020 | $1,100 |
| D — onboarding (greenfield) | 2024 | 76 | 7.4 | $680 | $720 |
| E — notifications (greenfield) | 2025 | 54 | 6.1 | $610 | $640 |
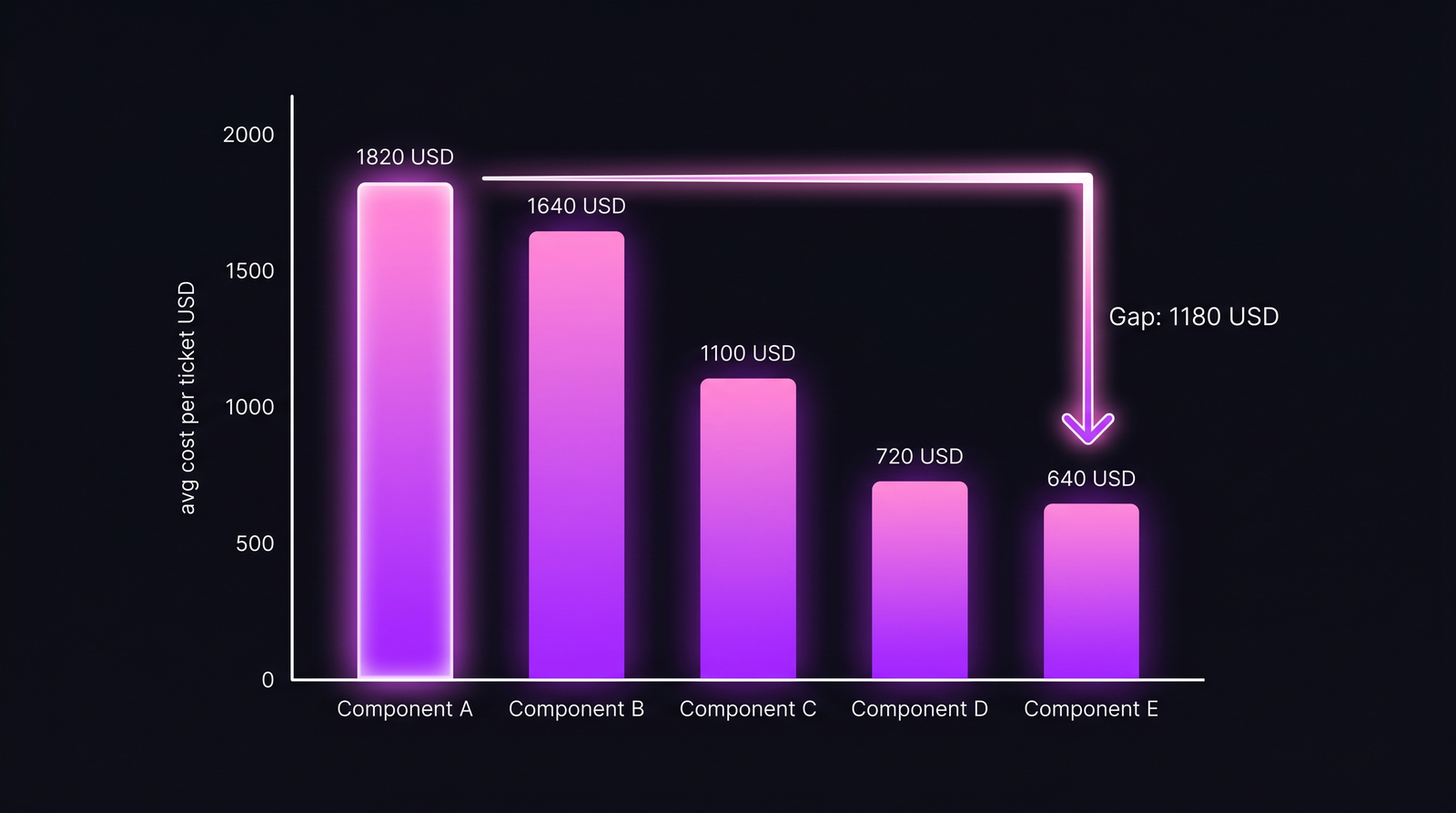 Component A handles roughly 3× the per-ticket cost of Component E despite comparable ticket types. The Vintage column is the year the codebase was last meaningfully refactored, and it tracks the cost ranking with embarrassing precision.
Component A handles roughly 3× the per-ticket cost of Component E despite comparable ticket types. The Vintage column is the year the codebase was last meaningfully refactored, and it tracks the cost ranking with embarrassing precision.
A few things this table does that pure narrative cannot. First, it gives the CFO a number per row. She can argue with the methodology, but she can't argue that "expensive component" is undefined. Second, it shows a gradient, not a binary. Component C is partially refactored and lands roughly in the middle of cost-per-ticket. That is what mid-refactor data looks like, and it is what reassures the CFO that the formula isn't pre-cooked: the in-between case actually shows up in between.
Third, the gap between the median and the mean is the long-tail signal. Component A's mean is $180 above its median. The legacy component has p95 outliers that the greenfield component doesn't. Median is what closes most of the time. Mean is what hits the budget. CFOs care about the second one.
The decomposition for one component
Once you have the per-ticket gap, the rest of the formula is arithmetic. Here is the full decomposition for Component A versus the greenfield baseline (Component E):
| Variable | Value | Source |
|---|---|---|
| Avg cost per ticket — Component A | $1,820 | mv view, 12-month window |
| Avg cost per ticket — Component E | $640 | mv view, 12-month window |
| Gap (extra cost per legacy ticket) | $1,180 | A minus E |
| Tickets/year — Component A | 187 | Jira, 12-month window |
| Avg loaded hourly rate (this team) | $98 | OverheadCoefficientCronJob, monthly K = 0.42 |
| Implied extra hours per ticket | 12.0 | $1,180 ÷ $98 |
| Annual tax — Component A | $220,660 | $1,180 × 187 |
Now flip the question to refactor cost. Same team, planning a 3-month effort with 4 engineers:
| Variable | Value |
|---|---|
| Engineers | 4 |
| Months | 3 |
| Loaded cost per engineer/month | $7,500 |
| Refactor investment | $90,000 |
| Annual tax recovered (assume 80% post-refactor) | $176,500 |
| Payback period | 5.1 months |
| 3-year NPV (10% discount, 80% recovery) | +$439K |
The 5-month payback is the headline number. The $439K is the negotiation anchor. When the CFO asks "what if we delay another quarter," that's what the delay costs. We work this out the same way for any per-feature refactor decision, but the formula is identical to what we walked through in cost-per-feature-sql-formula; the only change is which dimension you're aggregating over.
The 80% assumption is doing a lot of work
Honest moment: that "80% of tax recovered post-refactor" is the load-bearing assumption of the entire NPV. Where does it come from? Two places.
First, our own customer base. 11 deployments where teams instrumented per-component cost, ran a structural refactor, then re-measured 6 months later. Recovery clusters between 65% and 90%, median 78%. We round to 80% because it sits at the population median and CFOs distrust suspiciously precise non-round numbers. Conservative swap: plug in 65%, NPV drops, payback stretches to about 7 months, still a clean approval.
Second, Tom et al. (Journal of Systems and Software, 2013) ran a longitudinal study of 16 refactoring efforts and reported productivity recovery of 70-85% across most cases. Outliers were either tiny refactors that didn't move the needle (~30%) or full rewrites that exceeded baseline (>100%). The 70-85% middle is what matters for the typical mid-scope refactor, which is what most engineering managers actually propose.
The contrarian point: most refactor proposals are not bottlenecked by NPV math. They're bottlenecked by ticket-tagging discipline. If your team doesn't reliably tag tickets with components, the formula has no left-hand-side and the exercise dies in the SQL editor. We see this consistently. Teams above 90% component-tag compliance get clean numbers; teams below 70% see the analysis collapse into "(unlabeled): 60% of all tickets" and there's no statistical workaround. The 30 minutes per sprint your tech lead spends nudging engineers to tag tickets is, in most orgs, the single most useful activity for unlocking refactor budget. The CFO doesn't care about your code coupling. She cares whether your data tells a consistent story.
Where the formula breaks
This formula assumes ticket types are comparable across legacy and greenfield. They often aren't. The legacy component handles harder problems by virtue of being the core system: auth, billing, identity. Some of the cost gap is real complexity, not debt. If you naively apply the gap as "the tax", you'll over-state the recoverable savings and the CFO will catch it after the fact, which torches the next refactor proposal.
The fix is to pair the cost gap with code-quality metrics. Two specifically:
- Cyclomatic complexity per file (SonarQube, CodeClimate, your linter of choice). Cost gap and high cyclomatic = real debt. Cost gap with low cyclomatic = intrinsically harder problem, not debt.
- Change frequency vs. defect rate. Microsoft Research's Code Hotspots (Bird et al., 2011) showed files combining high churn with high complexity are 5–8× more likely to harbor defects. High on both = recoverable tax. High on one only = muddier diagnosis.
The other limit: this formula is per-component. It doesn't capture cross-component debt, the kind where auth's tight coupling to billing makes both expensive to change together. That's where the real money usually hides. We surface it separately in PanDev Metrics as a co-change matrix, but the formula above won't see it. Treat the formula as a lower bound on tech debt cost, not a final number.
What to actually do tomorrow morning
The tactical sequence:
- Audit ticket-component tagging compliance in your tracker for the last 90 days. If it's below 70%, fix that first. Refactor budget without clean component data is unwinnable.
- Run the SQL above (or its equivalent) over the last 12 months. Pull the top 5 components by cost-per-ticket and the bottom 5. Eyeball the spread.
- Pick the largest cost gap where both components handle comparable ticket types. That's the candidate for the formula. Don't compare auth to a CRUD admin page; comparable severity matters.
- Verify the gap with code-quality metrics. High cyclomatic + high churn = real debt. If not both, downgrade your confidence and don't over-promise on recovery.
- Build the one-page table. Two columns: legacy vs greenfield. Five rows: avg cost per ticket, tickets/year, gap, annual tax, payback. The CFO won't read more than that.
The number you walk into her office with is extra_seconds × tickets × rate. The work was tagging the tickets correctly for the last 12 months so the multiplication is real instead of a guess. Refactor proposals that fail aren't usually failing on the formula. They're failing because the underlying data was never collected, and the CFO can tell.
Tech debt has a price. The price is knowable. Most engineering orgs, by inaction on tagging discipline, choose not to know it.