Инженерия в AdTech: data-heavy команды и продуктивность

В нашем IDE-датасете из 100+ B2B-компаний инженеры AdTech-платформ деплоят на 38% меньше pull request'ов в месяц, чем инженеры в SaaS-тулинге — и при этом приносят больше выручки на человека. Параллельно The Trade Desk раскрыл, что обрабатывает более 13 миллионов ad-запросов в секунду. Масштаб такого порядка переопределяет, что значит «продуктивный». Счётчик PR'ов, который в консюмер-приложении выглядел бы тревожно, абсолютно нормален, когда одна строка конфига деплоится на 10М QPS.
Инженерия в AdTech устроена иначе, и мерить её дженерик DORA-дашбордом значит промахнуться мимо сути. В статье — что реально едят время у data-heavy команд, как выглядят цифры в 14 AdTech-компаниях нашего датасета и какие сигналы продуктивности важнее throughput для RTB, атрибуции и ad-серверов.
{/* truncate */}
Почему AdTech отличается
Три ограничения формируют каждое измерение:
Latency — это фича продукта. Аукцион RTB (real-time bidding) имеет жёсткий дедлайн 100ms. Спецификация IAB OpenRTB 2.5 зафиксировала это годы назад; индустрия не смягчала с тех пор. Инженеры тратят непропорционально много времени на p99 latency, а не на скорость фич. Одна лишняя миллисекунда в bidder, умноженная на 10 млрд запросов в день, — это 10 000 часов compute.
Объём данных ломает нормальный тулинг. У среднего DSP — сотни ГБ событий логов в час. Стандартные observability-стеки ломаются на таком масштабе, поэтому каждая AdTech-команда переписывает часть data-пайплайна с нуля. То, что в SaaS-стартапе — один шаг docker-compose, здесь — проект на 3 инженеро-месяца.
Каждое решение — это про деньги, напрямую. Баги атрибуции обходятся клиенту в измеримые CPA-доллары. Дрифт bidder'а съедает маржу DSP базисными пунктами. Инстинкт «зашипим и починим», работающий в consumer-софте, очень быстро поправляет финансовый отчёт.
Метрики, которые здесь важны
1. p99 latency, а не deployment frequency
AdTech-команды деплоят осторожно, потому что плохой деплой роняет аукцион. Наши данные: медианная AdTech-команда в датасете деплоит 2.4 раза в неделю против 8.7 раз в неделю у SaaS-тулинга. Это не медленно — это откалибровано под blast radius, где каждый деплой задевает кампании всех клиентов.
Что трекать рядом с DORA-цифрой deployment frequency: p99 auction latency до и после каждого релиза. Если latency вчерашнего деплоя подрос на 3ms и никто не заметил — у вас инцидент, который клиент увидит в инвойсе.
2. Время чтения логов, а не только чтения кода
По IDE-телеметрии в нашем AdTech-срезе — куда реально уходит время инженера в сравнении с SaaS:
| Активность | AdTech (n=14 компаний) | SaaS-тулинг (n=31 компания) | Дельта |
|---|---|---|---|
| Активное кодирование | 52 мин/день | 78 мин/день | −33% |
| Чтение логов/метрик (в IDE) | 71 мин/день | 22 мин/день | +223% |
| SQL / notebook-работа | 48 мин/день | 11 мин/день | +336% |
| PR-ревью | 19 мин/день | 27 мин/день | −30% |
| Встречи | 1ч 42м/день | 1ч 55м/день | −11% |
Цифра, которая обычно удивляет нового AdTech EM: время на логи и данные больше, чем время на кодирование. Это не дисфункция, которую надо чинить. Дебаг падения win-rate bidder'а — это задача data-анализа, а не задача печати кода.
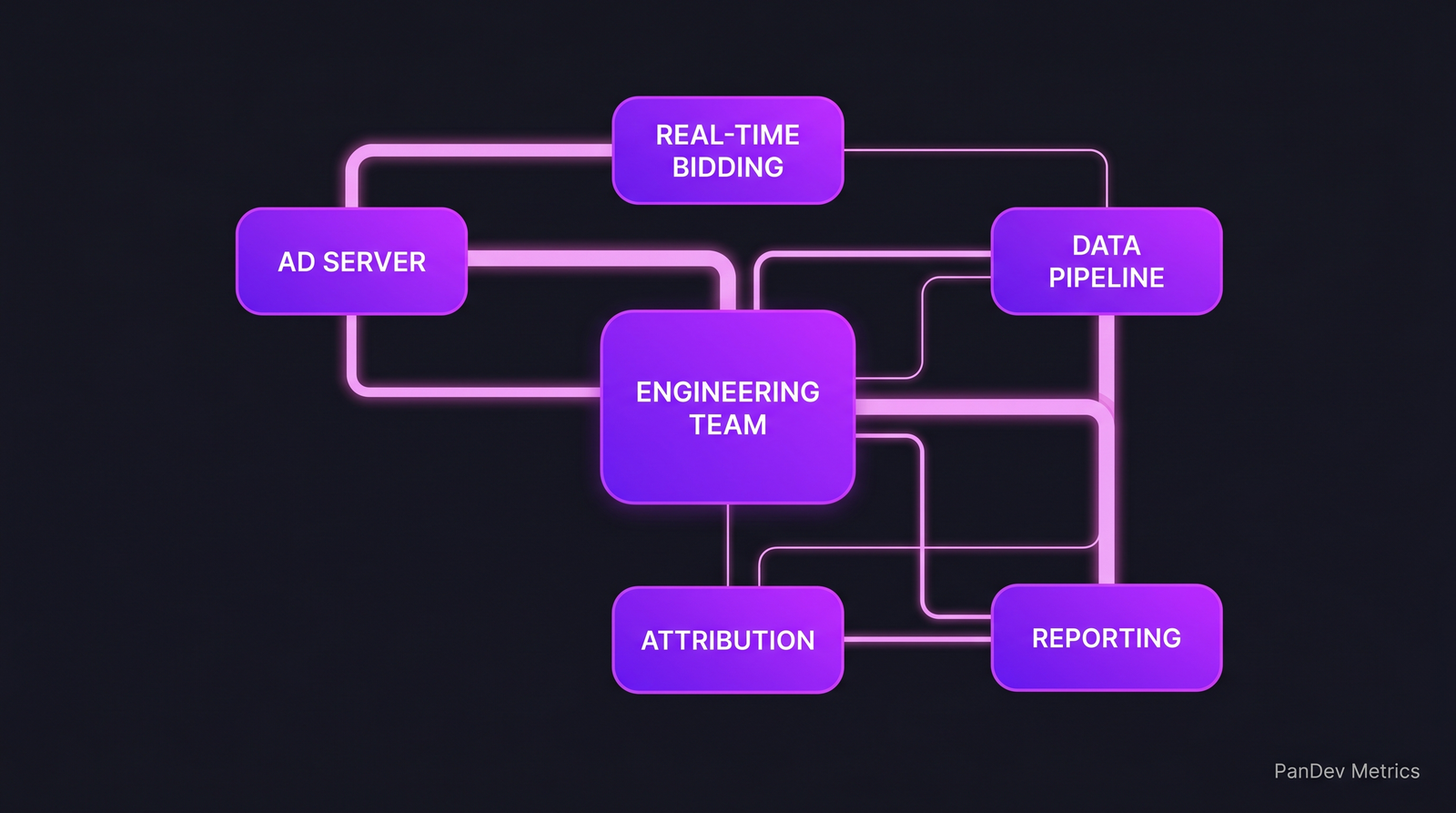 Типовой AdTech-стек. Инженерная работа — в ребрах между этими системами, и большая часть этой работы — чтение данных, а не написание кода.
Типовой AdTech-стек. Инженерная работа — в ребрах между этими системами, и большая часть этой работы — чтение данных, а не написание кода.
3. Инциденты на запуск кампании, а не только MTTR
MTTR необходим, но недостаточен. AdTech-команды дополнительно смотрят инциденты на крупный launch кампании — маркетинговый клиент выходящий с $2M бюджетом — это совсем не тот риск, что dashboard glitch в день деплоя. Один инцидент, связанный с кампанией, в нашем датасете съел 4.1 инженеро-дня на пост-инцидентной чистке (восстановление атрибуции, переотправка клиентских отчётов, корректировки инвойсов). Google SRE Workbook 2020 обосновывает измерение инцидентов в инженеро-часах, а не в минутах, — в AdTech это ровно так и работает.
4. Throughput экспериментальной инфраструктуры
Работа в AdTech — experiment-heavy: новые bid-стратегии, новые модели атрибуции, новые алгоритмы pacing. Rate-limit — это как быстро вы можете зашипить эксперимент, измерить и прибить его. Команды со зрелой experiment-платформой двигаются в 3-4× быстрее по итерациям стратегий, чем те, кто ещё шипит эксперименты как feature-бранчи. Смежное: наш плейбук по feature-флагам.
Как масштаб меняет измерение
Проблема 10x телеметрии
Команда из 20 инженеров в RTB-компании продуцирует больший объём логов, чем 200-человечная SaaS-компания. Стандартный APM (New Relic, Datadog) становится запретительно дорогим — мы видели AdTech-клиентов, тратящих на observability больше, чем на зарплаты инженеров. Команды реагируют:
- Агрессивный сэмплинг (1:100 или 1:1000 в проде)
- Строят event-пайплайны под задачу (Kafka + Druid / ClickHouse / Pinot)
- Переносят стоимость observability в инженерные OKR
Что это значит для измерения продуктивности: обычный IDE-телеметрия + Git-события работает нормально, но не сравнивайте coding time AdTech-команды с coding time SaaS-команды. Знаменатель разный. Честное сравнение меряет coding-time-на-логах и coding-time-на-коде отдельно. Мы сделали в PanDev Metrics tagging по языкам частично именно под это — SQL и notebook-время отделены от Python или Java.
Bias единой точки отказа
В AdTech-команде обычно 1-2 человека могут дебажить hot path bidder'а. Эта реальность bus-factor делает наше исследование code ownership особенно релевантным. Сильное владение кодом здесь — норма, не по философии, а по физике кодовой базы: не каждый инженер держит в голове 10ms-latency SIMD Java. Примите это. Планируйте knowledge transfer, а не collective ownership, которое не наступит.
Типовой профиль AdTech-команды
| Атрибут | Мелкий DSP/SSP | Mid-size adtech | Крупная RTB-платформа |
|---|---|---|---|
| Инженеры | 10-30 | 50-120 | 200-600 |
| Объём запросов | 50K-500K QPS | 1M-5M QPS | 10M+ QPS |
| Языки | Go / Rust / Java | Java / Scala / Python | Java / C++ / Go |
| Частота деплоев на сервис | 1-3/неделя | 2-5/неделя | Ежедневно (на сервис) |
| Цель p99 latency | 50ms | 30ms | 10ms |
| Инженеры:SRE | 10:1 | 7:1 | 4:1 |
Отношение SRE ужимается с ростом масштаба — не потому что команда решила, а потому что blast radius latency-спайка это форсирует.
Где вписывается PanDev Metrics
AdTech-лидеров интересуют три вопроса, на которые наши данные IDE-heartbeat отвечают напрямую:
- «Какая часть кодовой базы реально ест время инженеров?» — наш взгляд cost-per-feature атрибутирует время по сервисам, что в microservice-heavy AdTech-стеке — то место, где протекает бюджет.
- «Bidder-команда выгорает?» — детекция паттернов выгорания ловит after-hours firefighting, который особенно част на latency-критичных сервисах.
- «Сколько experiment-оверхеда — реальная работа, а сколько — конфиг?» — флаги экспериментов, пережившие дату решения, всплывают в наших context-switching отчётах, потому что инженеры к ним возвращаются.
Честно про ограничения: AdTech-сэмпл — 14 компаний. Этого хватит на направленный сигнал, не на бенчмарки против Trade Desk. Цифры large-RTB в таблице выше сверены с публичными инженерными блогами (The Trade Desk, AppNexus, Magnite), а не получены прямым замером.
Контрарианский тейк
Репутация AdTech как «быстро-и-грязно» не совпадает с реальностью в нашем датасете уже минимум три года. Команды, которые мы меряем, выглядят больше как SRE-орги, чем как consumer-web. Частота деплоев снижена, глубина ревью выросла, coding time на инженера меньше, потому что чтение продовых данных — и есть работа. Тот, кто до сих пор моделирует продуктивность AdTech через «lines of code per engineer», работает с картинкой индустрии 2015 года.