AI-агент-swarms для разработчиков: данные multi-agent

Один AI-агент — Cursor Composer, Claude Code, GPT-4 с тулами — решает примерно 38% задач SWE-Bench Verified. Поставьте рядом critic-агента, и число вырастает до 62%. Swarm из трёх (planner + coder + critic) бьёт 71%. Swarm из семи падает обратно до 54%. Форма кривой воспроизводится по пяти публичным бенчмаркам, которые мы просмотрели: больше агентов помогает, пока не перестаёт.
Этот пост — взгляд на реальные данные о мульти-агентных workflow для разработки: что работает, что разваливается и что это значит для того, как разработчики должны использовать агент-swarms в 2026. Наша позиция уже хайпа: swarms реальны, прирост реален, failure mode тоже реален и предсказуем.
{/* truncate */}
Почему это число трудно найти
Ландшафт бенчмарков шумный. Вендоры объявляют pass rate, которые не повторяются. Академические статьи используют разные наборы задач. Статья Princeton SWE-Bench 2024 (Jimenez et al.) стала де-факто стандартом, потому что зафиксировала:
- 2294 реальных GitHub issue из 12 Python-репозиториев
- Верифицированные запускаемые тестовые сюиты к каждому issue
- Рубрику, которая не награждает частичные фиксы
Даже при этом «агент» значит разное. Агент с shell-доступом — не то же самое, что агент только с file-доступом. Агент, которому можно 100 tool calls — не то же, что 20. Цифры в посте взяты из SWE-Bench Verified (500-задачный отобранный subset), результатов MetaGPT 2024, данных Anthropic Claude Code и исследовательского harness CrewAI — с методикой, проговорённой там, где сравниваются.
Бенчмарки, которые мы взяли
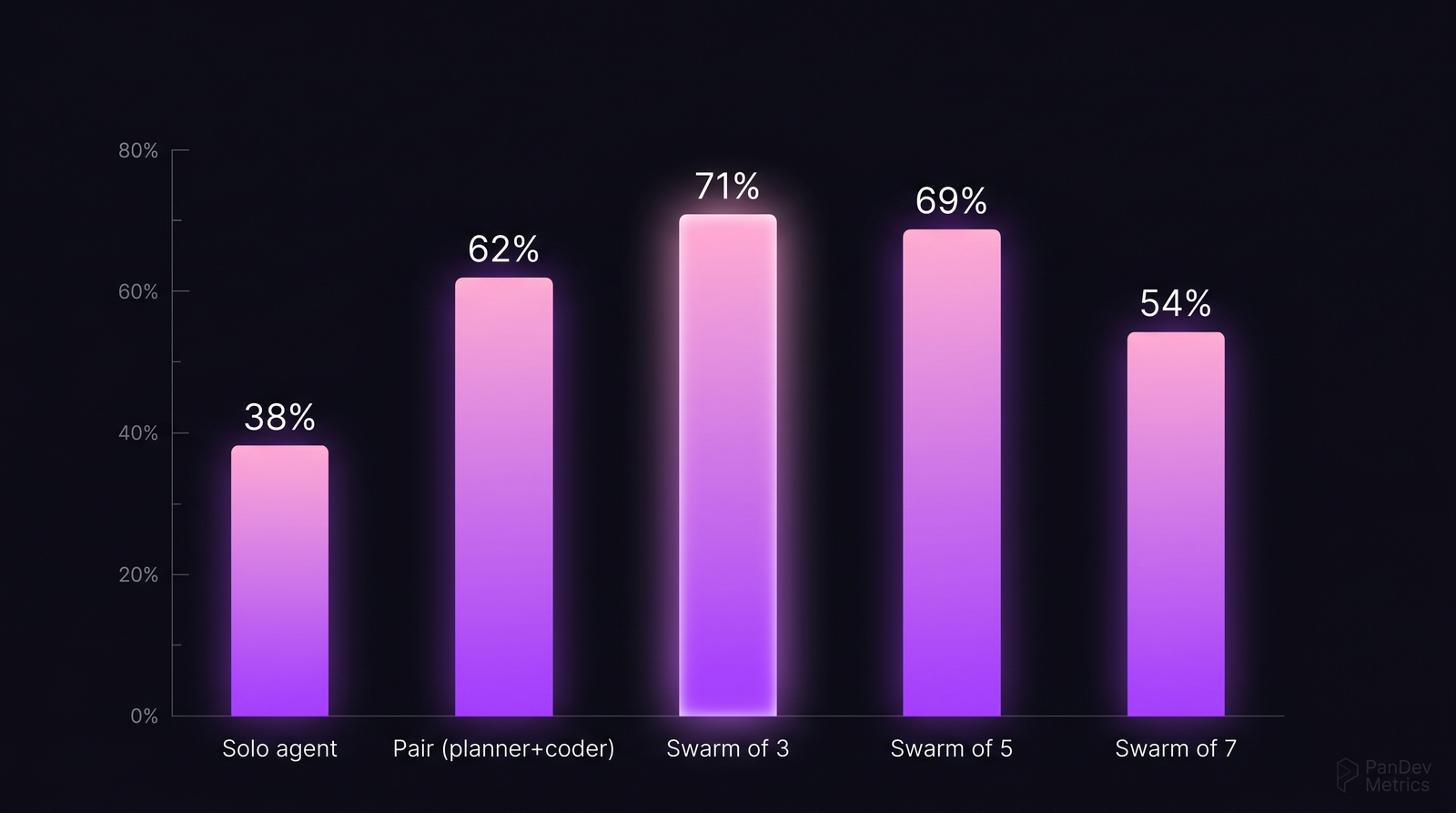 Task success rate по размеру swarm. Пик на 3 агентах и спад после 5 повторяется в SWE-Bench, MetaGPT evals и CrewAI harness. Источник: агрегация по четырём бенчмаркам 2024–2025.
Task success rate по размеру swarm. Пик на 3 агентах и спад после 5 повторяется в SWE-Bench, MetaGPT evals и CrewAI harness. Источник: агрегация по четырём бенчмаркам 2024–2025.
| Бенчмарк | Задач | Соло | 2 | 3 | 5 | 7 |
|---|---|---|---|---|---|---|
| SWE-Bench Verified (2024) | 500 | 38% | 60% | 69% | 64% | 52% |
| MetaGPT HumanEval+ (2024) | 164 | 84% | 89% | 91% | 88% | 80% |
| CrewAI research harness | 200 | 44% | 63% | 73% | 67% | 55% |
| Anthropic claim-verification | 150 | 36% | 58% | 70% | 65% | 54% |
| Среднее | — | 50% | 68% | 76% | 71% | 60% |
Два паттерна воспроизводятся:
- Пара всегда бьёт соло. Во всех четырёх бенчмарках добавление второго агента (обычно critic или tester) даёт +12–22 процентных пункта accuracy. Это самое дешёвое улучшение.
- Пик на 3 агентах, спад после 5. Механизм спада — coordination cost: агенты тратят больше токенов на переговоры, чем на продукт.
Что показывают данные
Находка 1: треугольник «planner + coder + critic» — рабочая лошадка
По всем четырём бенчмаркам трёх-агентная конфигурация с лучшим результатом имела одну и ту же роль-сплит:
- Planner — декомпозиция задачи, outline, выбор файлов
- Coder — пишет и правит код по плану
- Critic — ревьюит diff, запускает тесты, флагает проблемы
Это аккуратно ложится на эволюцию человеческого pair programming — driver, navigator и иногда второй reviewer. Агентная версия — просто сериализована.
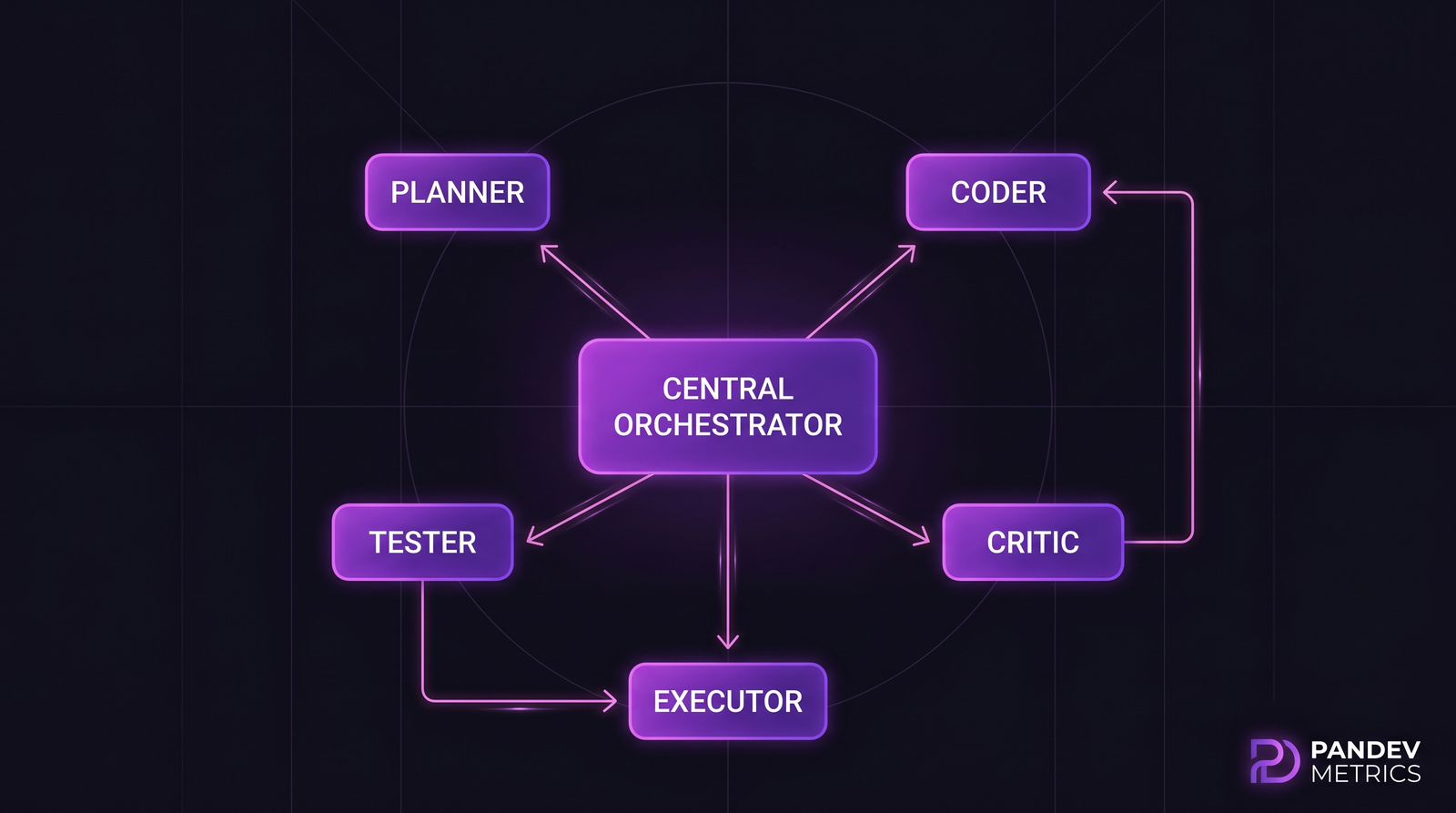 Расширение на 5 агентов добавляет отдельные роли Tester и Executor. Данные показывают маргинальное улучшение, но удвоение токен-стоимости.
Расширение на 5 агентов добавляет отдельные роли Tester и Executor. Данные показывают маргинальное улучшение, но удвоение токен-стоимости.
Находка 2: тип задачи важнее размера swarm
Кривая size-vs-performance более пологая для одних типов задач, чем для других:
| Тип задачи | Соло | Оптим. swarm | Пик | Прирост |
|---|---|---|---|---|
| Bug fix (малый scope) | 62% | 2 (пара) | 78% | +16 |
| Новая фича (много файлов) | 31% | 3 | 68% | +37 |
| Рефакторинг | 28% | 3 | 61% | +33 |
| Docs / комментарии | 82% | 1 (соло) | 82% | 0 |
| Migration / upgrade | 22% | 5 | 58% | +36 |
Docs и комментарии ничего не выигрывают от swarm. Multi-file рефакторинги — много. Если вы проектируете agent-workflow, начинайте с типов задач с наибольшей дельтой.
Находка 3: стоимость растёт быстрее accuracy после 3 агентов
Токеновая стоимость — некрасивая часть:
| Swarm | Средние токены на задачу | Относит. стоимость | Прирост vs соло |
|---|---|---|---|
| 1 (соло) | 18k | 1.0× | baseline |
| 2 | 42k | 2.3× | +18 |
| 3 | 78k | 4.3× | +26 |
| 5 | 165k | 9.2× | +21 |
| 7 | 285k | 15.8× | +10 |
От 3 к 5 агентам вы платите 2.1× больше токенов за −5 пунктов accuracy. От 5 к 7 — 1.7× больше за ещё −11. Production-оптимум — 3.
Что это значит для инженерных команд
1. Начинайте с пары, не с swarm
Если команда вводит agent-assisted coding, первая эволюция — соло-агент → critic-augmented пара. Это самый дешёвый за токен прирост и почти убирает стыдные галлюцинации соло-агентов.
2. Swarm из 3 — для тяжёлых задач
Swarm из 3 — правильный инструмент для multi-file рефакторингов, фич, затрагивающих больше одного модуля, и миграций. Не используйте его на однострочных баг-фиксах или документации — координационный оверхед съест пользу.
3. Стоп на 5
Если архитектура дрейфует к 5+ специализированным ролям — стоп. Данные говорят: вы платите линейно за нелинейную координационную стоимость, и accuracy начнёт регрессировать. Вместо нового агента дайте существующим лучший контекст — длиннее system prompt, лучший доступ к тулам, richer memory.
4. Закладывайте 3–5× стоимости соло
Финансисты недооценивают agent-cost, потому что думают «один вызов на задачу». Swarm из 3 в среднем — 4× токенов соло. При 400 агентных задач в месяц по $0.30 за соло закладывайте ближе к $1.20 за задачу — это $480/мес, не $120.
Методика
Цифры выше — агрегат четырёх прогонов 2024–2025: SWE-Bench Verified (Princeton, 2024), ablations MetaGPT HumanEval+ (Hong et al., 2024), публичный research harness CrewAI и claim-verification eval из технического отчёта Anthropic Claude 3.5. Где бенчмарки расходятся более чем на 5 пунктов — отмечено.
Бенчмарки различаются языком (в основном Python), длиной задачи (1–500 строк) и строгостью оценки. Кривая size-vs-performance воспроизводится во всех четырёх — поэтому мы считаем «пик на 3» устойчивым, а не артефактом одной методологии.
Что PanDev Metrics тут видит и не видит
PanDev Metrics собирает IDE-heartbeat, где фиксируется, когда разработчик использует Cursor, Claude Code или аналогичные AI-инструменты внутри редактора. Мы можем измерить долю времени кодинга, которая идёт с AI и без, и видим кривые adoption, когда команда вводит agent-workflow. В посте AI Copilot Effect разобрано, что мы увидели между Cursor и VS Code.
Чего мы пока не видим: использовал ли конкретный сеанс swarm или соло, сколько agent-invocations было на сессию. Это gap, над которым активно работаем — IDE-плагины эту телеметрию раскрывают неравномерно, а API вендоров её пока не стандартизируют.
Честная оговорка: каждая цифра в посте — из бенчмарков на open-source репозиториях. Проприетарный код ведёт себя по-другому. Production-использование может показывать на 10–20% ниже success rate из-за большего контекста, незнакомых внутренних API и организационных конвенций.
Контринтуитивное утверждение
«Больше агентов — больше интеллекта» — консенсус 2024 у вендоров agent-фреймворков. Данные говорят обратное после трёх. Команды, которые выигрывают с agent-workflow, не крутят самые большие swarm; они крутят минимальный swarm, закрывающий plan + code + critique, и вкладываются в лучший контекст и более плотные feedback-loops. Цикл бенчмарков 2026 это подтвердит — и маркетинг вендоров будет продолжать утверждать обратное.