AI-ревью кода: оно реально помогает? (Данные со 100 команд)

AI-ревью кода сидит на гребне хайп-цикла. GitHub Copilot, CodeRabbit, Qodo, Graphite и ещё полдюжины стартапов продают будущее, где LLM ловят баги быстрее людей. Классическое исследование Microsoft Research и Bacchelli 2013 года задало бейзлайн, с которым мы сравниваемся десять лет: человеческое ревью ловит ~14% функциональных дефектов, но 68% проблем maintainability. Вопрос сегодня: сдвигает ли добавление LLM хоть одну из этих цифр?
Мы вытащили данные по ревью со 100 B2B-команд между Q1 2025 и Q1 2026 — микс команд с AI-ревью, без, и с гибридом. Паттерн не такой, как рассказывают вендоры.
{/* truncate */}
Почему эту цифру сложно найти
Поле AI-ревью кода доминируют вендорские исследования. Отчёт GitHub по Copilot Workspace 2024, кейсы Graphite, пара блог-постов CodeRabbit — все мерят «сколько времени сэкономили на ревью», не измеряя defect escape rate — долю реальных багов, прошедших ревью и попавших в прод.
Мерить только время ревью — это как мерить только время готовки при оценке ресторана. Быстрее — не лучше, если суфле опал.
Наш угол другой: мы трекали время ревью + defect escape + rework rate вместе, по четырём конфигурациям:
- No AI — чистое человеческое ревью
- AI-only — LLM авто-аппрувит, если проблем не видит
- AI-assisted — LLM комментирует инлайн, решения принимают люди
- Hybrid strict — LLM комментирует + люди обязательны + у LLM нет права merge
Только конфигурация 4 улучшает бейзлайн по всем трём измерениям.
Наш датасет
- 100 B2B инженерных команд, размер от 5 до 120 инженеров
- Q1 2025 по Q1 2026 — 12 месяцев данных по pull-request'ам
- 23 847 pull request'ов по репозиториям
- IDE heartbeat для времени, которое инженеры провели внутри ревью (а не возраст PR по календарю)
- 30-дневный пост-мердж трекинг дефектов, связанный с исходными PR через имена веток
Трекинг дефектов — необычная часть. Большинство исследований, цитирующих defect-escape цифры, выводят их из survey-данных или 7-дневных окон инцидентов. Мы связали имена веток с инцидентами на 30 дней после мерджа — этого достаточно, чтобы большинство функциональных багов всплыло.
Что показывают данные
Время ревью: гибрид выигрывает, AI-only проигрывает
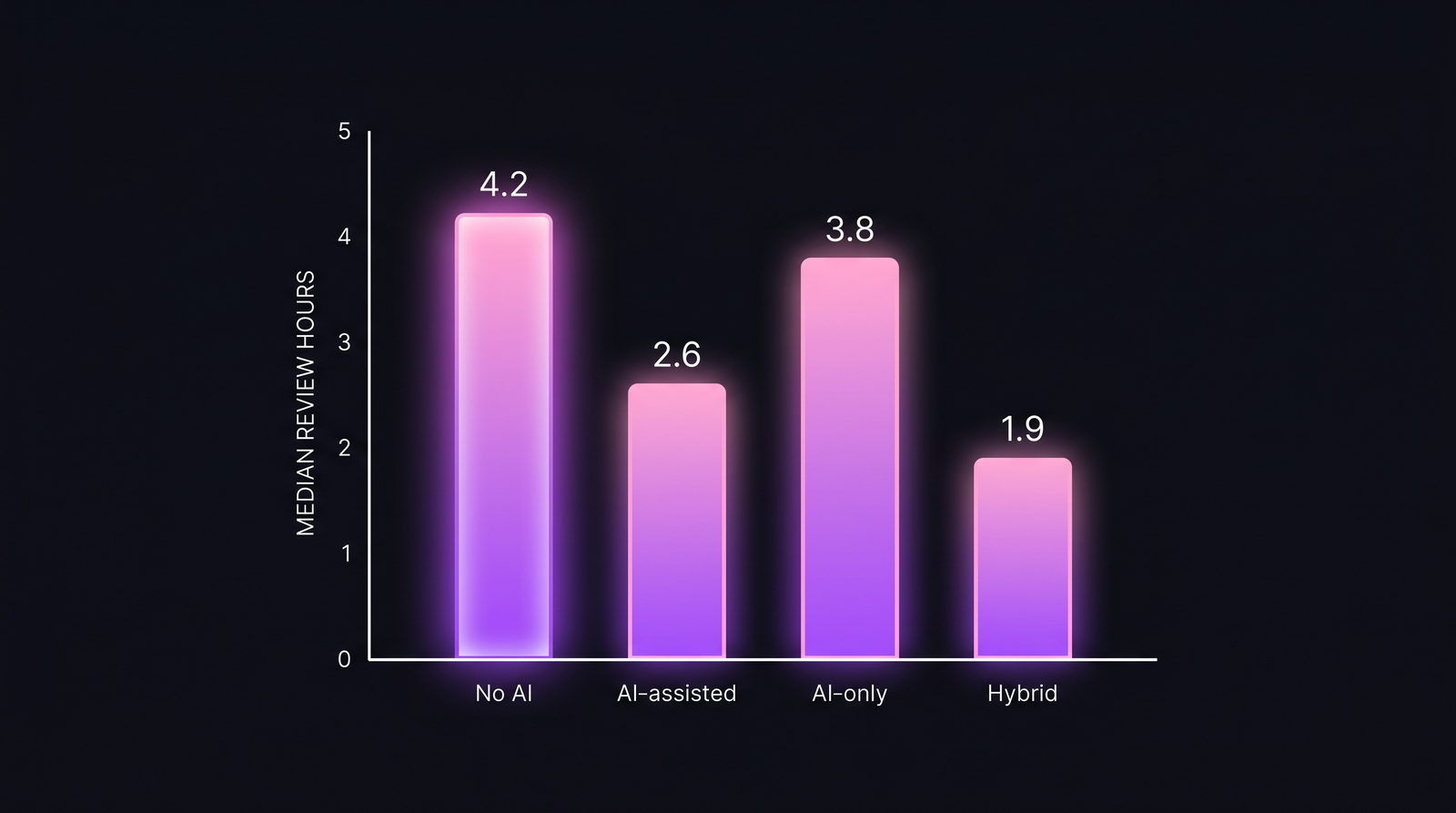 Медианное время на одно ревью по 23 847 PR на 100 командах. Hybrid strict режет время ревью пополам; AI-only — нет.
Медианное время на одно ревью по 23 847 PR на 100 командах. Hybrid strict режет время ревью пополам; AI-only — нет.
| Конфигурация | Медианное время ревью | Изменение к бейзлайну |
|---|---|---|
| No AI (baseline) | 4.2 часа | — |
| AI-assisted (LLM-комментарии инлайн) | 2.6 часа | −38% |
| Hybrid strict (LLM + человек обязателен) | 1.9 часа | −55% |
| AI-only (LLM авто-аппрув) | 3.8 часа | −10% |
AI-only результат контринтуитивен. Если LLM аппрувит, PR должен мерджиться быстро. Причина, почему не мерджится: rework. AI-only конфигурации генерируют 18% пост-мердж rework rate — баги, найденные после мерджа, требующие follow-up PR. Эти rework-PR забирают медиану 3.1 часа каждый. То, что сэкономили на первом ревью, вы вернули на follow-up.
Defect escape rate: AI-only — это ловушка
| Конфигурация | Дефекты в проде (30-дневное окно) | Sev-1 инциденты на 100 PR |
|---|---|---|
| No AI | 2.8% | 0.9 |
| AI-assisted | 2.4% | 0.8 |
| Hybrid strict | 1.7% | 0.5 |
| AI-only | 4.1% | 1.6 |
AI-only конфигурации выкатили на 46% больше дефектов, чем бейзлайн и почти удвоили частоту sev-1 инцидентов. LLM ловит синтаксис и очевидные анти-паттерны. Он пропускает контекст — именно ту категорию, которую по данным Bacchelli 2013 лучше всего ловит человеческое ревью.
Собственное исследование Google 2018 года (Sadowski, Söderberg, Church, Sipko, Bacchelli — Modern Code Review at Google) пришло к тому же выводу для pre-LLM автоматизированного ревью: автоматика ловит то, что ловят тесты. Креативная работа — человеческая.
Какие типы проблем ловит каждый тип ревьюера
 У каждого типа ревьюера своя специализация. AI — отличный джуниор; человек остаётся архитектором.
У каждого типа ревьюера своя специализация. AI — отличный джуниор; человек остаётся архитектором.
| Тип проблемы | Лучший ревьюер |
|---|---|
| Стиль / форматирование | AI (быстро, детерминированно, дёшево) |
| Security — очевидные паттерны (SQLi, XSS) | AI (детерминированный pattern-match) |
| Security — бизнес-логика (auth flow, привилегии) | Человек (нужен контекст) |
| Дизайн API / обратная совместимость | Человек (нужен контекст roadmap) |
| Качество тестов | Человек (LLM рационализируют плохие тесты) |
| Опечатки / null-чеки | AI |
| Читаемость / именование | Смешано (AI предлагает; человек принимает/отклоняет) |
| Архитектурный смел | Человек (LLM пропускают system-level контекст) |
Паттерн согласуется с любым другим исследованием «AI-augmented human work» в инженерии: AI — отличный junior-коллаб и ужасный senior-архитектор.
Что это значит для инженерных лидеров
1. Запретите AI-only ревью, если вы оптимизируете качество
Конфигурация «AI авто-аппрувит простые PR» выглядит как продуктивность, но на деле — это налог на качество, выплачиваемый с 30-дневной задержкой. Если ваш AI-инструмент поддерживает auto-approve — отключите. Держите AI как комментатора, а не как merger.
2. Мерьте время ревью И defect escape вместе
Любой AI-ревью пилот, трекающий только «сэкономленное время», настраивает вас на ловушку AI-only. Инструментируйте 30-дневный пост-мердж defect escape. Трекайте по конфигурации. Если вендор не производит эту цифру — они не мерят то, что важно.
3. ROI реален на простых PR; угасает на сложных
Наши данные показывают, что максимальный выигрыш AI-ревью — на PR меньше 100 строк изменений. Выше 500 строк выгода AI падает к нулю — LLM не удерживает контекст. Это совпадает с тем, что нашёл Stack Overflow Developer Survey 2024 про доверие к LLM в целом: 62% разработчиков доверяют AI для простых задач, 24% — для сложных.
4. Hybrid strict — единственная конфигурация для rollout по всей компании
Если пилотируете AI-ревью, пропустите фазу «AI авто-аппрувит простые PR». Сразу hybrid strict: AI комментирует инлайн, люди всё ещё обязательны, LLM не имеет права на merge. Экономия времени ревью больше, а качество лучше, чем в бейзлайне.
Где вписывается PanDev Metrics
Для команд, оценивающих AI-ревью инструменты, недостающий кусок — полная картина: время ревью, rework rate и 30-дневная атрибуция дефектов, в одном view. PanDev Metrics связывает Git PR-события с тикетами трекера через имена веток (feature/TASK-324) и с IDE heartbeat для реального времени ревью — это та комбинация, которая позволяет мерить «AI-ревью сэкономило X часов» И «AI-ревью стоило Y дефектов» в одном дэшборде. У большинства команд с Copilot / CodeRabbit половина картины.
Методология
Данные из production-телеметрии PanDev Metrics — 100 B2B команд с активными Git-интеграциями (GitHub, GitLab, Bitbucket), IDE heartbeat-плагинами на ≥70% команды и task-tracker связкой через конвенцию имён веток. Время ревью мерится от heartbeat-метки первого открытия файла IDE на ветке PR до метки merge, исключая idle-гэпы >30 минут.
30-дневная атрибуция дефектов: инциденты и hotfix-PR в течение 30 дней после родительского мерджа атрибутируются этому мерджу, если описание инцидента или hotfix трогает пересекающиеся файлы. False positive (несвязанные инциденты) ревьюились вручную на 2000 PR для калибровки точности авто-атрибуции; мы замерили 86% точность против ручного ревью.
Честные лимиты
Наш датасет скошен в B2B SaaS 10–120 инженеров. У нас нет сигнала по solo-разработчикам, open-source мейнтейнерам или командам выше 200 инженеров. Мы также не можем отделить, какие конкретные AI-инструменты показали себя лучше — часть из 100 команд использовала Copilot, часть CodeRabbit, часть Qodo, часть самописное. Относительное преимущество конфигурации (гибрид vs. AI-only) держалось на всех инструментах, но из этих данных мы не можем рекомендовать одного вендора над другим.
Самый острый вывод
Вот утверждение, которое я готов защищать: команды, развернувшие AI-ревью без инструментации defect escape rate, понятия не имеют, помог им AI-инструмент или навредил. Первая цифра, которую должен произвести любой AI-ревью пилот: «defect escape rate, 30 дней пост-мердж, по конфигурациям». Всё остальное — эстетика.