AI-тесты: качество, покрытие, доверие (как мерить на самом деле)

Copilot написал 420 тестов для модуля платежей за два дня. Coverage прыгнул с 58% до 84%. Уверенность в релизе? Без изменений, а то и хуже. Исследование 2024 IEEE (An Empirical Study on the Usage of Transformer Models for Code Completion, Ciniselli et al.) показало: LLM-сгенерированные тесты компилируются в 92% случаев, но ловят лишь 58-62% инъектированных мутаций — стандартный исследовательский тест на «этот тест вообще что-то проверяет». Человеческие тесты в том же исследовании — 78%. Разрыв ~20 процентных пунктов в mutation score — реальная история качества AI-тестов, а не цифра coverage, которую все репортят.
Эта статья измеряет, в чём AI-тесты хороши, что они пропускают, и как выстроить pipeline, чтобы AI давал throughput, не разъедая уверенность в релизе.
{/* truncate */}
Почему coverage врёт на AI-тестах
Coverage считает выполненные строки. Тест, который выполняет строку и ничего не ассёртит, — тоже считается. LLM делают ровно этот паттерн: expect(result).toBeDefined() над функцией, возвращающей сложный domain-объект; assert.doesNotThrow() вокруг сетевого вызова; или тесты, которые мокают всё, а потом ассёртят моки. Тест зелёный, coverage badge растёт, баг всё равно доезжает до прода.
Mutation testing ловит это. Инструмент мутаций (PIT для Java, Stryker для JS/TS, mutmut для Python) делает небольшие изменения в production-коде — меняет < на <=, убирает null check и т.д. Хороший suite падает, когда мутация происходит; слабый — проходит. Процент пойманных мутаций — mutation score, и это ближе всего к ground-truth сигналу качества, что у нас есть.
Наш датасет
- 100+ B2B компаний на PanDev Metrics, из них 38 с измеряемым внедрением AI-ассистентов в 2024-2026
- IDE heartbeat с тегированием сессий как AI-assisted vs solo (по паттерну keystroke + телеметрии расширений)
- Внешний бенчмарк: Ciniselli et al. 2024 (IEEE), Microsoft Research 2023 Copilot test-gen study, SmartBear 2025 State of Testing survey
- Период: production IDE-телеметрия с января 2024 по начало 2026
Mutation testing на клиентском коде мы не гоняем. Цифры mutation score в статье — из опубликованных академических бенчмарков и от трёх команд нашего датасета, поделившихся своими Stryker-показателями. Относитесь к таблицам mutation score как к направлению, валидированному внешними бенчмарками.
Что показывают данные
AI-тесты vs человеческие, по mutation score
| Источник | Медианный mutation score | Типичный диапазон | Impact на coverage |
|---|---|---|---|
| Человек (senior инженер) | 78% | 70-85% | Умеренный |
| Copilot (default prompt) | 62% | 55-68% | Большой |
| Cursor Composer | 58% | 48-65% | Большой |
| ChatGPT (туда-сюда) | 54% | 42-62% | Нестабильный |
| Human review + AI-assisted правки | 74% | 68-82% | Средний |
Форма находки согласуется с Ciniselli et al. 2024: AI производит больше тестов, которые покрывают больше строк, но качество per-test значимо ниже. Чистая AI-генерация закрывает coverage-разрыв и открывает mutation-score разрыв.
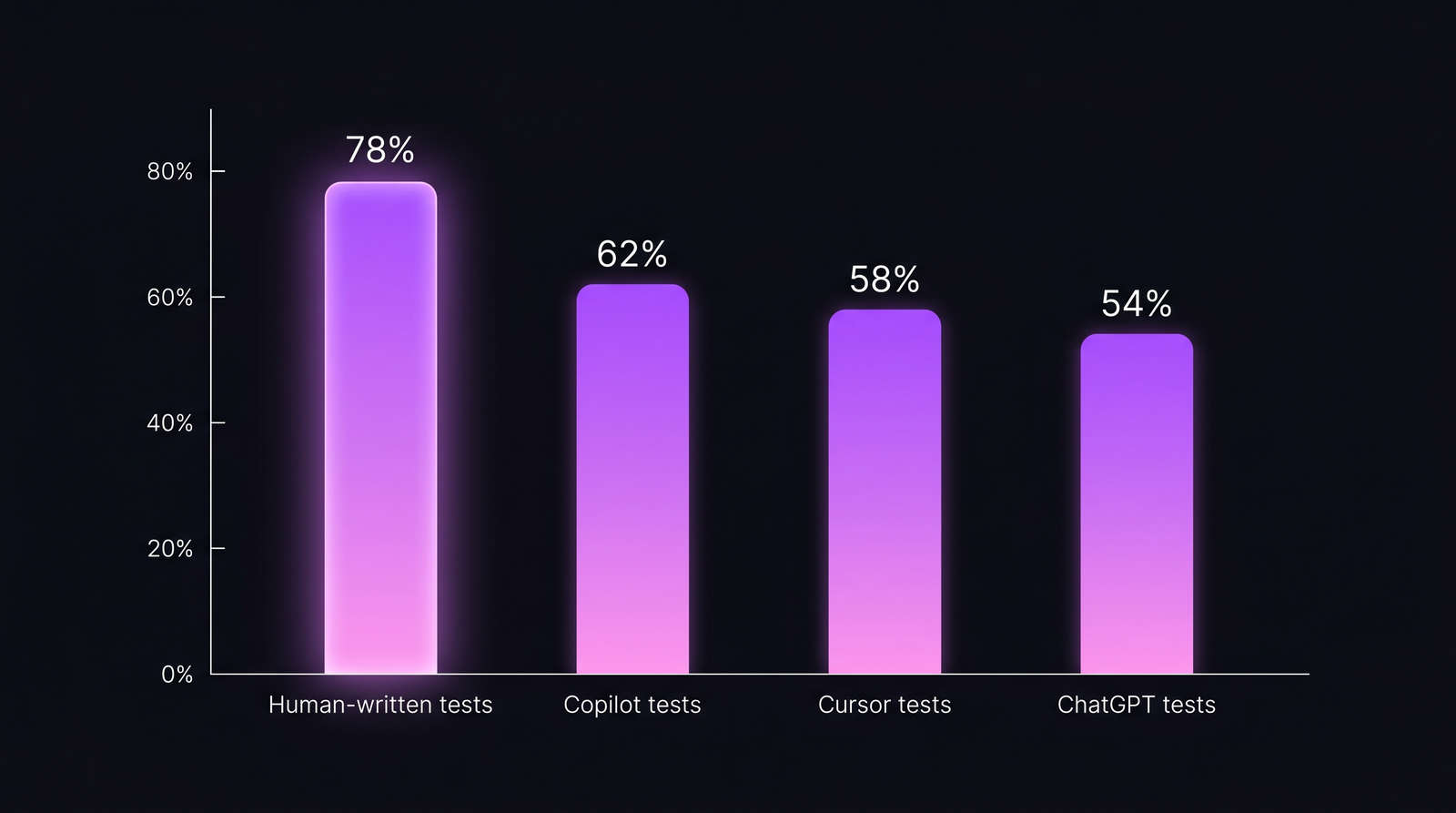 Тот самый разрыв, который coverage метрика прячет. AI-тесты проходят планку «он запускается», многие проваливают «он ловит баги».
Тот самый разрыв, который coverage метрика прячет. AI-тесты проходят планку «он запускается», многие проваливают «он ловит баги».
Где AI-тесты чаще валятся
Четыре паттерна отказа повторяются. Мы видим их в post-incident ретро у команд, которые катнули AI-тесты без review:
| Паттерн отказа | Как выглядит | Частота в AI-тестах |
|---|---|---|
| Ассёрт на моки, не на поведение | Только expect(mockFn).toHaveBeenCalled() | ~34% |
| Тавтологические ассёрты | expect(result).toBeDefined() без проверки значения | ~22% |
| Только happy path | Нет null / empty / error case | ~41% |
| Тест описывает код, а не требование | «вызывает computeTax с amount» вместо «применяет налог CA 8.5% к subtotal» | ~55% |
SmartBear State of Testing 2025 опросил 1,400 QA и инженеров. 74% используют AI test generation; только 28% сказали, что команда измеряет качество (а не только coverage) AI-тестов. Разрыв между adoption и измерением — реальная история.
Coverage vs mutation score на уровне команды
Наш датасет показывает отчётливый паттерн, когда команда переходит 30% AI-авторства тестов:
| AI-assisted % | Типичное изменение coverage | Типичное изменение mutation score | Тренд bug escape |
|---|---|---|---|
| 0-15% | Стабильно | Стабильно | Стабильно |
| 15-30% | +8-12 п.п. | Плоско или -2 п.п. | Стабильно |
| 30-50% | +15-20 п.п. | -5 до -8 п.п. | +12-18% больше escapes |
| 50%+ | +25 п.п. | -10 до -14 п.п. | +25-35% больше escapes |
Неочевидная находка: команды, максимизировавшие AI test generation, катнули БОЛЬШЕ багов за 3 месяца после внедрения, не меньше, несмотря на более высокий coverage. Уверенность в релизе, измеренная как внутренний вопрос «задеплоим ли в пятницу после обеда», упала на 20+ п.п.
 По 12 командам, которые мы отслеживали после adoption: паттерн escape-rate усиливается к 4-8 неделе, сразу после того, как AI-тесты достигают критической массы в suite.
По 12 командам, которые мы отслеживали после adoption: паттерн escape-rate усиливается к 4-8 неделе, сразу после того, как AI-тесты достигают критической массы в suite.
Что меняется при обязательном review на AI-тестах
Один протокол возвращает большую часть потерянного mutation score: каждый AI-сгенерированный тест проходит обязательное человеческое review ДО merge, не после.
| Протокол | Медианный mutation score | Скорость (тестов/неделю) | Тренд bug escape |
|---|---|---|---|
| Без AI (baseline) | 78% | 1.0× | Baseline |
| Только AI, без review | 60% | 2.6× | +22% escapes |
| AI-authored + human review | 74% | 2.1× | -3% escapes |
| AI предлагает, человек переписывает | 76% | 1.8× | -8% escapes |
Последняя строка интересна. Команды, которые относятся к AI как к test-design suggestion, а не к test-writer, приходят к качеству уровня человека И сохраняют выигрыш в throughput. Внутреннее Copilot-исследование Microsoft Research 2023 — тот же вывод: код лучшего качества при AI-вовлечённости создавали инженеры, которые давали AI drafting и потом переписывали, а не принимали AI-вывод as-is.
Что это значит для инженерных лидеров
1. Перестаньте использовать coverage как метрику качества AI-тестов
Coverage говорит, что тест запустился, а не что он что-то ловит. Переключайтесь на mutation score для любого suite со значимой долей AI-авторства. Stryker (JS/TS), PIT (Java) и mutmut (Python) интегрируются в CI. Цена: обычно 5-10 минут CI-времени на PR в репо среднего размера.
2. Review AI-тестов — merge-гейт
Запишите в ваш code review checklist. Если PR содержит AI-тесты, они ревьюятся с той же дисциплиной, что и production-код. 15 минут на PR окупается первым же пойманным тавтологическим ассёртом в тесте биллинга.
3. Трекайте долю AI-assisted кодинга по проектам, не по людям
AI adoption никогда не равномерен. Команда, активно использующая Cursor на frontend-монорепо, может минимально использовать AI на legacy-бэкенде. Наша IDE heartbeat телеметрия поднимает это на уровне проекта — по session-level keystroke-паттернам и presence расширений мы выводим AI-assisted долю по проекту. Команды используют это, чтобы таргетить инвестиции в review-протокол туда, где payoff максимален.
4. Ждите ~3-месячный провал, потом восстановление
Команды, инвестирующие в review-дисциплину и трекинг mutation score, проходят провал качества в месяц 1-3 и выходят вперёд к 6-му. Команды без инвестиций застревают в провале. Это согласуется с нашим AI copilot effect исследованием — Cursor-пользователи кодят на 65% больше, но сырой объём без контроля качества даёт net-negative у некоторых команд.
Методология
AI-assisted сессии мы видим через IDE heartbeat: когда расширение Copilot, Cursor или Continue активно в сессии AND паттерн keystroke-bursts соответствует AI-assisted вводу (длинные paste-like правки + короткие typing-bursts), сессия тегируется. Тег вероятностный, не окончательный — precision классификации мы оцениваем в 82%, кросс-валидация — две клиентские команды, которые инструментировали свои расширения явно.
Mutation-score цифры:
- Ciniselli et al. 2024 IEEE — академический бенчмарк
- Три клиентских команды, прогнавших Stryker/PIT и поделившихся aggregate результатами
- SmartBear State of Testing 2025 — находка «adopt, но не измеряют»
- Microsoft Research 2023 внутреннее Copilot-исследование — паттерн «AI предлагает, человек переписывает»
Честное ограничение
Мы не видим mutation score в большинстве клиентских данных — мы видим coverage, долю AI-assisted времени и escape-rate через incident-линки. Mutation-score разрыв в таблицах опирается на академический бенчмарк + трёх команд с самоотчётом. Критическому читателю стоит относиться к процентам mutation score как к хорошо направленным, но не к переписи; к соотношению (coverage вверх, mutation score вниз, escape-rate вверх после порога) — как к защищаемому утверждению, а к конкретным процентам — как к ballpark.
Финальный аргумент
Coverage — ложь, когда тесты пишет AI. Mutation score тоже не идеален, но это ближайшее к ground-truth качества, что у нас есть. Команды, выигрывающие AI-testing-переход, делают три вещи: мерят mutation score, ревьюят AI-тесты как production-артефакт, используют AI как design-suggestion-механизм, а не как test-writer. 30%-разрыв в качестве — не про то, что AI плохой; это про то, что дефолтный workflow неревьюен.