AI в собесах инженеров: как кандидаты реально читерят

Senior backend-кандидат, которого я собеседовал в марте 2026 для 40-человечного скейлапа, прислал 4-часовой take-home, очевидно сгенерированный AI за 30 секунд чтения. Не потому, что код плохой — код был слишком хорош: консистентный стиль в 14 файлах, docstring на каждой функции и подозрительно хорошо структурированный README, покрывающий edge-кейсы, которых задача не требовала. Что окончательно спалило: переменная is_applicable_within_business_context — ровно та фразировка, которую Claude 3.7 Sonnet использует, когда его просят написать «enterprise-grade» код.
Взяли другого. Через два месяца LinkedIn того же кандидата показал новую работу у конкурента, который не проверил. Не знаю, прошёл ли он бар on-the-job; индустрия рассказывает истории в обе стороны. Что точно: AI-assisted читерство стало дефолтом, а не outlier-ом, и воронки найма, спроектированные до 2024, отбирают не то. Опрос Stack Overflow 2024 обнаружил: 76% профессиональных инженеров активно используют AI-coding-tools; tooling кандидатов отстаёт от tooling разработчиков на недели, а не годы.
{/* truncate */}
Как кандидаты реально читерят (реальность 2026)
Пять распространённых playbook'ов. Знание их — как проектировать защиту.
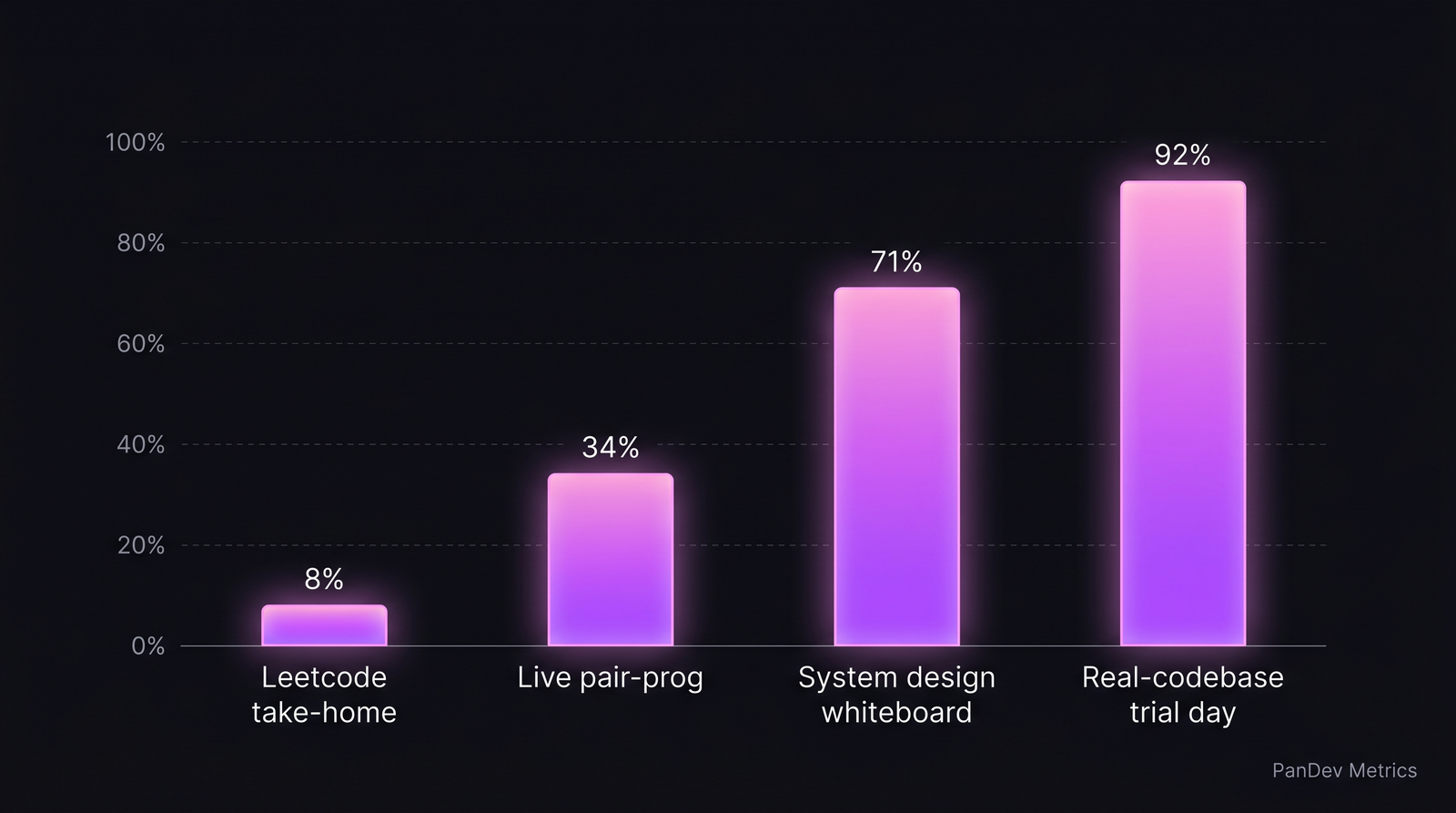 Signal-to-cheat ratio по форматам собеса. Take-home — худший, real-codebase trial day — лучший.
Signal-to-cheat ratio по форматам собеса. Take-home — худший, real-codebase trial day — лучший.
Playbook 1 — Take-home с Claude/GPT в другой вкладке
Дефолт для кандидатов 2025-2026. Кандидат вставляет вашу задачу в Claude 3.7 Sonnet, GPT-5 или Gemini 2.5 Pro и получает 70-90% рабочего решения за 5 минут. Оставшиеся 10-30% — вкус: именование переменных, структура тестов, гигиена README.
Коррупция сигнала: почти полная. Невозможно отличить take-home сильного инженера от слабого со хорошим LLM.
Playbook 2 — Live pair programming со скрытым LLM
Shared screen, кандидат печатает, у кандидата вторая машина с Claude Code или Cursor вне экрана. Вопрос набирается в LLM на устройстве B; кандидат читает ответ, печатает слегка модифицированную версию на A.
Tell: неестественный ритм pause-type. Реальные инженеры think-while-typing; LLM-reading-инженеры stop-read-type в 8-12-секундных burst'ах. Сложно заметить на одной сессии; видно на трёх.
Playbook 3 — System design с Claude в роли co-thinker
Кандидат использует voice-to-text на телефоне, спрашивает Claude «нарисуй rate-limiter с Redis на 100K RPS» вживую, зачитывает ответ. Если интервьюер пробует «почему Redis над X?», у кандидата есть время спросить Claude про trade-off.
Tell: ответ исчерпывающий на «нормальный» ответ, но коллапсирует на операционных вопросах вроде «что бы вы мониторили?» или «что сломается первым на 2M RPS?» — LLM отвечают на них обобщённо; реальные инженеры — специфично.
Playbook 4 — Целиком сгенерированная персона и резюме
LinkedIn-оптимизация AI, custom cover letters, GitHub-профиль с «впечатляющими» сайд-проектами, 90% которых сгенерированы. Не читерит собес как таковой — попадает на собес.
Коррупция сигнала: воронка расширяется кандидатами более низкого качества. Процесс собеса должен выдержать объём.
Playbook 5 — «AI-fluent» честные кандидаты (не читерство, но путаница)
Многие сильные инженеры теперь используют Cursor, Copilot или Claude Code как ежедневный driver. Их solo-output с этими инструментами лучше, чем без. Просить их собеседовать «без AI» — мерить не то, что они реально делают на работе.
Смешение сигнала: собес «без AI» отсеивает сильных AI-fluent-инженеров, реально 2-3x более продуктивных с tooling. Это не читерство — но та же проблема измерения.
Signal-to-cheat ratio по форматам
| Формат собеса | Даёт реальный сигнал в 2026? | Почему |
|---|---|---|
| Take-home coding | Очень слабый | Claude решит за 10 минут |
| Многочасовой Leetcode | Слабый | То же |
| Live coding (screen-share) | Средний | Часть LLM-reading детектируется |
| System design whiteboard | Сильный | Операционные probes ломают читерство |
| Real-codebase trial day | Очень сильный | Нельзя подделать 6 часов реальной работы |
| Past-work deep dive | Сильный | Follow-up-вопросы вскрывают глубину |
| Reference checks (2+ звонка) | Сильный | Поведенческий сигнал |
Воронка найма, работающая в 2026
1. Разрешите AI — но смотрите, КАК его используют
Прекратите делать вид, что AI не существует. Скажите кандидату: «Используйте любые инструменты, которые использовали бы на работе, включая Cursor, Claude Code, Copilot, ChatGPT. Нам важно, как вы ими пользуетесь, а не сам факт».
И смотрите:
- Верифицирует ли output AI или просто вставляет и запускает?
- Нацеливает ли AI на вашу конкретную задачу или спрашивает обобщённо?
- Может ли объяснить код, написанный AI, своими словами?
- Ловит ли галлюцинации AI?
Сильные AI-fluent-инженеры делают все четыре. Читеры ломаются на последнем — спросите «почему эта строчка здесь?», и читер держит паузу слишком долго.
2. Замените take-home платным trial day
Платный 6-8-часовой trial day на санитизированной ветке реальной кодбазы — самый высокосигнальный формат собеса, который мы видели. Кандидат:
- Берёт реалистичную задачу из бэклога команды
- Работает день любыми инструментами
- Пейрится с инженером последний час, объясняя решения
Читерство тут почти невозможно. Сложность и неоднозначность реальной системной работы превышает one-shot-способности LLM.
Минус: дорого. Ограничьте trial day финальным раундом (топ 3-5 в воронке).
3. System design с операционными probes
Оставьте system-design — но пробуйте глубже:
- «Как это падает на 10x load?»
- «Как выглядит on-call runbook?»
- «Какова стоимость этой архитектуры на текущем масштабе vs 5x?»
- «Как бы выглядел migration из текущего состояния в этот дизайн?»
Эти вопросы требуют операционного опыта, которого у LLM нет. Инженер, реально руливший production, отвечает фактурой; опирающийся на LLM — паттернами без специфики.
4. Past-work deep dive с follow-up
Попросите кандидата провести по системе, которую он строил. Затем спросите:
- «Самый сложный баг, зашипленный в production на этом?»
- «Что бы переделали сегодня?»
- «С чем вы спорили внутренне, а шипнули всё равно?»
Follow-up тестирует память, контекст и мнение. LLM могут сгенерить правдоподобное «описание системы»; не могут выдумать 6-месячную историю реального проекта.
Interview scorecard для 2026
Рескорьте кандидатов по четырём измерениям, не только «правильное решение»:
| Измерение | Что меряете | Вес |
|---|---|---|
| AI-fluent верификация | Ловил ошибки LLM, проверял output | 25% |
| Декомпозиция задачи | Разбил ambiguous-задачу на трактабельные куски | 25% |
| Операционная глубина | Ответил «что ломается на масштабе» конкретно | 20% |
| Коммуникация под давлением | Объяснял рассуждение при probing | 20% |
| Корректность кода | Рабочее решение | 10% |
Обратите внимание на инверсию весов: корректность теперь 10%, не 60%. Корректность в 2026 дешёвая (LLM её производят). Верификация, декомпозиция и операционная глубина всё ещё дорогие.
Как on-the-job-данные подтверждают
PanDev Metrics фиксирует IDE heartbeat, сегментированный по editor и tool. Что мы видим в customer-данных 2026:
- Инженеры на Cursor + Claude Code кодят на 65% больше часов на задачу в неделю, чем VS Code-only-инженеры на эквивалентной работе (см. анализ AI copilot effect)
- Из них топ-квартиль (верифицирован manager-рейтингом) показывает в 3-4x большую частоту паттерна «reverted commit» — не потому что хуже, а потому что быстрее итерируют и раньше откатывают ранние ошибки
- Инженеры, не использующие AI-tooling, показывают стабильный output, но на 30-40% меньше открытых PR в неделю
Воронка найма, отсеивающая AI-fluency, выбирает профиль с на 30-40% меньшим PR-объёмом. Некоторым командам это нужно. Большинству — нет.
Типичные ошибки
- «Запретить AI на собесе». Отсеивает 76% профессиональных инженеров и меряет навыки, которыми они на работе не пользуются.
- «Доверять take-home». Бесконтрольные take-home мертвы как сигнал. Только для скрина, не финала.
- «Скрин специально на skill-ы промптинга». Prompt engineering — реальный навык, но не прокси инженерного суждения. Не переоценивайте.
- «Паника — переписать процесс с нуля». Замените take-home на trial day + операционные system-design-probes. Не выбрасывайте reference checks и past-work dives — они ещё работают.
- «Мерить интервью только по final-round сигналу». Трекайте 90-day-review-скоры принятых кандидатов против interview-скоров. Найдёте, какие измерения предсказывают on-job-исход — а какие были шумом.
Контр-тезис
AI не делает найм сложнее — он делает ленивый найм устаревшим. Команды, спроектировавшие воронку вокруг «решишь Leetcode?», всегда мерили слабый прокси «построишь систему?». Claude теперь решит Leetcode. Команды, мерившие правильное — операционную глубину, systems-thinking, code-in-context reasoning — имеют меньше измерений для перепроектирования. Сдвиг заставляет hiring-committees делать то, что они должны были делать ещё в 2019.
Честные ограничения
Наши данные сильнее всего на том, что инженеры делают после найма — IDE-время, Git-паттерны, incident response. Мы напрямую не меряем качество собеса, так что signal-to-cheat-числа в таблице выше — из интервью с customer-ами и ревью опубликованных engineering-блогов (Stripe, GitLab, Doist, Shopify). Это направление, не точность. Магнитуда зависит от сениорности, комп-уровня и пула кандидатов.
Также: «читерство» — adversarial-фрейминг, но большинство кандидатов с AI не обманывают. Они используют то, чем пользовались бы на работе. Playbook выше относится к обеим группам одинаково — мерит рассуждение, а не сырой output.
Дополнительное чтение
- Cursor vs VS Code: AI-copilot effect (+65%) — on-the-job-данные за AI-fluency-аргументом
- Performance Reviews на данных: шаблоны и анти-паттерны — evaluation-сторона той же проблемы (post-hire)
- Claude vs ChatGPT vs Copilot 2026 — чем кандидаты реально пользуются
- External: Stack Overflow Developer Survey 2024 — AI tools — adoption-baseline для AI-coding-tools