Engineering capacity planning: математика Q3 roadmap

Команда из 6 инженеров, 60 рабочих дней, по 8 часов. PM приходит на планирование со слайдом «2 880 dev-часов capacity». Q3 roadmap влезает в 2 400. Комфортный буфер. Через три месяца 40% roadmap не успели, а в постмортеме пишут «scope creep».
Никакого scope creep не было. Цифра capacity была неверной с первого дня. Стэнфордский экономист Джон Пенкавель в исследовании по часам и продуктивности показал, что output-per-hour начинает падать после 49 часов в неделю, задолго до 60. Microsoft Research и UC Irvine с Глорией Марк добавили второе лезвие: каждое прерывание стоит в среднем 23 минуты 15 секунд на восстановление фокуса. Сложите эти два факта поверх любого 8-часового календаря и вы получите заметно меньше 8 продуктивных часов.
{/* truncate */}
Формула, которую никто не записывает
Большинство планирования относится к capacity как к арифметике: team × hours × days. На самом деле это умножение:
effective_hours = team_size
× FTE_utilization
× calendar_hours
× velocity_multiplier
× (1 - context_switching_tax)
Каждый множитель между 0 и 1 режет первоначальную цифру. Команды с 100% утилизацией, 100% velocity и нулевым context-tax не существует ни в одном датасете, который мы видели, включая собственный. Арифметическое допущение раздувает capacity на 35-55%, что совпадает с данными Atlassian State of Teams: средний sprint коммитится примерно на 1.4× от того, что доезжает до релиза.
Эта статья проходит математику и подставляет реальные числа из 6-человечной команды, чтобы показать, как 960 календарных часов схлопываются до 520 реальных.
Четыре множителя, источник за источником
Фокус в том, что ни один из них не оценивается на глаз. Каждый измеряется из телеметрии, которую ваша команда уже производит.
Множитель 1: FTE utilization
Календарные часы предполагают, что разработчик у клавиатуры 160 часов в месяц. Реальная IDE-телеметрия говорит иначе. Мы разобрали это в статье FTE utilization vs hours logged: медиана по нашему B2B-датасету сидит на 65-75% sustainable utilization в окне 90 дней. После 90% вы уже покупаете burnout, а не capacity.
В PanDev Metrics это идёт из f_mv_activity_total_user_daily_today(), функции, которая возвращает live FTE для каждого человека против его CustomEmployeeWorkingTime baseline (так контрактник на 4-дневной неделе считается против 128h, а не 160). Для departement-планирования усредняем mv_activity_total_user_daily по последним 90 дням — это и есть вход в формулу.
Множитель 2: Velocity (onboarding-налог)
Senior-инженер, который выкатил две фичи в прошлом квартале, имеет velocity 1.0. Новый сотрудник на второй неделе — нет. DORA в State of DevOps 2024 измерила 6-9-месячную ramp-кривую, прежде чем новые инженеры догонят team-mean throughput по changes-per-week. Мы трактуем это как скользящий множитель:
| Состояние инженера | Velocity multiplier |
|---|---|
| Новичок, неделя 1-4 | 0.30 |
| Onboarding, месяц 2-3 | 0.60 |
| Ramping, месяц 4-6 | 0.85 |
| Steady-state senior | 1.00 |
| 10+ лет на этой кодовой базе | 1.05 |
Это взвешенное среднее. 5 сеньоров и 1 новичок в команде из 6 дают (5 × 1.0 + 1 × 0.6) / 6 = 0.93. Звучит безобидно, пока не комбинируется со следующими двумя множителями.
Множитель 3: Context-switching tax
Лабораторные данные Mark — это пол; production хуже. Microsoft в Worklab study показал, что в 2022 у knowledge-workers сложился «triple peak» рабочий день, а блоки sustained focus сжимаются квартал за кварталом. Мы измеряем context switches через project-tag transitions в IDE heartbeats. Медианный project-switching tax в датасете лежит в диапазоне 15-22%, добираясь до 30%+ на командах с 4+ параллельными фичами.
Используйте эти диапазоны:
| Параллельных фич в работе | Context tax |
|---|---|
| 1 | 5% |
| 2 | 12% |
| 3 | 18% |
| 4 | 25% |
| 5+ | 32% |
Тот же сюжет под углом focus time разобран в статье Deep work schedules for developers: обратный взгляд на ту же цифру.
Множитель 4: Calendar hours
Самый честный. 160 часов в месяц — это FTE-конвенция; ваш реальный календарь отличается в месяцах с государственными праздниками, отпусками по уходу за ребёнком, плановым PTO и on-call ротациями. Кастомные календари в PanDev Metrics живут в CustomEmployeeWorkingTime, индексированы по userId × month, чтобы планировщик мог достать 6 индивидуальных baseline и просуммировать их вместо плоского headcount × 160 на слайде. В типичном Q3 на командах, которые мы измеряем, одна только календарная вариация (один декрет, две недели накопленного PTO, один кластер региональных праздников) срезает 8-12% headline-цифры до того, как сработают остальные множители.
Декомпозиция
Та же 6-человечная команда. Один квартал. Цифры из нашего датасета, округлённые:
| Шаг | Что вычитается | Часов остаётся |
|---|---|---|
| Календарная headline | 6 × 160h × 1 месяц | 960h |
| − FTE utilization | × 0.71 (90-day avg) | 682h |
| − Velocity weighting | × 0.93 (один новичок) | 634h |
| − Context-switching tax | × 0.82 (4 параллельные фичи) | 520h |
| Реальная monthly capacity | 520h (54% от календаря) |
520 часов. Headline говорил 960. Этот разрыв в 440 часов и есть то, что ломает roadmap-коммиты. Не scope creep. Не «команда не справилась». Математика, которая была неверной с первого слайда.
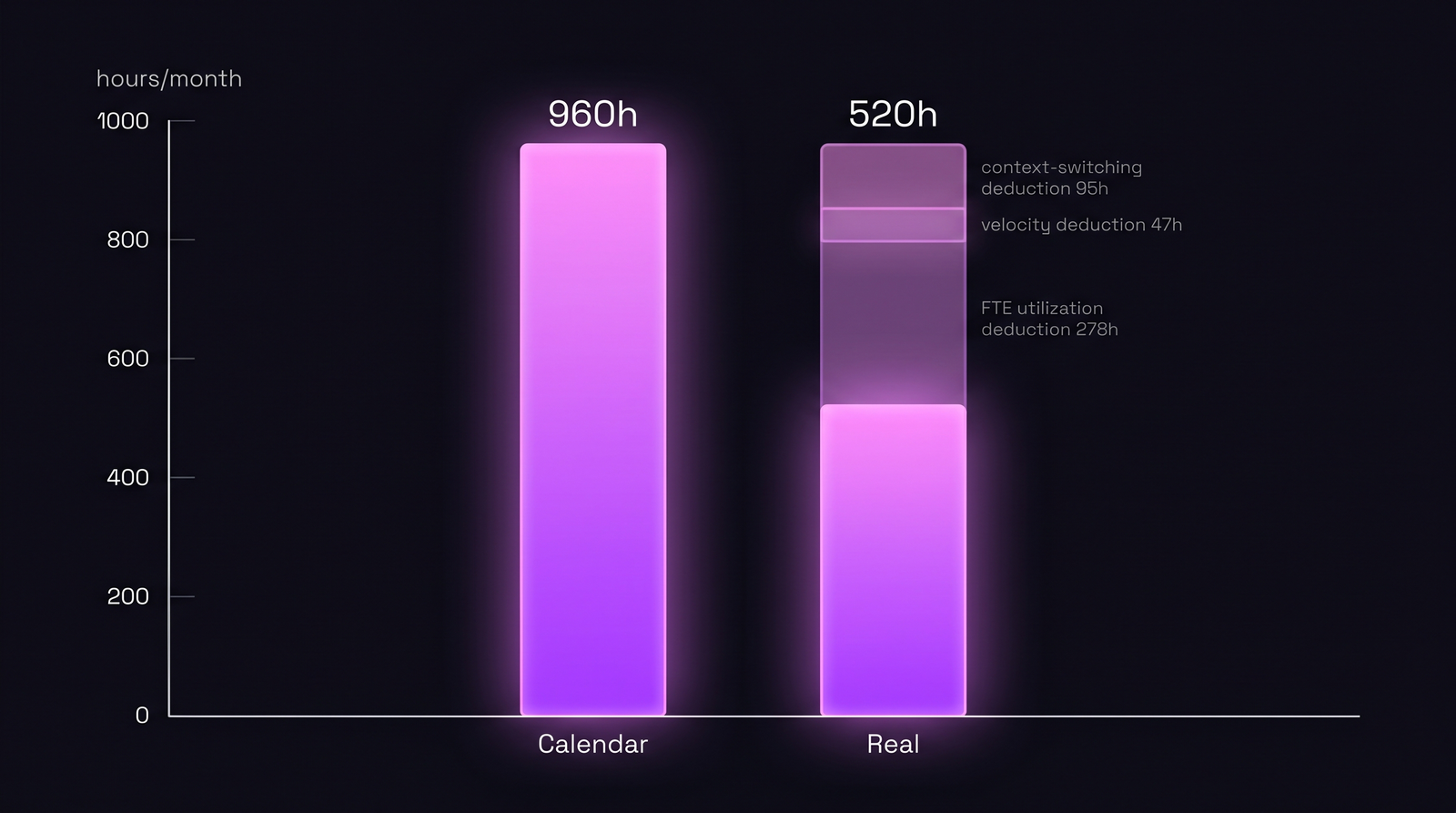 Та же команда, тот же месяц. Календарь показывает 960h. Реальная capacity после 4 множителей: 520h.
Та же команда, тот же месяц. Календарь показывает 960h. Реальная capacity после 4 множителей: 520h.
Три квартала одной команды: prediction vs actual
Где формула отрабатывает себя — это сравнение прогноза с реальной поставкой. Та же команда из 6 человек по Q1, Q2, Q3 2026:
| Квартал | Календарь | Прогноз формулы | Доехало | Variance |
|---|---|---|---|---|
| Q1 (steady) | 2 880h | 1 580h | 1 610h | +1.9% |
| Q2 (новичок 6 неделя, 5 фич в работе) | 2 880h | 1 290h | 1 240h | −3.9% |
| Q3 (полная команда, фокус на 2 фичи) | 2 880h | 1 790h | 1 750h | −2.2% |
Variance меньше 5% в каждом квартале. PM, который пользовался календарной цифрой (team × 160h × 3 = 2 880h), коммитился бы на 1.6-1.8× от того, что доезжало каждый квартал. PM с four-multiplier формулой коммитился практически ровно на то, что отгружалось.
Это та же входная телеметрия, которая питает employee utilization heatmap и delivery index без LOC: разные виды, один источник.
Где формула живёт в PanDev Metrics
Три места, где входы уже на экране:
/dashboard/finances/employee/:userId→ виджет utilization показывает FTE-историю человека с тем же 90-day окном, что и формула.- Department view → агрегирует
mv_activity_total_user_dailyпо подчинённым. Это и есть то, что вы суммируете в team-level multiplier. CustomEmployeeWorkingTime→ override-слой. Декрет 50%, региональные праздники в Алматы, sabbatical: всё считается против скорректированной baseline, а не плоских 160h. Без этого слоя FTE-multiplier тихо врёт на любом нестандартном расписании. Мы прочувствовали это на собственном on-prem rollout: инженер на 50% расписании читался как 95% utilization на heatmap, потому что знаменатель не был переопределён, и планировщик чуть не перераспределил работу из-за overload, которого не было.
Это не product pitch. Четыре числа, которые вам нужны (utilization, velocity weighting, context tax, custom calendar), считаются непрерывно из одного и того же IDE heartbeat-стрима, поэтому формула — не квартальная гадалка. Это SELECT запрос.
Что это меняет в планировании
Три конкретных сдвига, которые выпадают из математики.
Перестаньте коммититься на медиану
Цифра 520h — это медиана. В половине случаев команда отгрузит меньше. Atlassian показывает variance commitment-to-delivery порядка ±15% даже на стабильных командах, так что коммит на 520h означает поставку 442-598h в зависимости от месяца. Roadmap, закоммиченный по медиане, промахивается примерно в половине случаев. Планируйте против медианы минус 15-20% буфер на неизвестное: больничные, on-call пожары, задержки зависимостей, production-инцидент на 11-й день, который выедает двух сеньоров на неделю.
Капайте параллельные фичи на 3
Context-switching tax прыгает с 18% на 25% при переходе с 3 на 4 параллельные фичи. Это примерно 70 часов capacity испаряются — больше полной недели одного инженера — в обмен на «мы работаем над большим количеством вещей». Математика говорит «не надо». Контр-интуитивный вывод: команда, которая отгружает 3 фичи параллельно, обгонит ту же команду на 5 фичах на полную неделю capacity в месяц, хотя вторая команда в standup'е выглядит «занятой».
Пересчитывайте формулу каждый месяц
FTE utilization дрейфует. Velocity меняется, когда уходят сеньоры. Context tax скачет, когда outage добавляет внеплановый firefight-стрим. Four-multiplier формула — не плановая константа; это monthly recompute. Команды, которые пересчитывают в начале каждого квартала, стабильно попадают в 5% от плана; команды, которые ставят формулу один раз и замораживают, едят variance потом проваленными датами.
Честный лимит: capacity — это распределение, а не число
Даже со всеми четырьмя множителями вы получаете медиану, не прогноз. Буфер не опционален. Цифры выше идут с выборки в 30+ B2B инженерных команд в нашем датасете: распределённые команды в финтех, SaaS и on-prem regulated. Solo-разработчики и крупные open-source проекты ведут себя иначе. У нас по ним нет сигнала, и множители выше скорее всего перестрелят или недостреляют в зависимости от ритма.
Самое сильное утверждение: если вы коммититесь на медианную capacity без буфера, вы будете промахиваться по roadmap примерно в 50% случаев. Добавьте 15-20% и вы перекроете большую часть variance большую часть времени. Любой, кто продаёт вам более узкий прогноз, либо везучий, либо лжёт.
Что сделать завтра
Подтяните FTE utilization за последние 90 дней по своей команде. Умножьте на velocity-weighting таблицу. Вычтите context-switching tax bracket по числу параллельных фич. Сравните с календарной цифрой, против которой планируете.
Если разрыв больше 35%, ваш roadmap сейчас коммитится на capacity, которой нет. Чинится не «работаем больше». Чинится коммитом на цифру, которую данные действительно поддерживают, и защитой её на планировании four-multiplier таблицей.