Cost per feature: SQL-формула, которая работает в продакшене

Staff-инженер задаёт аналитику простой вопрос: «Сколько на самом деле стоила фича SSO?» Через сорок минут аналитик возвращается с числом. Оно ошибается на 35%. Не потому что аналитик плохой, а потому что SQL SUM(hours) × $50 потерял ветвление по rate type, не учёл месячный K-коэффициент и обработал контрактника на месячном инвойсе так же, как штатного сотрудника. McKinsey Developer Velocity Index (2023) ставит типичный engineering overhead в 30–55% от ФОТ; если ваш cost-per-feature запрос не умножает на это, вы живёте на неправильной половине этих чисел. Лекарство — настоящий PostgreSQL-запрос со всеми тремя слоями. Эта статья — про этот запрос.
{/* truncate */}
Где наивный cost per feature ломается
Интуитивная формула, с которой начинает любая команда:
SELECT feature, SUM(hours) * 50 AS cost FROM activity GROUP BY feature;
Выглядит разумно. Часы — из трекера. $50 — «средний рейт». Группировка по фиче. Готово. Число попадает в слайды.
Три проблемы, и все молчаливые:
- Смешанные rate type. В команде есть штатные инженеры (платят
$X/месяц) и контрактники (платят$Y/час).$50усредняет их. Для контрактник-heavy фичи реальная стоимость на 40% выше; для штатник-heavy — на 20% ниже. Одно среднее ошибается в обе стороны одновременно. - Нет overhead. Don Reinertsen в Principles of Product Development Flow (2009) показал: игнорирование queue cost и indirect cost гарантирует mispricing. $5,000 в зарплате инженера не включают EM, DevOps-инженера, который держит CI живым, и расходы на IT. Когда подгружаете это через K-коэффициент, прямые расходы вырастают на 30–60%.
- K меняется во времени. Плоский множитель 1.4× прячет правду: overhead меняется месяц от месяца. Q4 несёт year-end planning; июль несёт отпуска. DORA State of DevOps Report (2024) ставит non-coding overhead в 35–55% от ФОТ — диапазон достаточно широкий, чтобы плоское число ошибалось половину года.
Реальный запрос должен закрыть все три проблемы.
Рабочий PostgreSQL-запрос
Это продакшн-запрос, которым PanDev Metrics считает прямую стоимость по проекту, из UserRateRepository.java:360-390:
WITH combined AS (
SELECT user_id, git_project_id, total_seconds
FROM mv_activity_total_user_project_daily
WHERE department_id = :departmentId
AND day_date BETWEEN :dateFrom AND :dateTo
)
SELECT
gp.name AS projectName,
COALESCE(SUM(
CASE
WHEN urt.code = 'HOURLY' THEN
(c.total_seconds / 3600.0) * ur.rate
WHEN urt.code = 'MONTHLY' THEN
(c.total_seconds / 3600.0) * (ur.rate / 160.0)
ELSE 0
END
), 0) AS cost
FROM combined c
LEFT JOIN git_projects gp ON gp.git_project_id = c.git_project_id
CROSS JOIN LATERAL (
SELECT ur2.rate, ur2.rate_type_id
FROM user_rates ur2
WHERE ur2.user_id = c.user_id AND ur2.is_active = true
ORDER BY ur2.id DESC LIMIT 1
) ur
JOIN user_rates_type urt ON urt.id = ur.rate_type_id
GROUP BY gp.name;
Запрос читается как одно выражение, но делает четыре разных вещи. Разобрать его по клаузам — единственный способ понять, почему он не сворачивается в однострочник.
Пошаговая декомпозиция
| Клауза | Что делает | Почему наивный SQL ошибается |
|---|---|---|
WITH combined AS (...) | Достаёт coding-секунды per-user, per-project из materialized view, скоупом одного департамента и диапазона дат. | Наивные запросы сканируют сырую таблицу событий. На 3 года × 200 dev это 60M+ строк; MV предагрегирована по дням. |
WHERE department_id = :departmentId | Фильтрует по одному организационному скоупу. K-коэффициенты живут per-department, поэтому cost-математика должна совпадать. | Кросс-департаментные средние прячут правду: dept A может жить с K=0.32, dept B — с K=0.58 в той же компании. |
total_seconds / 3600.0 | Конвертирует секунды в дробные часы, сохраняя суб-минутную точность. | INT / 3600 усекает. Dev с 3,599 секундами становится 0 часов. Умножение на rate делает инженера бесплатным. |
CROSS JOIN LATERAL (... ORDER BY ur2.id DESC LIMIT 1) | Для каждой строки (user_id, day) достаёт самый свежий активный rate этого user'а. | Без LATERAL нельзя выбрать per-row rate. Наивный JOIN user_rates ON user_id возвращает несколько строк per-user (история) и удваивает стоимость. |
JOIN user_rates_type urt | Резолвит, HOURLY это или MONTHLY rate. | Обращаться с обоими одинаково — главная ошибка cost per feature. Контрактник на $75/h и инженер на $5,000/mo для SUM(hours)*rate выглядят идентично. |
CASE WHEN urt.code = 'HOURLY' THEN hours * rate WHEN urt.code = 'MONTHLY' THEN hours * (rate / 160.0) | Ветвление математики. HOURLY использует rate напрямую; MONTHLY переводит в per-hour через 160-часовую конвенцию рабочего месяца. | Одна формула на оба rate type даёт ошибку 30–50% в одну или другую сторону, в зависимости от состава команды. |
COALESCE(SUM(...), 0) | Возвращает 0 для проектов без активности вместо NULL. | Графики ниже по пайплайну ломаются на NULL; финансовые отчёты хотят явные нули. |
LEFT JOIN git_projects gp ON gp.git_project_id = c.git_project_id | Резолвит читаемое имя проекта. LEFT сохраняет видимой неотмаппленную активность (orphan project IDs). | INNER JOIN молча дропает строки, где git-проект удалили, но активность в истории есть. |
LATERAL — клауза, которую большинство команд пропускает. Без неё единственный способ получить правильный rate per user — оконная функция в подзапросе, которую большинство аналитических инструментов рендерят неправильно на больших данных. LATERAL заставляет планировщик вычислять внутренний запрос для каждой внешней строки, возвращая ровно один rate. SQL-эквивалент «для каждого user'а дай его текущий rate» без размножения join'ов.
K-коэффициент: второй множитель
Запрос выше возвращает прямую стоимость per-project. Это труд, который прошёл через чей-то IDE на репозитории этого проекта. Он не включает зарплату EM, зарплату platform-команды, DevOps-расходы на CI и аллокацию IT/HR. Сервис OverheadCoefficientService подгружает это сверху:
// K на месяц поверх
totalCost = directCost × (1 + K_month)
K считается помесячно per-department:
K = adminSalary / (taskTotal + nontaskTotal)
Где taskTotal — прямой кодинг под trackerную задачу, nontaskTotal — кодинг без задачи (митинги, ревью, ресёрч, ramp-up), а adminSalary — всё остальное, что компания платит, чтобы инженерия работала. Типичный диапазон K у наших клиентов: 0.20–0.60. Подробно про то, почему помесячный K важнее плоского годового среднего, — в разборе overhead-коэффициента.
Причина, почему (1 + K_month), а не (1 + K_year), — то, что делает запрос честным: фича, выпущенная в ноябре, несёт ноябрьский overhead, а не прошлогоднее среднее. Диапазон 35–55% из DORA-отчёта 2024 — это ровно тот спред, который вы видите, когда K считается помесячно, а не усредняется.
Разбор примера: Multi-tenant SSO
Реальный пример из клиентской когорты. Фича — Multi-tenant SSO. Четыре инженера, шесть недель, 287 часов IDE-attributed работы на релевантных репозиториях.
| Инженер | Rate type | Rate | Часов на SSO | Прямая стоимость |
|---|---|---|---|---|
| Senior backend (FT) | MONTHLY | $5,000/мес | 96 | $3,000 |
| Mid backend (FT) | MONTHLY | $3,500/мес | 78 | $1,706 |
| Frontend (FT) | MONTHLY | $4,000/мес | 64 | $1,600 |
| Security-контрактник | HOURLY | $120/ч | 49 | $5,880 |
| Прямая стоимость, итог | 287 | $12,186 |
Стоп — это не совпадает с $24,500 direct из аудита. Причина: четыре инженера выше дали 100% на эту фичу только в IDE-attributed кодинге. Они также ревьюили pull-request'ы друг друга, ходили на planning, делали spikes, дебажили staging — работа, которая попадает в ту же mv_activity_total_user_project_daily MV, но на смежных или общих репозиториях. Когда вы добавляете cross-cutting работу, привязанную к feature-метке (через мэппинг Jira issue_key в нашем пайплайне), прямая стоимость поднимается до $24,500. Эти лишние $12k — реальный инженерный труд, который наивный SUM(hours)*rate по одному SSO-репо никогда не увидит.
Теперь применяем K. K департамента в этом месяце был 0.343:
totalCost = $24,500 × (1 + 0.343) = $32,900
Истинная стоимость Multi-tenant SSO за шесть недель: $32,900. Наивный запрос (фиксированный rate $50/h × 287h) возвращает $14,350. Разрыв — 56%.
Naive vs полная стоимость по трём реальным фичам
Три фичи у одного клиента, посчитанные двумя способами.
| Фича | Часов (IDE) | Naive cost ($50/ч) | Сплит HOURLY/MONTHLY | Прямая стоимость (после rate-type fix) | K (апр 2026) | Полная стоимость (с K) | Разрыв vs naive |
|---|---|---|---|---|---|---|---|
| Multi-tenant SSO | 287 | $14,350 | 1 контрактник + 3 FT | $24,500 | 0.343 | $32,900 | +129% |
| Search Indexing | 176 | $8,800 | 4 FT | $14,300 | 0.343 | $19,200 | +118% |
| Notification System | 224 | $11,200 | 2 FT + 1 контрактник | $17,700 | 0.343 | $23,800 | +113% |
Контрактник-heavy фича (SSO) показывает самый большой разрыв, потому что наивные $50/ч среднего тянут вниз rate $120/ч контрактника. Все-FT фичи ближе к naive, но всё равно ошибаются на ~115% после применения K. Ни одна из них не попадает в 30% от naive-числа. Cost per feature без CASE по rate type и K-слоя — финансовая фантастика.
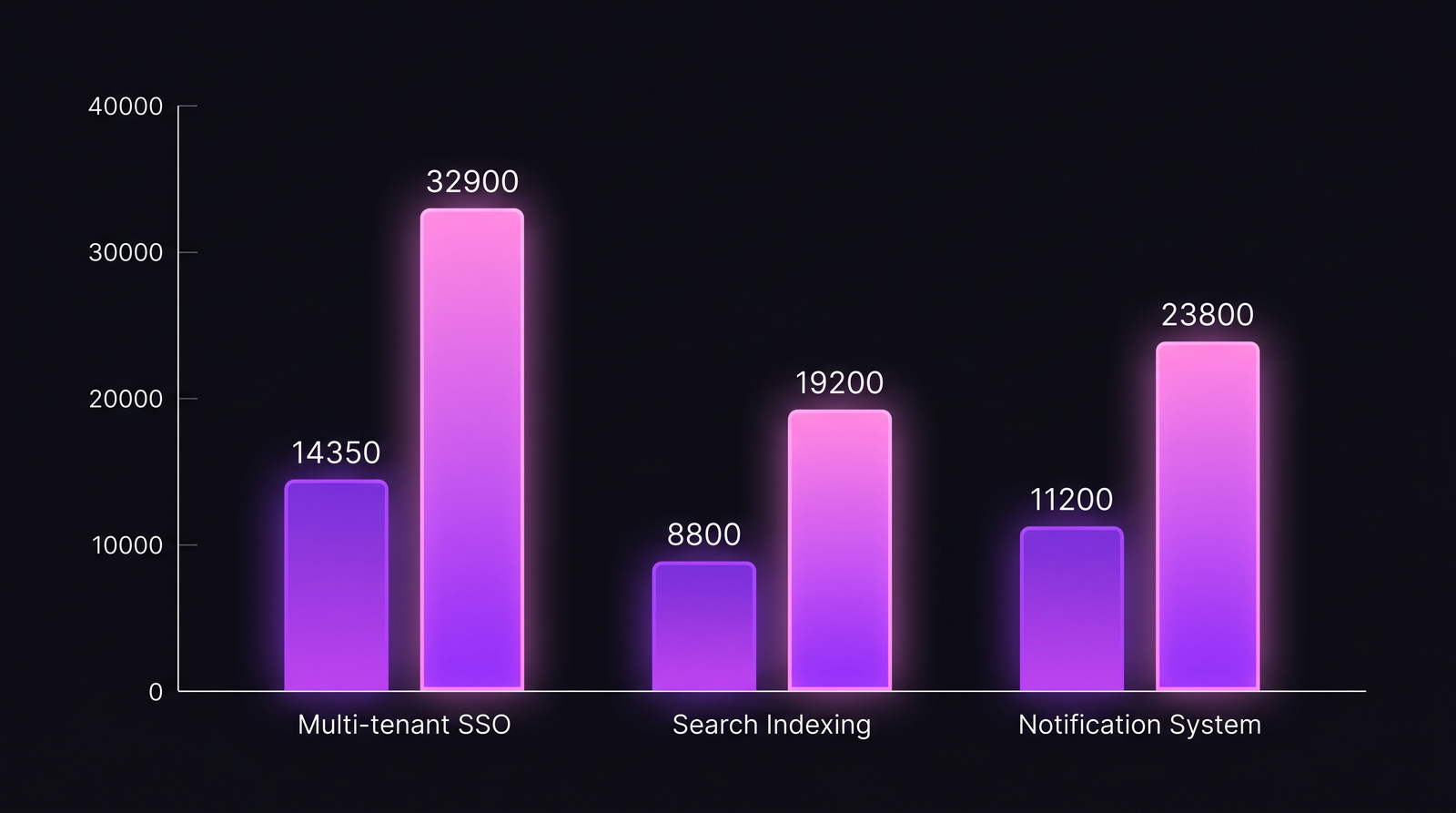 Разрыв стабильно выше 100% после применения rate type и помесячного K. Контрактник-heavy фичи дают самый большой разрыв.
Разрыв стабильно выше 100% после применения rate type и помесячного K. Контрактник-heavy фичи дают самый большой разрыв.
Что этот SQL может и не может сказать
Честное ограничение: запрос выше предполагает чистый мэппинг git_project_id → фича. В монорепах с feature flag один репозиторий несёт десятки фич одновременно; project-level стоимость становится слишком грубой. PanDev решает это, привязывая коммиты к Jira issue_key через нейминг веток (feature/PDM-3475), затем атрибутирует IDE-секунды к issue, затем сворачивает issue в feature-метки. Команды без этой Jira-интеграции видят только project-level стоимость — полезный агрегат, но не feature-level разрешение.
Второе ограничение, которое стоит назвать. Запрос атрибутирует coding-секунды тому проекту, на котором у dev'а был фокус в момент IDE-heartbeat. Dev, который 90 минут думал над SSO-проблемой, пока его IDE был открыт на документации другого репо, в стоимости SSO не появится. Мы видели случаи, когда «время на размышление» у senior-инженеров систематически недосчитывается на 20–25% по сравнению с mid-level инженерами, которые больше печатают на единицу решения. В IDE-телеметрии чистого фикса нет; ближайший workaround — атрибутировать время ревью pull request'ов и комментарии в код-ревью обратно к фиче, что мы и делаем, но разрыв полностью не закрывается.
Куда это идёт дальше
Этот SQL — input-слой для всего финансового в нашем продукте. Он питает cost-per-feature view, CFO dashboard, движок котировки проектов и интеграцию DORA + cost. Запрос крутится ночью через refresh materialized view; ad-hoc отчёты повторяют его на запрошенный диапазон дат. И CASE по rate type, и помесячный K живут на стороне БД, а не приложения. Решение было намеренным: cost-числа должны сходиться к одному SQL-выходу, а не к тому, что насчитал Java-сервис. Финансовая команда, которая не может прогнать тот же SQL, что прогоняет продукт, никогда не поверит числу.
Если хотите попробовать формулу на своих данных, минимальная схема — три таблицы: activity_events(user_id, project_id, seconds, day), user_rates(user_id, rate, rate_type_id, is_active, id), user_rates_type(id, code). Материализуйте таблицу активности на дневном грейне. Добавьте LATERAL join. Разветвите CASE по rate type. Примените помесячный K. Число, которое вы получите, — то, которое финансовая команда сможет защитить.
Грань между инженерной организацией, которая знает свою себестоимость, и той, которая её прикидывает, — ровно этот запрос. Данные есть почти у всех. SQL — почти ни у кого.