Cost per Jira-таска: видеть стоимость до конкретной карточки

В Q1 2026 мы инструментировали инженерную организацию, у которой в отчёте красиво стоял «$340K на проект X за квартал». Но если посмотреть в топ-5 тикетов внутри этого проекта, картина другая. PROJ-1245 рефакторинг auth: $4 820. PROJ-1281 баг с форматом даты: $3 140. Двухчасовой багфикс стоил больше половины архитектурного рефакторинга. Шесть инженеров трогали этот тикет три недели подряд, потому что у него не было хозяина.
Этот разговор невозможно вести с цифрой по проекту. С цифрой по конкретному тикету — можно. В этом весь аргумент поста — и причина, по которой большинство Engineering Intelligence тулов спорят про не тот слой.
{/* truncate */}
Почему стоимость на уровне проекта — это не та единица измерения
LinearB, Jellyfish, Code Climate Velocity и большинство Engineering Intelligence платформ считают стоимость одинаково: суммируют время инженеров в ведро проекта, умножают на loaded rate, показывают как квартальную цифру. Цифра реальная. И при этом бесполезная для разговора, который должен случиться на sprint review.
State of Teams 2024 от Atlassian показывает, что средний Jira-тикет проходит 6 переходов по статусам и через него прокатываются 3,4 разных человека до закрытия. Вот тут живут решения. Стоимость по проекту усредняет все эти переходы. К моменту, когда «$340K проект» появляется в отчёте CFO, конкретные тикеты, которые раздулись, уже отмыты в общей сумме.
DORA в 2023 Accelerate State of DevOps Report показывает, что cycle time — это leading indicator стоимости. Не потому что медленные тикеты дороже по часу, а потому что медленные тикеты накапливают context-switch налог на каждом владельце. Этот налог видно только если можно назвать тикет. Дашборд проекта прячет это by design.
В исследовании Engineering Effectiveness 2024 Forrester меньше 18% инженерных организаций могут сколько-нибудь точно ответить «сколько стоила вот эта фича». Доля тех, кто может ответить «сколько стоил вот этот тикет», — функционально ноль. Это и есть разрыв. Feature-level версию проблемы разобрали в cost-per-feature; здесь спускаемся ещё на один уровень агрегации ниже.
Механика: per-ticket cost — это просто JOIN, без магии
Per-ticket cost требует трёх вещей и не больше:
- IDE-телеметрия, которая знает, на какую таску ушла каждая минута кода (через имя ветки → ключ задачи)
- Loaded hourly rate на каждого инженера (см. loaded-hourly-rate-true-cost)
- Jira-issue_key (или ClickUp / Linear / Asana key) на каждом коммите, ветке, ворклоге
В PanDev Metrics слой хранения для этого — материализованное представление mv_activity_total_user_issue_daily. Оно джойнит editor-activity events с распарсенным Jira-ключом из активной ветки и агрегирует на уровне «пользователь × день»:
-- Схема (упрощённо)
CREATE MATERIALIZED VIEW mv_activity_total_user_issue_daily AS
SELECT
ae.user_id,
ae.day_date,
SUM(ae.active_seconds) AS total_seconds,
ae.issue_key,
ae.department_id
FROM activity_events ae
WHERE ae.issue_key IS NOT NULL
GROUP BY ae.user_id, ae.day_date, ae.issue_key, ae.department_id;
Для сегодняшних данных, по которым view ещё не пересчитался, есть live-функция f_mv_activity_total_user_issue_daily_today() — она возвращает ту же форму данных, считая на лету по сырым таблицам. Расчёт стоимости накладывается сверху:
SELECT
m.issue_key,
SUM(m.total_seconds / 3600.0 * r.loaded_hourly_rate) AS cost_usd,
COUNT(DISTINCT m.user_id) AS engineers,
SUM(m.total_seconds) / 3600.0 AS hours
FROM mv_activity_total_user_issue_daily m
JOIN engineer_rates r ON r.user_id = m.user_id
WHERE m.department_id = 17
AND m.day_date BETWEEN '2026-04-14' AND '2026-05-13'
GROUP BY m.issue_key
ORDER BY cost_usd DESC
LIMIT 10;
Тот же SQL-паттерн, что и для project-level cost, минус один уровень GROUP BY. В этом единственная механическая разница. Интерпретационная — гигантская.
Тот же SQL-паттерн мы разбирали в cost-per-feature-sql-formula — здесь меняется гранулярность, формула остаётся.
Как выглядит реальный топ-10
Распределение из реальной команды на 14 инженеров за Q1 2026, blended loaded rate $95/час, окно 30 дней:
| Ранг | Issue Key | Тип | Приоритет | Владелец | Часы | Инженеры | Стоимость |
|---|---|---|---|---|---|---|---|
| 1 | PROJ-1245 | Рефакторинг | P2 | A. Petrov | 62 | 4 | $4 820 |
| 2 | PROJ-1281 | Bug | P1 | без владельца → 6 рук | 49 | 6 | $3 140 |
| 3 | PROJ-1303 | Migration | P2 | M. Chen | 38 | 3 | $2 950 |
| 4 | PROJ-1319 | Bug | P3 | I. Volkov | 30 | 2 | $2 320 |
| 5 | PROJ-1330 | Hotfix | P1 | S. Rasulov | 22 | 3 | $1 860 |
| 6 | PROJ-1352 | Story | P2 | T. Lee | 19 | 2 | $1 640 |
| 7 | PROJ-1366 | Story | P3 | A. Petrov | 17 | 1 | $1 420 |
| 8 | PROJ-1378 | Bug | P2 | M. Chen | 14 | 2 | $1 280 |
| 9 | PROJ-1391 | Story | P3 | D. Aliyeva | 13 | 1 | $1 110 |
| 10 | PROJ-1402 | Bug | P3 | I. Volkov | 11 | 1 | $980 |
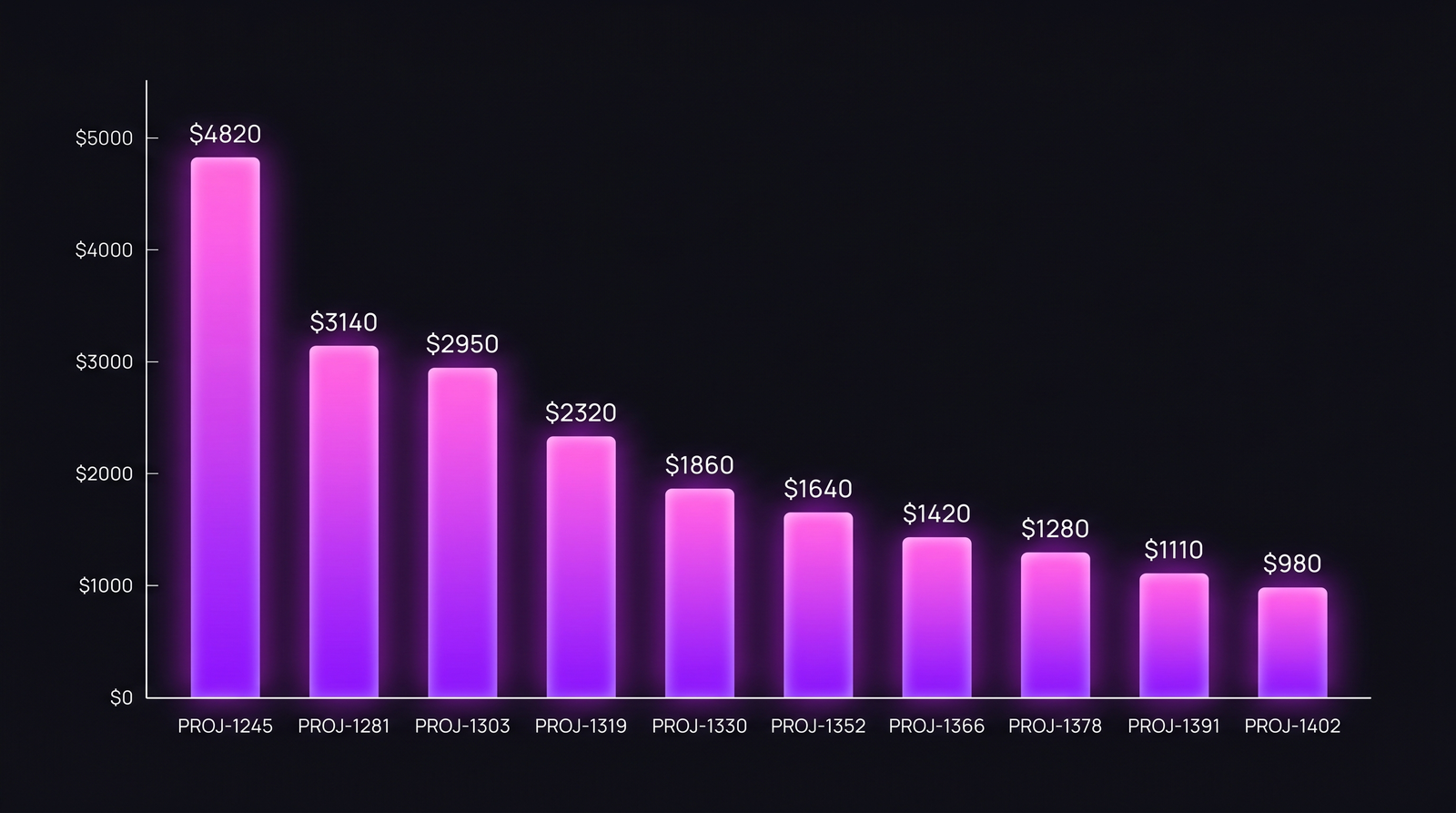 Распределение крутое: ранг 1 примерно в 5 раз дороже ранга 10. Это типичное соотношение, не выброс.
Распределение крутое: ранг 1 примерно в 5 раз дороже ранга 10. Это типичное соотношение, не выброс.
Три вещи, которые видны на этом уровне и не видны на уровне проекта:
Налог за бесхозный баг. PROJ-1281 — баг с форматом даты, P1, оценили как «двухчасовой фикс». Стоил $3 140 и съел 49 часов на шести инженерах, потому что ни один не был владельцем. Каждый из шести тратил 30–90 минут на загрузку контекста, частичный фикс и передачу дальше. Баг в итоге закрылся. Шесть передач из рук в руки — вот настоящая история.
Рефакторинги — не главные злодеи. Инженеры любят показывать пальцем на рефакторинги: «вот куда уходят деньги». PROJ-1245 (рефакторинг) стоил $4 820 — но у него был владелец, четверо инженеров параллельно делали 62 фокусированных часа, и он закрылся чисто. Per-hour-of-attention это самый эффективный пункт во всём списке.
P3-баги дороже P2-историй. PROJ-1402 (P3-баг) стоил больше нескольких P3-историй вместе. Баги не уважают свои priority-лейблы — они расширяются под доступное время, особенно когда воспроизведение нестабильное.
Распределение хотфиксов: где средние врут
Топ-10 — заголовок. Распределение внутри одного типа тикета — структурный вывод. Тот же датасет, тип «hotfix», 50 экземпляров за те же 30 дней:
| Статистика | Стоимость хотфикса |
|---|---|
| Медиана | $620 |
| Среднее | $1 140 |
| p75 | $1 420 |
| p90 | $2 640 |
| p95 | $3 800 |
| Max | $5 210 |
Среднее в 1,8x больше медианы. Это и есть главная проблема, когда CFO показывают «средняя стоимость хотфикса». Медианный хотфикс — это 6-часовой фикс, закрылся чисто. p95-хотфикс — это многодневная экспедиция на четверых инженеров, породившая два фоллоу-ап тикета и потребовавшая war room. Это разные звери. Назвать их обоих «хотфиксами» и усреднить — получите цифру, которая не описывает ни тех, ни других.
Если CFO спрашивает «сколько нам стоили хотфиксы за квартал?», правильный ответ содержит минимум три значения: медиана, p95, и количество выше $2 000. Меньше — прячет длинный хвост, который и наносит реальный урон бюджету.
Какой разговор открывает per-ticket cost
Цифра по проекту приводит к «надо тратить меньше на проект X». Это стратегический разговор. Стратегические разговоры идут шесть недель и заканчиваются слайдом.
Цифра по тикету приводит к «PROJ-1281 стоил $3 140, и мы до сих пор не знаем, кто отвечает за форматирование дат». Это операционный разговор. Он идёт 15 минут на retro и фиксится сразу.
В PanDev Metrics это живёт как EmployeeTasksWidget на personal-finance дашборде. Для каждого инженера он показывает не общую стоимость, а самый дорогой единичный тикет, который этот инженер трогал в периоде. Мы выбрали такую метрику намеренно. Total cost награждает тех, кто залогировал больше всех часов. «Самый дорогой пройденный тикет» вытаскивает наружу карточки, на которых внимание застряло. Два инженера с одинаковым total cost могут иметь очень разные worst-offender тикеты — и именно колонка worst-offender запускает разговор о приоритизации.
Дополняющий вид — /dashboard/finances/task/:taskId. Это per-ticket dynamic: график стоимости одного тикета во времени с разбивкой по инженерам. PROJ-1281 на этом графике — шесть отчётливых вспышек, по три недели апарт, каждая — другой инженер, между ними нули. Это и есть картина «никто не владел». Каскад вспышек = тикет передавали из рук в руки. Один высокий столбик = один человек на нём сидел. Форма графика — это диагноз.
API, который кормит оба представления — POST /departments/{id}/finance/tasks. Возвращает страницу тикетов с cost, percentageOfTotal и percentageChange относительно предыдущего периода. Так что видно не только «дорогие тикеты», но и «тикеты, чья стоимость ускорилась неделя к неделе». Ускорение обычно полезнее как сигнал: тикет, удвоившийся в стоимости между спринтами, — это leading indicator того, что владение уплыло.
Если команда уже использует DORA, это укладывается в фреймворк прямо: высокий lead time на отдельной карточке — это пожарная сигнализация дорогой задачи. Подробнее в DORA metrics 2026.
Как реально использовать это на retrospective
Механика — скучная. Дисциплина использования — там, где команды отличаются. Рабочий паттерн:
- Выгрузите топ-5 тикетов по стоимости за закрытый спринт, не за открытый. У закрытых стабильные данные.
- Для каждого — был ли cost ожидаемым? Если 5-дневный рефакторинг стоил $4 800 — это и закладывали. Если «двухчасовой баг» стоил $3 140 — вот тут разговор.
- На каждый неожиданный задайте один точный вопрос: кто должен был быть владельцем и не был? Не «почему так получилось» — это даёт постмортем. «Кто должен был владеть» даёт имя и изменение процесса.
- Трекайте p95 одного типа через спринты. Если p95 хотфиксов растёт от $3 800 до $5 400 за квартал — у вас структурная проблема в triage хотфиксов. Если стабилен — у вас нормальный incident pipeline.
- Не разбирайте каждый тикет. Смысл per-ticket cost — вытащить 5%, которые сломали бюджет, а не микроменеджить остальные 95%, которые сработали. Оптимизация не того слоя — это тоже потери.
Честный лимит
Per-ticket cost требует надёжной связки Jira ↔ коммит. Если в команде нет конвенции имён веток типа feature/PROJ-1234-description или ключ задачи не попадает в коммит-сообщение — атрибуция падает на уровень проекта. У движка просто нет ключа для джойна. Команды на Linear, ClickUp или Asana ловят то же требование со своими форматами ключей (ENG-1234, CU-abc123, T1234).
В наших внедрениях соблюдение branch-naming — самый сильный предиктор того, насколько полезным окажется finance-модуль. Команды выше 90% получают чистый ticket-level cost. Команды ниже 70% видят кучу строк «(unattributed)» и тратят два месяца на починку конвенции, прежде чем дашборды начинают что-то стоить открывать. Никакой умный ML это не починит. Если данные не размечены в источнике, никакая агрегация ниже по потоку их не восстановит.
Второй честный лимит: per-ticket cost не учитывает время review и тестирования людей, которые не работали с веткой. Ревьюер, потративший 90 минут на PR, но не делавший checkout, в IDE-heartbeat модели даёт ноль секунд на тикет. Мы показываем эту дельту отдельно, как review-load метрики, но это известная неточность per-ticket стоимости — реальная стоимость тикета чуть выше, чем мы её посчитали.
Что сделать завтра утром
Если команда на Jira и соблюдает branch-naming, эту цифру можно посчитать SQL-запросом по worklog-данным — тот же JOIN, что выше. Если IDE-телеметрии для точного джойна нет, родной time-tracking Jira даст приближение, с поправкой: self-reported worklog обычно на 30–40% ниже IDE-telemetry времени на командах, где мы измеряли и то, и другое.
В любом варианте действие одно: назовите самый дорогой тикет из последнего спринта, откройте его историю, спросите — был ли у него владелец. Если ответ «вроде как да» — это $3 000, которые сэкономите в следующем квартале. Разговор короткий. Цифра достаточно мала, чтобы по ней действовать. Это и есть то, что покупает per-ticket view.
Project-level cost говорит, сколько вы потратили. Per-ticket cost говорит, какие решения принять иначе в следующем спринте. Это разные продукты — и большинство engineering-finance тулов производят только первый.