Datadog vs Honeycomb в 2026: сравнение observability-платформ

Рынок observability в 2025 году перевалил за $5 млрд годовой выручки и в 2026-м прибавит ещё двузначный процент. Два самых громких имени — Datadog и Honeycomb — стоят на разных философских полюсах. Datadog хочет быть единым окном для всего, что дышит в вашем кластере. Honeycomb утверждает, что «всё» — это ловушка, и одно широкое событие на запрос лучше, чем три столпа, склеенных по correlation ID. Оба в чём-то правы. Ни один не прав во всём.
{/* truncate */}
Quick TL;DR
Datadog — широкая агентная мониторинг-платформа: 700+ интеграций, глубокие дашборды, зрелая ML/AI-поверхность. Сделан под широту.
Honeycomb — observability на структурированных событиях, с BubbleUp и движком запросов, заточенным под high-cardinality дебаг. Сделан под глубину.
Выбор по сути не про фичи. Он про то, как вы дебажите: с дашборда или из запроса.
Разница в модели данных — и почему это важнее всего
Datadog унаследовал классическую модель трёх столпов: метрики, логи, трассировки. Каждый живёт в своём подсистеме со своим retention, индексацией и тарифом. Корреляция между ними — через теги (service, env, version) и trace ID. Хорошо работает для «жив ли хост?». Хуже для «почему p99 скакнул для пользователей на tenant=acme на iOS 17 в Сан-Паулу между 14:02 и 14:07?»
Базовая ставка Honeycomb, сформулированная сооснователем Charity Majors в книге Observability Engineering (O'Reilly, 2022): одно широкое структурированное событие на запрос — со сотнями полей, включая бизнес-контекст — схлопывает три столпа в одну подложку. Не нужно джойнить метрики с логами и трейсами. Вы запрашиваете event store.
Практическое следствие: high-cardinality вопросы (group by user_id, tenant_id, feature_flag_variant) в Honeycomb — first-class. В Datadog те же вопросы требуют либо custom metrics (тарифицируются отдельно, бюджет уходит быстро), либо indexed log queries (платите и за GB ingest, и за indexed event).
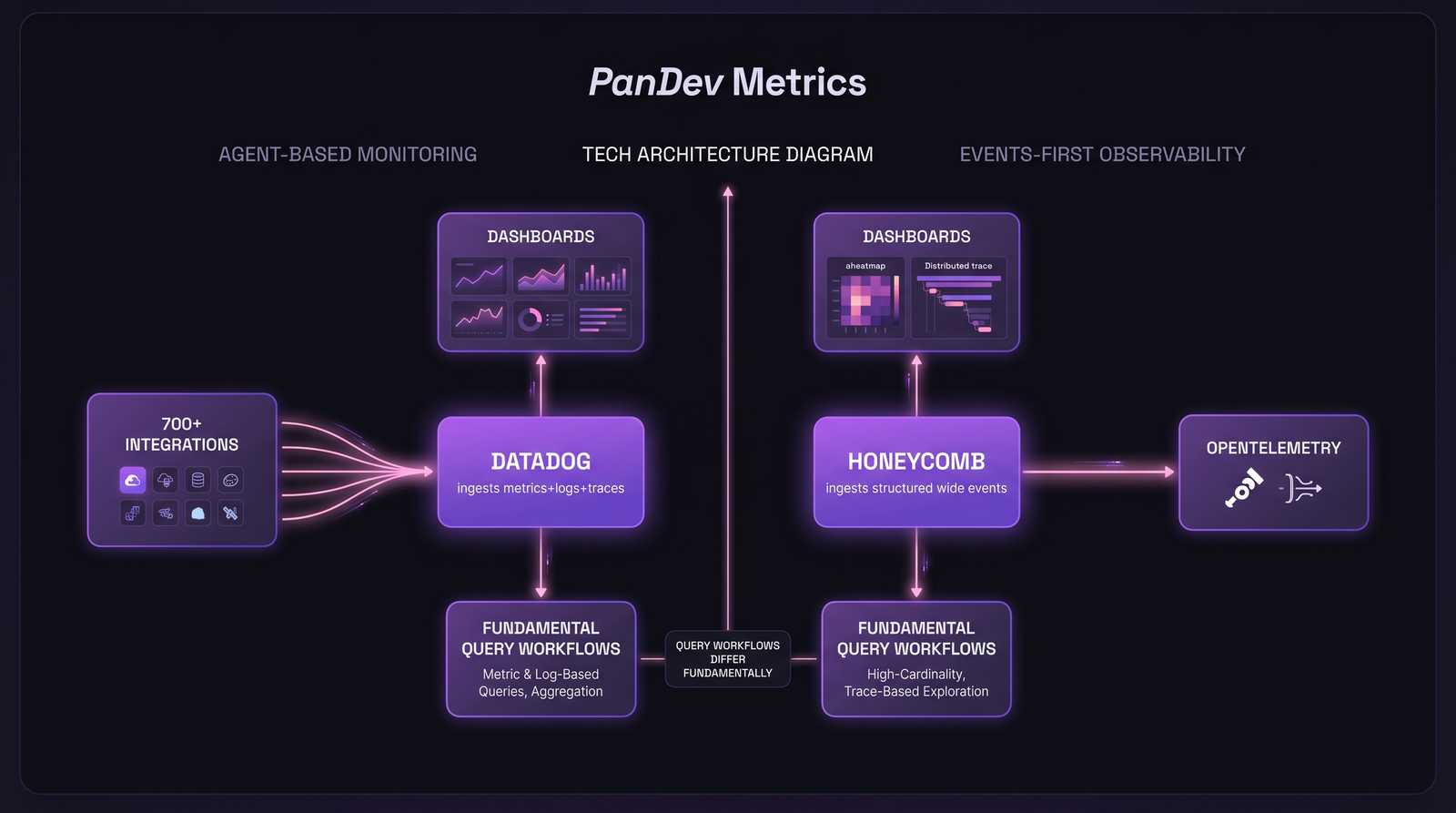 Один инцидент, два разных рабочих процесса. Модель данных формирует то, как ваши инженеры думают о проблеме.
Один инцидент, два разных рабочих процесса. Модель данных формирует то, как ваши инженеры думают о проблеме.
Datadog в 2026
В чём Datadog силён
- Широта интеграций. 700+ официальных интеграций на начало 2026: от AWS и Kubernetes до Snowflake, Stripe и Zendesk. Если вендор существует — интеграция, скорее всего, тоже.
- Готовые дашборды. Старт быстрый. Установили агент, направили на сервис, через час есть дашборд.
- Watchdog и Bits AI. ML-детектор аномалий у Datadog давно созрел. Watchdog находит выбросы без явных порогов; Bits AI (релиз 2024) позволяет инженерам задавать вопросы на естественном языке и получать объяснения из контекста инцидента.
- Enterprise-чеклист. SOC 2 Type II, HIPAA, FedRAMP Moderate, private link для residency, RBAC на масштабе.
Где болит
- Цена масштабируется агрессивно. Финансовые отчёты Datadog за 2024 показывают $2.6B годовой выручки и 28% YoY роста — этот рост откуда-то берётся, и «откуда-то» — это ваш счёт. Per-host APM, indexed logs, custom metrics, RUM, CI Visibility, синтетика — у каждого свой счётчик.
- Ловушка indexed logs. Залогировать ≠ проиндексировать. Неиндексированные логи дешёвые, но запросить их на скорости нельзя. Когда SRE впервые понадобится дебажить продовый пожар по архивным логам за три недели — приходит счёт за rehydration.
- Налог на custom metrics. Каждая уникальная комбинация тегов — это custom metric. Команда, добавившая
tenant_idв гистограмму при 5 000 тенантов, только что создала 5 000 custom metrics. Datadog возьмёт за них около $0.05 в месяц каждый плюс overage. Легко промахнуться в оценке. - Накладные расходы агента. По публичным замерам клиентов агент Datadog потребляет 1–3% CPU на хост под нагрузкой. Не катастрофа, но не бесплатно — заметно в плотных контейнерных бюджетах.
Кому Datadog подходит
Mid-market и enterprise с разношёрстным стеком, выделенной SRE/observability-функцией и бюджетом, который способен переварить счётчики. Если нужна одна тулза, которая отвечает «всё ли в порядке?» по 40 сервисам без написания запросов — Datadog отрабатывает свою цену.
Honeycomb в 2026
В чём Honeycomb силён
- Скорость запросов по trace-данным. Колоночный event store Honeycomb построен под быстрые агрегации по high-cardinality полям. Клиентские отчёты и собственные бенчмарки Honeycomb стабильно показывают запросы по сотням миллионов событий меньше чем за 10 секунд.
- BubbleUp. Выделите медленную область heatmap'а, кликните, и Honeycomb покажет, какие значения полей отличают медленные события от baseline. Это та единственная фича, которая меняет манеру дебага — меньше «дайте я проверю 12 дашбордов», больше «покажи, что отличает эти запросы».
- OpenTelemetry-native. Honeycomb был ранним спонсором OTel, и весь продукт исходит из того, что OTel SDK — основной путь ingestion. Никакого проприетарного агента. По данным CNCF Annual Survey 2024, 68% организаций уже используют или оценивают OpenTelemetry — ставка Honeycomb окупается.
- Предсказуемая цена. Honeycomb тарифицирует события на ingest при фиксированном retention. Нет per-host счётчика, нет ловушки «indexed vs unindexed», нет множителя на custom metrics. Счёт можно прогнозировать на три месяца вперёд.
Где болит
- Кривая обучения круче. Дашборды не бесплатны — их пишут запросами. Инженеры, выросшие на готовых экранах Datadog, неделю отскакивают от «чистого холста» query builder'а, прежде чем щёлкнет.
- Меньше turnkey-интеграций. Нет экосистемы агентов с 700 коннекторами. Если нужны метрики от SaaS-вендора, не говорящего OTel — мостик пишете сами.
- Логи — второго сорта. Honeycomb может принимать логи как события, но это не платформа лог-менеджмента. Команды с 50 ТБ/день неструктурированного stdout всё равно поставят Loki, ClickHouse или, да, Datadog Logs рядом.
- Меньше community и доков. Datadog Q&A — везде. Сообщество Honeycomb компактнее и экспертнее, но гуглить вы будете меньше, а официальную документацию читать больше.
Кому Honeycomb подходит
Инженерные организации, владеющие своими сервисами end-to-end, релизящие несколько раз в день и принимающие, что observability — это дисциплина, а не закупка. Особенно хорошо ложится в product-engineering команды, где разработчики пишут запросы сами, а не передают тикеты в SRE.
Side-by-side: где платформы действительно расходятся
| Параметр | Datadog | Honeycomb |
|---|---|---|
| Модель данных | Metrics + Logs + Traces (3 столпа) | Wide structured events (единая подложка) |
| Поддержка OpenTelemetry | Есть, но agent-first | Native, основной путь ingestion |
| Язык запросов | Tag-based, GUI + log queries (DDSQL beta) | Свой (не SQL); GUI с BubbleUp |
| AI / ML фичи | Watchdog anomaly detection, Bits AI assistant | Anomaly detection через BubbleUp + Query Assistant (LLM-помощник по запросам) |
| Модель ценообразования | Per-host (APM), per-GB (logs), per-custom-metric, per-RUM-session | Per-event ingested, предсказуемые тиры |
| On-prem | Private SaaS / data residency, полноценного on-prem нет | Нет (только облако) |
| Кривая обучения | Низкая для дашбордов, высокая для оптимизации цены | Средне-высокая для запросов, низкая для прогноза счёта |
| Интеграции | 700+ официальных | OTel-экосистема + native (меньше по числу, шире по протоколу) |
| High-cardinality дебаг | Возможен, но дорог (custom metrics) | Native и core (BubbleUp) |
Бенчмарки запросов: как быстро возвращается «покажи аномалию»
Публичные бенчмарки обеих платформ шумные — нагрузки слишком разные. Честное описание того, что сообщают клиенты:
| Тип запроса | Honeycomb (типично) | Datadog (типично) |
|---|---|---|
| Group by 4 полям по 1 млрд событий | 3–8 секунд | Нужны indexed logs или custom metrics; ≤10 с при pre-aggregation, минуты-часы при rehydrate из архива |
| Heatmap latency по сервисам за 24 ч | < 5 секунд | < 5 секунд (если APM-данные уже проиндексированы) |
| Причина аномалии через BubbleUp на 100 млн событий | 5–15 секунд | Прямого аналога нет; ближайший — Watchdog Insights, асинхронные находки |
Поиск трейсов по tenant_id=acme при 5 000 активных тенантов | < 10 секунд (native для событий) | Нужен tenant_id как custom dimension или indexed log field, иначе медленно |
Честный лимит: цифры — публичный list + клиентские репорты. Реальные enterprise-контракты различаются в 2–5 раз в зависимости от commitment, региона и переговоров. Не воспринимайте таблицу как закупочный документ.
Где прячутся затраты
Datadog
Публичные list-цены (per-host, в месяц, annual commitment, май 2026):
| Модуль | Цена | Скрытый риск |
|---|---|---|
| Infrastructure Pro | $15/host | Контейнеры считаются к лимитам хостов в плотных K8s-деплоях |
| APM | $31/host | Distributed tracing без корреляции с логами — половина ценности |
| Log Management | $0.10/GB ingest + $1.06–$2.50 за миллион indexed events | Тир indexed event важнее GB; неожиданные счета — от всплесков логов во время инцидентов |
| Custom Metrics | Первые 100 бесплатно, дальше $0.05/метрику/мес | High-cardinality теги множат это очень быстро |
| RUM | $1.50 за 1k сессий | Mobile + web считаются отдельно |
Для прод-окружения из 50 хостов с APM, логами (1 ТБ/мес, 10% индексируется) и 10 000 custom metrics — порядок $8 000–$12 000/мес. Pre-paid commit снимает 20–30%.
Honeycomb
Публичные list-цены (май 2026):
| План | Цена | Что входит |
|---|---|---|
| Free | $0 | 20 млн событий/мес, 60 дней retention |
| Pro | от ~$130/мес на команду | Кастомный объём событий, 60 дней retention, BubbleUp, Query Assistant |
| Enterprise | Custom | SSO, audit logs, dedicated support, расширенный retention |
Для сравнимой нагрузки (~1 млрд событий/мес, ~50 сервисов) enterprise-контракты обычно попадают в $3 000–$8 000/мес — иногда ниже, если не нужны RUM и широкий лог-менеджмент рядом.
Ловушка: команды на одном Honeycomb часто всё равно платят за лог-менеджмент в другом месте. Команды на одном Datadog часто платят втрое больше бюджета — из-за overrun по custom metrics и indexed logs. Ни один счёт не равен тому, что обещает страница с ценами.
Кому что выбрать
Выбирайте Datadog, если:
- Вы enterprise на разношёрстной инфраструктуре (AWS + Azure + on-prem + 50 SaaS-вендоров) и нужен единый дашборд для экзекутивов
- Вы ещё не на OpenTelemetry и не хотите мигрировать инструментацию
- Compliance требует широких pre-built аудитных дашбордов (PCI, HIPAA, SOC 2)
- SRE-команда устроена вокруг «эксплуатируем платформу» и живёт в дашбордах, а не в запросах
Выбирайте Honeycomb, если:
- Ваши инженеры сами пишут запросы для дебага своих сервисов (DevOps-зрелость высокая)
- Вы уже инвестировали в OpenTelemetry SDK
- High-cardinality поля (tenant, user, feature flag, region) критичны для дебага
- Предсказуемость расхода важнее абсолютной широты
- Релизите несколько раз в день и важнее «что изменилось?», чем «какое среднее»
Берите обе (растущий паттерн 2026): Datadog под инфраструктуру и объём логов, Honeycomb под application-level observability, где инженеры реально дебажат. Совокупный счёт выше, но тулзы дополняют друг друга. Несколько публичных Series-C+ инженерных команд именно так и устроены.
Контр-тезис
Расхожее мнение: Datadog — это «дорогая enterprise-опция», Honeycomb — «модный observability для тех, кто может себе позволить». Реальность из клиентских кейсов 2026: большинство SRE обнаруживают, что Datadog как дешёвый агент-монитор тихо становится дорогим, когда нужен серьёзный дебаг — в момент, когда требуются unindexed log queries или high-cardinality custom metrics. А Honeycomb, проданный как премиум, для high-cardinality workloads нередко выходит дешевле, потому что events-based pricing не штрафует за добавление измерений.
Цена со страницы — не та, которую вы платите. Вы платите ровно за то, что дебажите.
Где рядом стоит PanDev Metrics
PanDev Metrics — не observability-тулза. Он не заменяет Datadog или Honeycomb и не пытается. Что он делает: тянет данные об инцидентах и деплоях из PagerDuty (или аналогов) и Git-провайдеров и считает DORA-метрики — включая MTTR, change failure rate и deployment frequency — в разрезе команд и сервисов. Граница чёткая: Datadog/Honeycomb отвечают на «что сломано прямо сейчас». PanDev отвечает на «как часто это ломается, сколько занимает починка и какие команды владеют какими инцидентами». Большинству инженерных организаций нужны оба, и интегрируются они аккуратно.
Подробнее про MTTR в общей картине DORA — в материале MTTR — скорость восстановления. Про саму модель данных observability — в observability-стеке для инженерных команд и observability в Kubernetes.
FAQ
Honeycomb дешевле Datadog?
Для high-cardinality application-нагрузок — часто да: events-based pricing не умножается с измерениями. Для широкого инфраструктурного мониторинга по сотням хостов и SaaS-вендорам Datadog может быть дешевле, потому что Honeycomb не заменяет лог-менеджмент. Прогоните обе модели по своему реальному телеметрическому объёму перед решением.
Можно ли использовать OpenTelemetry с обоими?
Да. Оба поддерживают OTel. Honeycomb рассматривает OTel как основной путь; Datadog тоже поддерживает, но его агентные коллекторы и проприетарные протоколы пока зрелее. Если важна портируемость OTel и борьба с vendor lock-in — Honeycomb безопаснее.
Что лучше для маленьких команд: Datadog или Honeycomb?
Для команд до 20 инженеров с фокусной аппликухой: free-тира Honeycomb (20 млн событий/мес) плюс Pro обычно хватает по observability без удара по бюджету. У Datadog free-тир есть, но счётчик стартует сразу при любой осмысленной телеметрии. Оговорка: маленькие команды на широком SaaS-стеке могут предпочесть готовые интеграции Datadog ручному написанию OTel-экспортёров.
У кого лучше AI-фичи в 2026?
Bits AI у Datadog зрелее как универсальный ассистент — он коррелирует инциденты, суммирует алерты и интегрирован со всей продуктовой поверхностью. Query Assistant у Honeycomb уже, но отлично выполняет узкую задачу — «преврати мой вопрос на английском в Honeycomb-запрос». Опытного SRE ни тот, ни другой пока не заменяет; оба заметно ускоряют онбординг новых инженеров. Развёрнутый взгляд на тренд — в статье эффект AI-копайлотов на инженерную работу.
Легко ли мигрировать с Datadog на Honeycomb?
Зависит от того, какую инструментацию вы успели внедрить. Если уже на OpenTelemetry SDK (или готовы мигрировать с dd-trace библиотек Datadog на OTel) — слой данных портируем. Тяжёлая часть не в ingest, а в переучивании инженеров с «сначала дашборд» на «сначала запрос». Планируйте квартал параллельной работы, а не выходные на cutover. Практики, как пройти такой переход без выгорания, разбираем в практиках on-call ротации и шаблонах incident postmortem.
Что реально ожидать
Выбирайте инструмент под то, как ваши инженеры хотят дебажить, а не под тот, что выиграл feature-матрицу на слайде Gartner. Datadog отличен на вопросе «как выглядит моя инфраструктура» и болезнен на «почему конкретный пользователь поймал 500». Honeycomb — наоборот. Большинство команд, выбравших не то, подгоняли инструмент под предпочтения CFO, а не под workflow on-call инженера — и расплата приходит через полгода в виде либо overrun'а бюджета, либо медленного инцидента.