Deployment Frequency: метрика частоты деплоев в DORA с бенчмарками

Elite-команды деплоят в production в 973 раза чаще low-перформеров — и при этом ломают прод реже. Это главный вывод DORA 2023 State of DevOps, который перевернул десятилетие веры в «move fast and break things»: скорость и стабильность коррелируют, а не противоречат друг другу.
Deployment Frequency — самая простая на вид из четырёх DORA-метрик и самая часто читаемая неправильно. Команда может выкатывать 10 раз в день на staging, никогда не доезжать до прода — и называть себя elite. Этот глоссарий разбирает метрику до конца: формула, бенчмарки, что считается деплоем, и где число врёт.
{/* truncate */}
Deployment Frequency — определение DORA
Deployment Frequency (DF) — одна из четырёх метрик, определённых командой DevOps Research and Assessment (DORA) в Google Cloud. Измеряет, как часто организация успешно выкатывает код в production.
Метрику популяризировали Nicole Forsgren, Jez Humble и Gene Kim в книге Accelerate (2018), показав, что высокая частота деплоев коррелирует с прибыльностью, ростом доли рынка и снижением выгорания — не только с инженерной производительностью. State of DevOps Report 2023, построенный на 36 000+ респондентов за десять лет, подтверждает паттерн в каждой годовой когорте.
DF — это throughput-половина DORA. В паре с Lead Time for Changes она отвечает на вопрос «как быстро ценность доходит от merge до пользователя». Стабильность измеряют отдельно Change Failure Rate и MTTR — про взаимодействие четырёх метрик подробно в полном гайде по DORA.
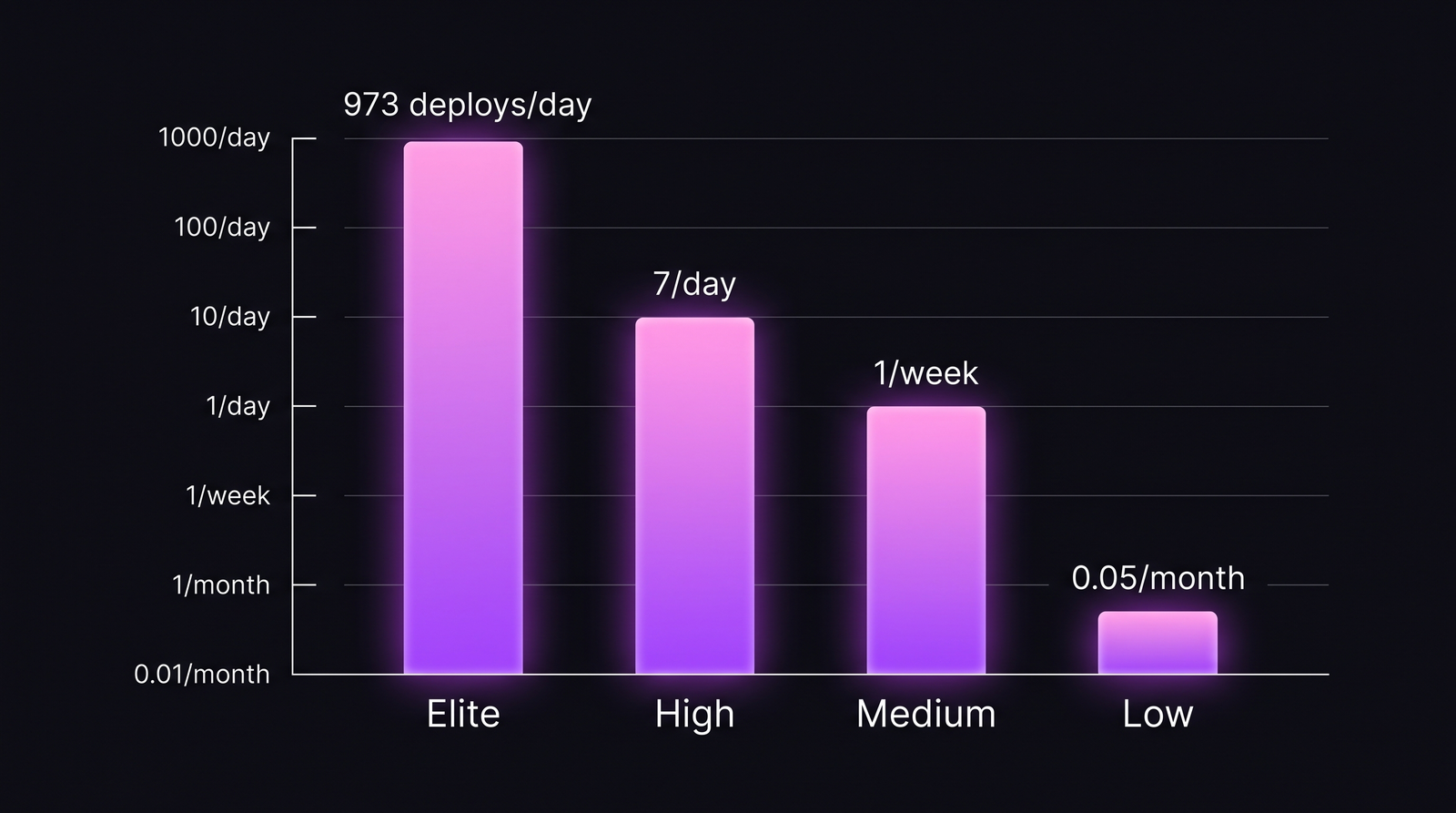 Разрыв на порядок между тирами. Когорта DORA 2023.
Разрыв на порядок между тирами. Когорта DORA 2023.
Формула расчёта
Deployment Frequency = Успешные production-деплои ÷ Временное окно
Выберите одно окно и держитесь его. Окно зависит от каденса:
| Каденс | Окно отчётности | Как читать |
|---|---|---|
| Несколько в день | День или неделя | «медиана 12 деплоев/день» |
| Ежедневно | Неделя | «~5/день, 25/неделю» |
| Еженедельно | Месяц | «4-5 деплоев/месяц» |
| Раз в месяц и реже | Квартал | «2 деплоя/квартал» |
Два практических правила:
- Медиана, не среднее. Один день CI-шторма с 40 деплоями ломает месячное среднее. Считайте медиану по будням.
- Только успешные. Упавший пайплайн, который не доехал до прода, — не деплой. Откатанные релизы включайте (они доехали), aborted-запуски — нет.
Что считать «деплоем»
Здесь метрика разваливается у половины команд, которые её считают.
Только production. Staging, QA, preview-окружения — это не deployments для DORA. Полезные внутренние сигналы, но официальная метрика про код, доехавший до пользователей.
Один деплой на окружение, не на изменение. Если в одном релизе уезжает 12 смёрженных PR — это один деплой, не 12. Единица счёта — событие релиза, не изменение.
Микросервисные нюансы. Команда с 80 микросервисами, деплоящая каждый независимо, отчитается о 80x деплоев по сравнению с монолитом, выкатывающим ту же фичу. И DORA, и поздние работы Forsgren советуют считать DF на деплоимый артефакт или на команду, а не общим org-числом, которое награждает за дробление.
| Сценарий | Считается как |
|---|---|
Push в main → auto-deploy в прод, успех | 1 деплой |
| То же, но пайплайн упал на smoke-тестах | 0 деплоев |
Push в main → деплой только на staging | 0 деплоев |
| Rolling-релиз в 5 prod-регионах | 1 деплой (один релиз) |
| 12 PR смёржены и собраны в один релиз | 1 деплой |
| Hotfix прямо в прод | 1 деплой |
Бенчмарки 2026
Отчёт DORA 2023 определяет четыре тира производительности. Обновление 2024 их сохранило, и когорты 2026, которые я вижу у клиентов PanDev Metrics, ложатся близко — хотя у хайпскейл-компаний планка «elite» уползла вверх.
| Тир | Deployment Frequency | Типичный профиль |
|---|---|---|
| Elite | On-demand — несколько раз в день | Trunk-based, полный CD, feature flags |
| High | От раз в день до раз в неделю | Зрелый CI/CD, weekly release train |
| Medium | От раз в неделю до раз в месяц | Ручные approval gates, release windows |
| Low | Реже раза в месяц | Долгоживущие feature-ветки, батчированные релизы |
Пиковые цифры Amazon (~50 млн деплоев/год по сервисам в 2015, ~1.5/сек) и непрерывный деплой Netflix — выбросы, не цель. Для продуктовой команды 20 человек 3-5 production-деплоев в рабочий день — сильный elite-сигнал.
Контраргумент, который стоит держать в голове: считать «деплои в день» в команде без trunk-based development — это в основном шум. Долгоживущие feature-ветки раздувают метрику, когда наконец мёржатся пачкой, и проседают, когда застревают. DF работает как опережающий индикатор только если branching-модель это позволяет.
Почему чаще = безопаснее (вопреки интуиции)
Дефолтная ментальная модель: больше изменений = больше риска. Данные DORA говорят обратное. Почему?
Меньшие чейнджсеты. Деплой с 2 PR имеет меньше взаимодействий для дебага, чем деплой с 60. Когда что-то ломается, понятно, где смотреть.
Быстрая обратная связь. Баг, выкаченный сегодня, разбирает автор сегодня. Баг четырёхнедельной давности разбирает кто-то, кто читает историю коммитов.
Натренированная мышца отката. Команда, которая деплоит каждый день, делала rollback сотни раз. Команда с квартальным релизом не откатывалась с прошлого квартала — процедура заржавела.
Blast radius. Ежедневные деплои обычно идут с feature flags, canary-релизами и постепенной раскаткой. «Деплой» отвязан от «релиза пользователю». Упавший деплой на 0.1% canary затрагивает 0.1% пользователей.
Сводящий это в одно открытие DORA 2023: у elite-команд change failure rate около 5% и MTTR меньше часа. Они не избегают сбоев — они ловят и восстанавливаются за минуты, а не дни. См. Change Failure Rate: что считать нормой про сторону стабильности.
Что снижает Deployment Frequency
Большинство low-результатов — это не проблема инженерных скиллов. Это проблема процесса. Обычные виновники:
| Что давит | Механизм | Куда чинить |
|---|---|---|
| Ручные approval gates (CAB) | Каждый релиз ждёт несколько дней review-комитета | Заменить автоматическими политиками + post-deploy review |
| Медленный CI (>30 мин) | Инженеры батчат изменения, чтобы не ждать | Параллелить тесты, кешировать билды, цель <10 мин |
| Release windows («только четверг 18:00») | Теоретический максимум — 1/неделю | Развести деплой и релиз через feature flags |
| Долгоживущие feature-ветки | Big-bang merges дают месячный burst-паттерн | Trunk-based + маленькие PR |
| Культура страха («прошлый деплой сломал прод») | Инженеры не деплоят перед выходными | Инвестировать в rollback-автоматизацию; безопасные деплои уменьшают страх |
| Связанные деплои (надо ехать A и B вместе) | Сервисные зависимости требуют батчей | Backward-совместимые API, expand/contract миграции |
Если вы просите команду «деплоить чаще», не убрав это всё, — вы просите её брать больше риска. Команда правильно откажется. Практическая последовательность шагов есть в плейбуке Monthly to Daily.
Честный лимит: «5 деплоев/день» почти ничего не значит для команды из трёх. Правильный знаменатель для DF — на деплоимый сервис, не на инженера. Три человека владеют 8 сервисами и катят каждый раз в день — это 24/день. Шум от выбора архитектуры, а не elite-throughput.
В PanDev Metrics мы считаем Deployment Frequency автоматически из CI/CD-событий и Git-тегов — с разбивкой по сервису, по команде и по окружению, с rollback-aware фильтрацией, чтобы провалившиеся деплои не раздували число. Тот же пайплайн считает Lead Time, MTTR и Change Failure Rate, потому что ни одну DORA-метрику нельзя читать изолированно. Про lead time подробно в Lead Time for Changes: 4 стадии, про восстановление — в MTTR: бенчмарки скорости восстановления.
FAQ
Deployment Frequency — это что?
DORA-метрика, измеряющая, как часто команда успешно выкатывает код в production. Считается как деплои за временное окно (день/неделя/месяц), отчитывается медианой.
Сколько раз в день деплоят elite-команды?
DORA 2023 определяет elite как on-demand, несколько раз в день. На практике это от 3 до 50 production-деплоев в рабочий день для продуктовых команд. Хайпскейл (Amazon, Netflix, Google) деплоит тысячи сервисов тысячи раз в день, но эти числа не работают как бенчмарк для обычной команды.
Какой нормальный Deployment Frequency?
Для типичной инженерной организации 10-30 человек со зрелым CI/CD: 1-5 деплоев в день на сервис — нормально и здорово. Реже раза в неделю — сигнал, что в пайплайне или процессе есть гейт. Чаще 50/день на сервис часто означает, что вы считаете hotfix-ы или шумные auto-деплои.
Считаются ли hotfix-ы в Deployment Frequency?
Да. Любой успешный деплой в прод считается — плановый, внеплановый, hotfix или фичевый релиз. Если hotfix-ы доминируют — это полезный сигнал: смотрите DF в паре с Change Failure Rate, потому что высокий DF за счёт hotfix-ов — это проблема стабильности, а не победа throughput-а.
Как считать Deployment Frequency для multi-service архитектуры?
Считайте на деплоимый сервис или на команду, не одним org-wide числом. Org-wide деплои в день награждают за дробление сервисов без улучшения доставки. Полезный вопрос: «какая медиана каденса деплоев у каждого сервиса?». Затем агрегируйте по командам, чтобы сравнивать сравнимое.
Куда это вас оставляет
Если ваша команда в medium или low — вы не провалились. Вы описываете трение в релизном процессе. DF — самая простая DORA-метрика для измерения и самая сложная для сдвига, потому что сдвиг означает убрать ручные гейты, медленный CI и культурную осторожность, которая защищала вас в прошлый раз, когда деплой сломал прод. Начинайте с разделения «деплоя» и «релиза» через feature flags. Дальше всё едет за этим.
Цифра, которую стоит защищать через год, — не «100 деплоев в день». А: медиана дневных деплоев на сервис, change failure rate под 15%, MTTR под одни сутки. Это настоящий elite-сигнал. Всё остальное — театр.