DORA × Engineering Cost: ROI, который не виден

VP Engineering приходит на квартальный ревью с чистым DORA-дашбордом: lead time с 9 дней до 4, deployment frequency с 1.2 до 2.8 в неделю, change failure rate с 18% до 11%. CFO терпеливо слушает и задаёт единственный важный вопрос: «А сколько мы на этом сэкономили в деньгах?» В комнате становится тихо. DORA-инструмент этого не знает. Финансовый инструмент тоже не знает — он не видит deploy-данные. CTO начинает спорить «по принципу». Через два квартала бюджет платформенной команды режут, чтобы нанять ещё одного сейлза.
Большинство engineering-организаций ведут DORA и cost в двух разных системах. Sleuth, Swarmia, LinearB показывают DORA. Jellyfish (его отдельный finance-модуль) и Faros показывают cost. Отчёты DORA State of DevOps явно связывают четыре DORA-метрики с организационными результатами — но на уровне outcomes, не на уровне долларов. Чтобы перевести «мы сократили lead time с 9 дней до 4» в число, которое CFO готов защищать, нужны оба источника данных в одном запросе. Эта статья проходит через четыре точки интеграции и заканчивается практическим примером Q1 → Q2 с квартальным ROI 2.73x.
{/* truncate */}
Почему DORA-only и cost-only оба проваливают борд
DORA-only — более частый провал. Команда умеет доказать, что delivery-система стала лучше. Доказать, что компания стала богаче — не умеет. Совет директоров инвестирует не в улучшения системы доставки — он инвестирует в cash flow. Красивый график lead time, идущий вниз — это артефакт, а не защита бюджета.
Cost-only ошибается зеркально. Финансы видят, что engineering-line вырос на $250K, и спрашивают, что изменилось. Engineering отвечает: «мы зашиппали больше фичей». Финансы спрашивают: «насколько больше». Без DORA «больше фичей» — это не число. Без cost «меньше дней lead time» — тоже не число. Нужны оба.
Глубже: два датасета отвечают на разные вопросы, но на одной грануле. DORA — per-deploy или per-PR. Cost-per-feature — per-issue или per-project. Можно сделать join по feature_id или project_id, если оба живут в одной системе. Если в двух системах с разными identity-схемами — join не сделать вообще. И это дефолтное состояние индустрии.
PanDev Metrics ведёт все четыре DORA-метрики (deployment_frequency, lead_time_for_changes, change_failure_rate, MTTR) и cost-per-feature в одной Postgres-схеме. Один и тот же date-фильтр, project-фильтр, department-фильтр. Запрос «для проектов, где lead time упал больше чем на 30%, какой был дельта cost-per-feature?» — это один SQL с двумя join'ами. Cost-сторону мы разобрали в Cost-per-Feature: SQL-формула, которая работает. Здесь — интеграция.
Четыре точки интеграции: DORA × cost-рычаги
Каждая DORA-метрика связана со своим cost-рычагом. Метрика улучшается — рычаг сдвигается. Фокус в том, чтобы знать коэффициент конверсии.
| DORA-метрика | Что дешевеет при улучшении | Механизм |
|---|---|---|
| Lead time for changes | Cost-per-feature | Меньше времени в WIP × loaded hourly rate. Фича, висящая 9 дней при 4 инженерах, стоит дороже той же фичи за 4 дня. |
| Deployment frequency | Cost throughput / cost-per-deployed-feature | Больше фичей за квартал на ту же payroll. Знаменатель фиксированный, числитель растёт. |
| Change failure rate | Стоимость rework (rollbacks, fixes, hot-patches) | Каждый failed deploy = X engineer-часов реакции на инцидент + Y часов фикса + Z часов re-deploy. Умножить на loaded rate. |
| MTTR | Стоимость инцидента на burn rate | Каждая минута инцидента — оплачиваемый headcount в war-room режиме плюс opportunity cost остановленной фичевой работы. |
Это четыре независимых ROI-ящика на одной тумбочке. Открываются по отдельности. Усиливают друг друга — быстрый pipeline обычно двигает все четыре сразу, и именно это делает математику пакета интересной и слегка опасной (про это будет в секции про лимиты).
Lead time → cost-per-feature
Самая чистая механическая связь. Фича в WIP жжёт деньги. Cost-per-feature примерно равен:
cost_per_feature ≈ Σ (engineer-часы на фиче × loaded_hourly_rate)
Сократите календарное время вдвое без добавления людей — engineer-часы тоже падают, частично потому что меньше idle-ожидания между code review, QA и merge, частично потому что падает overhead контекстных переключений. Accelerate (Forsgren, Humble, Kim) показывает: elite-команды живут с lead time меньше суток; low-perfomers — недели и месяцы. Долларовый разрыв заметен. Четыре стадии lead time мы разбираем в Lead Time: 4 стадии и где время реально прячется.
Deployment frequency → cost throughput
Throughput — это игра со знаменателем. Если команда стоит $400K в месяц и шиппит 8 фичей — это в среднем $50K за фичу. Поднимите частоту — 14 фичей за те же $400K — $28.5K за фичу. Команда не подешевела. Компания стала шиппить больше за тот же доллар.
Это работает только если лишние фичи — реальная ценность, а не vanity-deployments. Удвоить частоту, разбив одну фичу на десять микро-деплоев — это игра с метрикой, не финансовая победа. Честная версия пары — частота деплоев + count завершённых фичей, а не deploy count в чистом виде.
Change failure rate → rework cost
У каждого failed deploy есть кассовый чек:
- Время инженеров на rollback (обычно 2–6 engineer-часов).
- Fix-работа (от 4 часов до спринта).
- Re-deploy и верификация (1–3 часа).
- Customer-impact opportunity cost (потерянная выручка во время outage).
Отчёт DORA 2024 ставит 0–5% как elite, 5–10% как high, 10–15% как medium, более 15% — low. Математика: при loaded rate $46/час команда, делающая 40 деплоев за квартал с CFR 18%, прожигает примерно 7 failed × 12 engineer-часов × $46 = $3 860 за квартал только на rework, не считая customer impact. При CFR 11% та же команда тратит $2 360 — разница $1 500 на rework плюс всё, что инциденты на стороне клиента стоили бы. Глубокий разбор в Change Failure Rate: почему 15% — норма, а 0% — подозрительно.
MTTR → стоимость инцидента на burn rate
MTTR — самая прямая долларовая связь. Каждая минута активного P1 — оплачиваемый burn rate. Команда из 15 инженеров при $46/час loaded теряет примерно $11.50 за engineer-минуту, или $172.50 в минуту, когда вся команда в war room. Сократить MTTR с 90 минут до 35 — отвоевать 55 минут × $172.50 ≈ $9 500 за инцидент только на времени команды, не считая выручки на клиентской стороне, которая часто превышает engineering-сторону на порядок.
Практический пример: Q1 → Q2 2026, апгрейд pipeline
Команда из 14 инженеров (SaaS) вложила $250K в апгрейд CI/CD и review-процесса (4 инженера × 5 недель выделенной платформенной работы, fully loaded). DORA-метрики сдвинулись. Cost-per-feature тоже. Интегрированная ROI-математика — то, что позволило проекту пережить следующий бюджетный ревью.
| Метрика | Q1 (до) | Q2 (после) | Δ |
|---|---|---|---|
| Lead time for changes | 9 дней | 4 дня | −56% |
| Deployment frequency | 1.2 / нед | 2.8 / нед | +133% |
| Change failure rate | 18% | 11% | −7 п.п. |
| MTTR | 90 мин | 35 мин | −61% |
| Cost-per-feature (avg) | $34K | $24K | −$10K |
| Фичей зашиппано за квартал | 8 | 14 | +6 |
Финансовая конвертация:
- Per-feature экономия от компрессии lead time: $10K × 14 фичей в Q2 = $140K сэкономлено относительно Q1-экономики.
- Throughput value от лишних деплоев: 14 фичей × ~$30K средней revenue impact на shipped-фичу = $420K инкрементального вклада в выручку (среднее ARR-per-feature по этому сегменту).
- Rework avoided от падения CFR: 40 деплоев × 7 п.п. × ~$300/инцидент в blended (eng + customer-side) ≈ $84K избежано.
- Incident cost avoided от падения MTTR: 4 инцидента × 55 мин × $172.50/мин ≈ $38K избежано.
Итог Q2 net: $140K + $420K + $84K + $38K = $682K ценности против $250K вложений. Это 2.73x за один квартал. В пересчёте на год при том же run-rate — порядка 10–11x. Проект из «engineering хочет ещё бюджета» превратился в защищаемую перед бордом строку, которую CFO в следующем квартале презентовала сама.
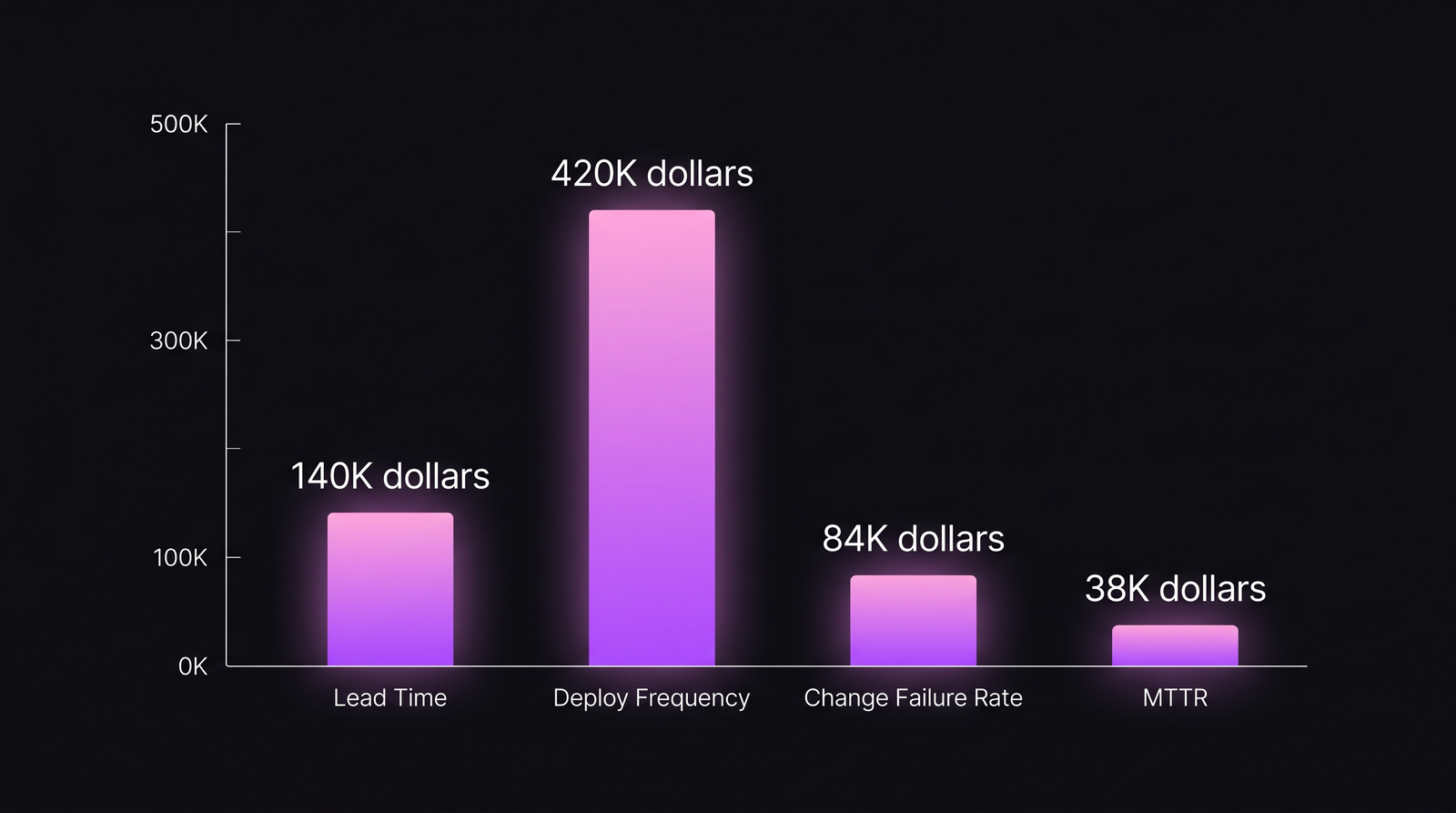
Долларовый вклад по DORA-рычагам в Q2 2026 — больше всего даёт throughput, но кейс делает именно пакет.
Как это реально посчитать
Три предусловия, ни одно не опционально:
- Один источник правды для обоих датасетов. Если DORA и cost живут в двух тулах — join не сделать. Либо одна платформа, в которой есть оба, либо warehouse и оплаченная интеграционная пошлина.
- Соглашение о ветках с task ID.
feature/PROJ-1180позволяет cost-per-feature, lead time, deploy events и инцидентам линковаться к одному идентификатору. Без него join — это в лучшем случае нечёткий matching. Механика cost-per-feature разобрана в Cost-per-Feature: SQL-формула, которая работает. - Loaded hourly rate, а не голая зарплата. Долларовая математика разваливается, если использовать не ту ставку. Пять отдельных методов ROI и когда какой применять — в Engineering ROI: 5 методов, которые проходят board review.
В PanDev Metrics это один cross-tab дашборд: DORA-чарт сверху, cost-per-feature панель снизу, оба под одним project picker и date range. Вопрос «ROI вложений в Q2 платформу» закрывается двумя фильтрами, а не data engineering-проектом на 6 недель. Это и есть единственная причина, по которой эта статья существует — большинство команд не могут провести этот анализ вообще, потому что их инструменты не один инструмент.
Честный лимит: корреляция — не причинность
Здесь математика платит skepticism tax. Апгрейд pipeline уменьшил lead time и cost-per-feature и CFR и MTTR. Но также, вероятно:
- Поднялся team morale после долгого участка трения.
- Новый pipeline стало проще понимать, и PR'ы стали меньше.
- В середине квартала пришёл сильный senior и повлиял на review-культуру.
- Был один особенно чистый квартал по feature scoping со стороны продакта.
Данные PanDev говорят, что изменения произошли вместе. Они не говорят, какая именно доля улучшений — заслуга апгрейда pipeline, а какая — остальных переменных. Считайте 2.73x ROI пакета этого квартала, а не точным вкладом одной только инвестиции в платформу. Изолированную атрибуцию даёт hold-out команда или pre-registered эксперимент, и большинство engineering-организаций не могут позволить себе такой уровень строгости.
Честный разговор с CFO звучит так: «Мы вложили $250K в апгрейд платформы. Квартал, в который этот апгрейд попал, зашиппил $682K измеримой ценности сверх run rate предыдущего квартала. Платформа была самым крупным сознательным изменением. В следующем квартале мы повторяем инвестицию, чтобы посмотреть, повторится ли эффект.» Эта формулировка переживает аудит. «Наш апгрейд pipeline сэкономил $682K» — нет.
Что меняется в следующем бюджетном собрании
Три конкретных шага в порядке убывания эффекта:
- Перестаньте защищать DORA-улучшения «по принципу». Приносите долларовое число. Если не можете — значит, ваши инструменты разделены, и это и есть отсутствующий бюджет.
- Аннуализируйте осторожно. Квартал 2.73x — это не год 10x. Эффекты часто плоскают, когда лёгкие победы собраны. Защищайте следующий квартал, а не три года.
- Pre-register следующую ставку. До того как платформенный бюджет придёт, запишите: какие DORA-дельты вы ожидаете, какой долларовый эффект они должны принести и что считалось бы провалом. Этот документ превращает engineering-инвестицию из настроения в проверяемую гипотезу.
DORA без cost — это delivery-отчёт. Cost без DORA — это payroll-ревью. Интеграция — это защита бюджета. Большинство CTO до сих пор спорят «по принципу», потому что инструменты их к этому вынуждают. Те, кто перестанет — обнаружат, что в комнате совета математика становится сильно тише.