Kubernetes observability для инженерных команд в 2026

Платформенная команда, управляющая 11 production K8s-кластерами, собирает 94 000 метрик каждые 15 секунд, 2.4 ТБ логов в день в Loki и держит Grafana с 340 дашбордами. Когда VP of Engineering спросил "шипим ли мы на K8s надёжно?", никто не смог ответить быстрее чем за час. У них есть cluster observability. Нет engineering observability.
Это две разные задачи. Cluster observability отвечает, здоровы ли поды. Engineering observability отвечает, здорова ли инженерка поверх этих кластеров — быстро ли идут деплои, редки ли откаты, ждут ли разработчики инфры или воюют с ней. Большинство K8s-шопов решили первую задачу и забыли про вторую. Ежегодный отчёт CNCF 2024 сообщил: 68% корпоративных пользователей K8s борются с тем, чтобы "сделать observability actionable" — вежливая формулировка для "метрики есть, решения из них не выходят".
{/* truncate */}
Что не решают cluster-дашборды
Cluster-дашборды отвечают на: "здорова ли моя инфра прямо сейчас?"
Engineering observability отвечает на:
- Шипим ли мы на эти кластеры быстрее или медленнее, чем в прошлом квартале?
- Когда разработчик пушит в main, через сколько изменение обслуживает трафик?
- Какие сервисы съедают больше инженерного времени, чем приносят ценности?
- Какие команды застряли в борьбе с K8s, а какие реально его используют?
Это не Prometheus-запросы. Они получаются из корреляции cluster-событий (деплои, откаты, HPA-скейлинг, рестарты подов) с инженерными событиями (коммиты, PR, инциденты, on-call). Большинство инструментов делают одну сторону. Мало кто — обе.
CNCF State of Observability 2024 показало: команды с коррелированными cluster- и engineering-сигналами имеют на 34% быстрее MTTR по production-инцидентам, чем команды, использующие только cluster-метрики. Разрыв не потому, что инструменты лучше, — а потому что во время инцидента не надо шарить экран между Grafana и Jira.
Стек, который реально работает в 2026
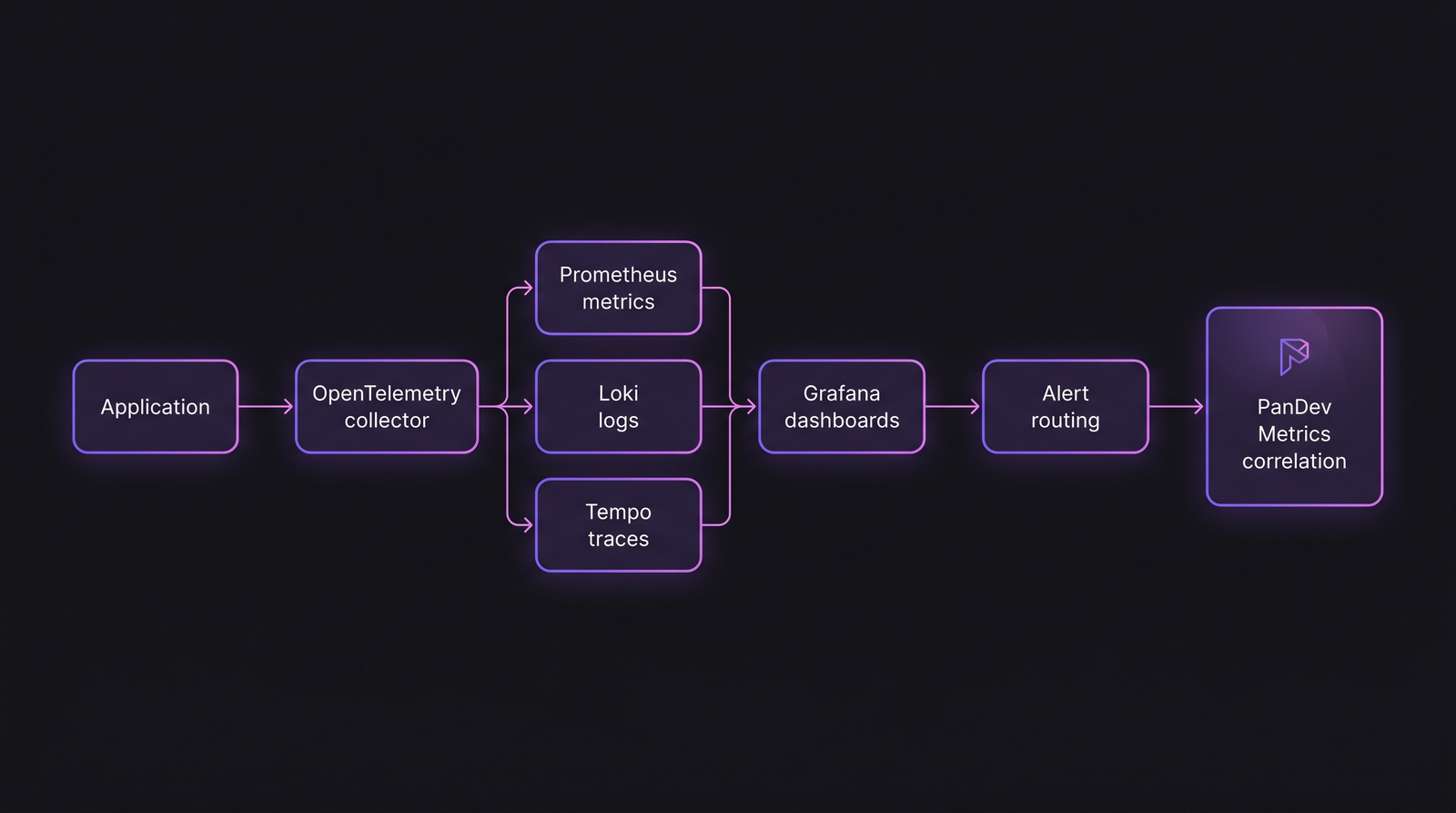 Типичный стек observability в 2026. Слой, который большинство упускает: корреляция cluster-телеметрии с engineering-телеметрией на границе.
Типичный стек observability в 2026. Слой, который большинство упускает: корреляция cluster-телеметрии с engineering-телеметрией на границе.
База (есть у всех)
| Компонент | Назначение | Что стоит знать |
|---|---|---|
| Prometheus | Хранение метрик | 15s scrape, 15d retention по умолчанию (поднимать до 30d+) |
| Grafana | Дашборды и алертинг | Tempo/Loki панели нативно с v10 |
| Loki | Агрегация логов | Label-based, дешевле ELK на масштабе |
| Tempo / Jaeger | Распределённая трассировка | Tempo — дефолт в CNCF-стеке, Jaeger жив |
| OpenTelemetry | Стандарт инструментации | К 2025 — явный победитель над вендорскими SDK |
| kube-state-metrics | Состояние объектов K8s | Не то же, что metrics-server; нужны оба |
Если вы ещё на Prometheus Operator без OpenTelemetry-коллекторов — отстаёте на один апгрейд стека. Тренд KubeCon 2024 — явно OpenTelemetry-first: не потому что Prometheus плох, а потому что OTel позволяет менять бэкенд без переинструментации приложений.
Слой, который большинство упускает
Engineering-aware observability. Cluster-метрики сами по себе не отвечают "шипим ли мы хорошо?". Нужна корреляция деплоев с:
- Git-коммитами (кто написал что, к какому таску привязано)
- Lead time PR (от открытия до мерджа)
- Успехом/откатом деплоев
- Дельтой error rate на деплой (не overall error rate — изменение после каждого деплоя)
- Частотой on-call-прерываний на сервис
Здесь измерение становится интересным. Сервис с 99.95% uptime, но 40 on-call-вызовов в неделю — нездоровый, он выживает на человеческом труде. Cluster-дашборд этого не покажет. Engineering-коррелированный вид — покажет.
Что трекать, по ролям
Для SRE / платформенных инженеров
| Метрика | Таргет | Красный флаг |
|---|---|---|
| P99 pod scheduling latency | <2с | >10с (насыщение планировщика) |
| Crash loops в день | <3 на кластер | 10+ в день (нестабильная платформа) |
| Эффективность HPA | >95% | <80% (реактивное масштабирование ломается) |
| Image pull P95 | <30с | >2 мин (проблема с реджистри/сетью) |
| etcd latency P99 | <100мс | >500мс (замедление всего кластера на подходе) |
Для инженерных лидеров
| Метрика | Таргет | Красный флаг |
|---|---|---|
| Deployment frequency (на команду) | Ежедневно+ | Раз в неделю и реже |
| Lead time от merge до прода | <30 мин | >2 часов |
| Change failure rate (деплои с откатом) | <15% | >25% (DORA elite-порог) |
| MTTR | <1 час | >4 часов |
| % деплоев, откаченных автоматически | >80% | <50% (ручной откат — зрелость ниже) |
Для инженерных менеджеров (уровень команды)
| Метрика | Что раскрывает |
|---|---|
| Инженерное время, потерянное на инфру (за спринт) | Трение платформы |
| PR, откаченные за 48 часов | Проблема доверия к деплою |
| Сервисов на on-call инженера | Когнитивная нагрузка |
| Сервисов без owner | Bus-factor / сиротский риск |
| Падений пересборки контейнеров в день | Надёжность CI |
Последняя — тихая метрика. Команда с 50 пересборками/день и 8% падений теряет 4 цикла пересборки впустую в день. По 15 минут на цикл — это час инженерного времени в день на команду, невидимый на Grafana, очень видимый в зарплате.
Как PanDev Metrics коррелирует это
Куда встраивается продукт: тянем git-коммиты (через GitHub/GitLab/Bitbucket), IDE heartbeat (чтобы знать, в каком сервисе инженеры работали), и deployment-события из CI/CD (GitHub Actions, GitLab CI, Jenkins). Коррелируем это с cluster-событиями — конкретно откатами, HPA-скейлингом, рестартами подов.
Итог: вид, отвечающий на "какие сервисы съели больше инженерных часов в квартале, и какое у них соотношение деплой/инцидент?". Сервис, требующий 220 инженерных часов в квартал и откатывающийся каждые 3-й деплой, держится командой, а не платформой. Такого сигнала cluster-дашборды не дают.
Честный caveat: наши cluster-интеграции работают через Prometheus webhook-события и Kubernetes Event webhooks. Мы не гоняем агента внутри кластера. Командам, которым нужны глубокие in-cluster метрики (eBPF-трейсы, container-runtime телеметрия), параллельно нужны Prometheus + OTel. Мы — correlation-слой, не замена.
Антипаттерны, которые встречаем часто
1. "Дашборд на команду" — взрыв. 40 команд, 40 дашбордов, никто не знает, какой авторитетный. Консолидируйте в role-based дашборды (SRE, EM, CTO) и дайте фильтры.
2. Усталость от "алертов на всё". Бенчмарк PagerDuty 2024: команды, генерирующие больше 14 пейджингов на инженера в неделю, имеют alert fatigue и реально реагируют медленнее. Порог: алерт на симптомы, которые чувствуют пользователи, а не на причины, которые вы предполагаете.
3. "Трассировка без стратегии сэмплинга". Head-based sampling 1% — дефолт. В сервисе с большим RPS 1% — значит пропускать long-tail (а это и есть инциденты). Tail-based + head-based для объёма — best practice 2026, доступна в OTel Collector с v0.100.
4. "Нет SLO, только uptime". SLO привязывают алертинг к user experience. Сервис с 99.9% uptime может быть непригоден, если P99 latency — 8 секунд. Меряйте опыт-определяющие метрики и ставьте error budgets против них.
Контринтуитивный тезис
Большая часть боли с K8s observability в 2026 — культурная, а не техническая. Инструменты (Prometheus, Grafana, OTel, Tempo, Loki) production-solid уже 2+ года. Сломано — кто владеет дашбордами, кому пейджат и что считается "здоровым". Три команды, с которыми мы работали, починили observability не покупкой новых инструментов, а удалением 60-80% дашбордов и консолидацией остальных.
Честный лимит: наш взгляд смещён к командам, использующим и IDE-плагины, и cluster-интеграции — это 40-50 компаний в нашей базе на момент написания. Это конкретный срез (в основном B2B SaaS и финтех), не весь K8s-рынок. Команды EKS на FAANG-масштабе имеют другие проблемы, и наш сигнал там тоньше.
Что почитать
- Как внедрить DORA Metrics в команду за 2 недели
- MTTR: почему скорость восстановления важнее предотвращения всех сбоев
- On-prem деплой: PanDev Metrics в Docker и Kubernetes
Если ваш K8s observability-стек стоит вам полной FTE только на поддержание зелёного — проблема не в стеке, а в scope.