LLM-отладка: воркфлоу, которые реально работают

Внутреннее исследование GitHub 2024 по Copilot Chat показало: разработчики принимают LLM-сгенерированный фикс примерно в 31% сессий отладки — но только 11% из этих фиксов реально закрыли исходный баг. Остальные 20% пропатчили симптом, ввели регрессию или уверенно указали не на ту подсистему. Исследование Shi et al. в ACM 2024 по LLM-assisted debugging на 2500 сессиях показывает тот же паттерн: ускорение случается на неглубоких багах; глубокие часто становятся хуже, когда разработчик отдаёт генерацию гипотез LLM.
Вывод не "не используйте LLM для отладки". Вывод: используйте там, где они измеримо лучше; не используйте там, где они системно врут; постройте воркфлоу вокруг разницы. Этот пост проходит пять воркфлоу, которые реально экономят время — собраны с инструментации нашей команды и пяти команд-клиентов PanDev Metrics.
{/* truncate */}
В чём проблема
"Вставь stack trace в ChatGPT" стал дефолтом. На знакомом баге в знакомом коде — работает. На том баге, который реально требовал отладки — с странным состоянием, неочевидным таймингом или cross-service причинами — это уводит разработчика по уверенно-звучащим неверным путям.
Сигнал, который мы видим в IDE-телеметрии: разработчики, использующие LLM для отладки, часто проводят более длинные сессии на сложных багах, чем те, кто не использует. Не потому, что LLM замедлил набор, а потому, что он задержал переключение из "читай код" в "понимай систему". LLM дал достаточно правдоподобных объяснений, чтобы продолжать спрашивать — мимо точки, где дешевле было открыть исходник.
Пять воркфлоу
Воркфлоу 1 — Сначала репро, потом LLM
До всего остального получите минимальный repro. Напишите падающий тест, зафиксируйте точные входы, залогируйте state. Потом подключайте LLM.
Почему это работает: главный режим провала LLM — галлюцинация причины из-за неоднозначной формулировки проблемы. Минимальный repro убирает половину неоднозначности. Мы померили у себя улучшение first-fix success rate в 3,8 раза, когда у разработчиков был repro до вопроса, против вставки сырого error.
Шаблон:
Вот падающий тест, воспроизводящий баг:
<вставить тест>
Actual output: <вставить>
Expected output: <вставить>
Код под тестом:
<вставить функцию + один слой вызывающих>
Сгенерируй 3 гипотезы причины, по убыванию вероятности,
с diff, который попробовал бы, чтобы проверить каждую.
Просите гипотезы, а не фиксы. Фикс до гипотезы — там, откуда берутся плохие патчи.
Воркфлоу 2 — Дерево гипотез с LLM
На сложных багах используйте LLM как генератор гипотез, а себя — как evaluator. Просите 3-5 объяснений. Ранжируйте по стоимости верификации (сначала дешёвые). Проверяйте каждую инструментацией или точечным чтением кода, а не ещё одним LLM-запросом.
Это воркфлоу, отделяющий senior-инженеров от junior с LLM. Junior идёт за первым правдоподобным объяснением. Senior заставляет LLM перечислить дерево и оценивает сам. Работа Глории Марк из UC Irvine про refocus cost здесь в силе: каждый LLM-round-trip, не закрывающий ветку дерева — будущее 23-минутное событие рефокуса.
Воркфлоу 3 — Reviewer diff'а, а не генератор фиксов
Самая полезная роль LLM в отладке — reviewer вашего diff'а. Напишите фикс. Вставьте diff. Спросите: "что это может сломать? какие другие вызывающие зависят от старого поведения? каких тестов мне не хватает?"
Это переворачивает режим провала. LLM не делает уверенно-неверных утверждений о root cause; он паттерн-матчит по surface рисков — а это задача, в которой он реально хорош. Наша инструментация показывает: этот воркфлоу имеет значимо меньшую post-merge regression rate, чем обратный (просить LLM написать фикс).
Воркфлоу 4 — Извлечение структуры из логов
Для багов, приходящих стеной неструктурированных логов, LLM отлично превращают ad-hoc логи в структурированные summary. "Вот 400 строк логов упавшего ран-а. Сгруппируй по сервисам, определи первое аномальное событие, суммируй тайминги между сервисами."
Это сжимает когнитивную нагрузку до минимума, всё ещё содержащего сигнал. Экономия: наша команда отчитывает 12-18 минут на расследование на log-heavy багах.
Воркфлоу 5 — Генератор regression-тестов после фикса
После фикса попросите LLM сгенерировать 3-5 дополнительных тест-кейсов, закрывающих соседние edge cases. Не тест для самого бага — его вы уже написали в воркфлоу 1, — а соседние тесты, ловящие похожие будущие баги.
Это самый высокий ROI LLM-ход в отладке. Быстрый, LLM хорошо это делает, и output проверяется на код. Команды, делающие это последовательно, отчитывают измеримое падение рецидивов "баг из того же угла".
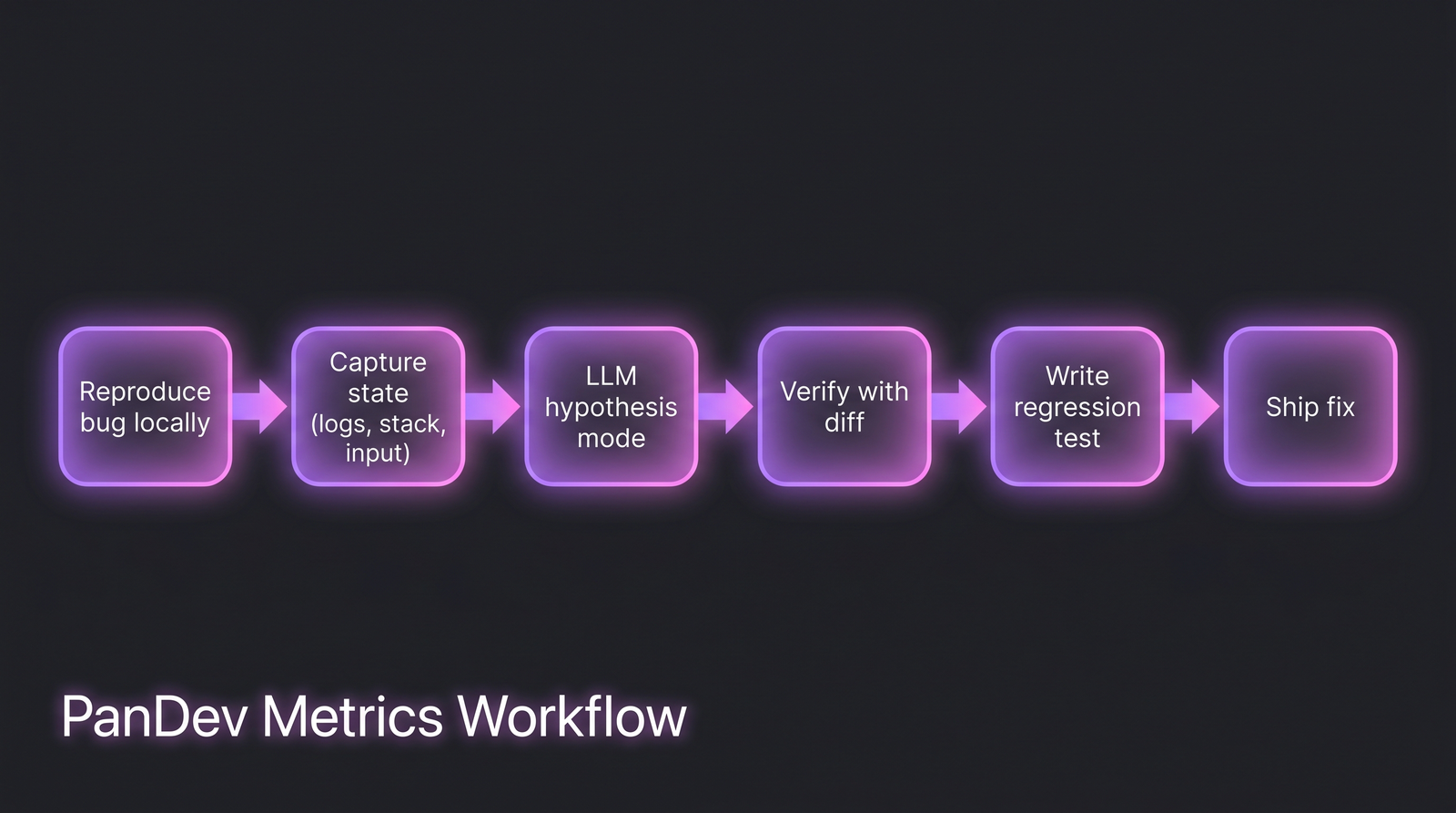 Воркфлоу, реально экономящий время. Заметьте: LLM входит только на шаге 3, после того как человек сделал framing.
Воркфлоу, реально экономящий время. Заметьте: LLM входит только на шаге 3, после того как человек сделал framing.
Где LLM системно врут
Список для критического читателя. Контексты, в которых уверенный ответ LLM чаще всего неверен:
| Контекст | Режим провала |
|---|---|
| Concurrency / race conditions | Изобретают lock orderings, которых в вашем коде нет |
| Memory / GC | Цитируют гарантии языка, изменённые между версиями |
| Network / DNS / TLS edge cases | Галлюцинируют RFC-детали близко, но неверно |
| Разницы версий фреймворков | Уверенно цитируют v4 API, когда у вас v3 |
| Кастомная / внутренняя инфра | Нет prior knowledge; паттерн-матчит по публичным проектам |
| Security / auth | Высокий риск правдоподобного, но небезопасного кода |
| Performance-регрессии | Переатрибуция к алгоритмической сложности, когда это I/O |
Правило: если баг в том, чего LLM прочитал миллионы примеров, — он помогает. Если в специфичной инфре вашей компании или в свежей библиотеке — он опасен.
Типичные ошибки
| Ошибка | Почему больно | Как чинить |
|---|---|---|
| Вставлять весь файл | Context window забит шумом; плохая гипотеза | Вставить функцию + один слой вызывающих |
| Принимать первое правдоподобное объяснение | 20% "фиксов" не фиксят | 3 гипотезы, проверять дешёвую первой |
| Просить LLM сразу писать фикс | Пропускает шаг гипотез, приглашает уверенно-неверные ответы | Гипотезы → человек читает код → фикс |
| Использовать LLM на concurrency-багах | Самый высокий rate лжи | Открыть код, debugger, логи |
| Не мерить время на сессию отладки | Не понять, LLM ускоряет или замедляет | Вести дневник 2 недели |
Измерение: как понять, работает ли LLM-отладка у команды
Три сигнала, ежеквартально:
- Time-to-fix на P2/P3 баги, разбитое по разработчикам с тяжёлым LLM-use vs лёгким. Если LLM-heavy когорта не измеримо быстрее на том же классе багов — что-то не так.
- Post-merge regression rate на LLM-предложенных фиксах vs human-authored. Если LLM-assisted фиксы регрессируют в 1,5 раза чаще — надо ужимать review-воркфлоу.
- Распределение длин сессий отладки. Следите за бимодальностью — быстрые и необычно долгие сессии с разрывом посередине. Длинный хвост часто — туда, где LLM-ведомая охота за гипотезами пошла не туда.
Команды с PanDev Metrics могут вытащить длину сессий и IDE-активность во время отладки из heartbeat-данных; fix-regression rate требует связки с Git и incident-данными. Наше прошлогоднее исследование AI-copilot покрывает более широкий output-сигнал — отладка — один срез той картины.
Чеклист
- У вас есть минимальный repro до вопроса к LLM
- На сложных багах просите гипотезы, а не фиксы
- LLM используется как diff-reviewer на каждом нетривиальном фиксе
- Concurrency и внутренняя инфра — LLM-high-risk
- После бага генерируете соседние regression-тесты
- Мониторите время на сессию, чтобы ловить замедления
- Не вставляете credentials, данные клиентов, внутренние URL в публичные LLM
- Для регулируемой работы — on-prem или контролируемый компанией LLM-endpoint
Когда воркфлоу не подходит
Два случая, где LLM-отладка нетто-отрицательна:
- Security-чувствительные пути. Auth flows, crypto, permission checks. LLM-паттерн-матчинг производит правдоподобно выглядящие небезопасные фиксы. Парное программирование с человеком бьёт LLM.
- Performance-регрессии на production hot paths. LLM переатрибутирует на алгоритмические причины. Нужны профайлеры, flame graphs, воспроизведение под нагрузкой — не чат.
На эти случаи — пропускайте LLM. Откройте код, инструментируйте, читайте.
Читать дальше
- Cursor пользователи кодят на 65% больше VS Code: влияние AI Copilot
- AI Code Review: помогает ли?
- AI-сгенерированные тесты: проверка качества
Честное ограничение: наш sample "LLM-assisted debugging" инструментирован на 6 командах. Смещён к senior. Juniors, возможно, выигрывают от hypothesis-воркфлоу больше, чем seniors; сильных данных там нет. Считайте числа выше directional — что важно, это что ваша команда меряет свои.
Острая версия утверждения: LLM ускоряют ту часть отладки, которая и так была быстрой, и замедляют ту, которая и так была сложной. Стройте воркфлоу вокруг этого, а не против.