Инженерия логистики: метрики для delivery-платформ

Инженерная команда delivery-платформы работает с нагрузкой принципиально другой формы, чем B2B SaaS. Мобильное приложение курьера пингует локацию каждые 3–5 секунд. Консоль диспетчера ждёт sub-200ms на назначение заказа. Route-optimization крутит комбинаторику ночью и обязан закончить до утренней смены. Отчёт McKinsey по last-mile 2024 оценил час простоя диспетчерской в $12,000–$35,000 для среднего регионального перевозчика.
Эта форма работы меняет то, какие инженерные метрики реально важны. DORA Four Keys всё ещё применимы, но картина delivery performance и team health смещается. Вот метрик-стек, который ложится на логистические команды — и места, где «скопируй SaaS-DORA-дашборд» вводит в заблуждение.
{/* truncate */}
Чем логистическая разработка отличается
У логистического софта три ограничения, которых в обычном SaaS нет:
- Лэйтенси-бюджет реального мира. Если приложение курьера замерло на 30 секунд — посылка уехала не туда. Программная задержка превращается в физическую ошибку с клиентскими, регуляторными, а иногда и safety-последствиями.
- Сезонные обрывы трафика. Black Friday, Chinese New Year, сезон дождей — некоторые платформы ловят 4–7× трафика за три дня. Ваш capacity plan — не «сколько обслуживаем в среднем», а «что мы переживём в худший день года».
- Регулируемые данные часов водителя. В США, ЕС и большей части Азии трекинг коммерческого водителя подпадает под трудовое и транспортное законодательство. Данные мобильного приложения — это доказательство. Изменения кода, трогающего GPS-телеметрию, проходят не только code review, но и compliance review.
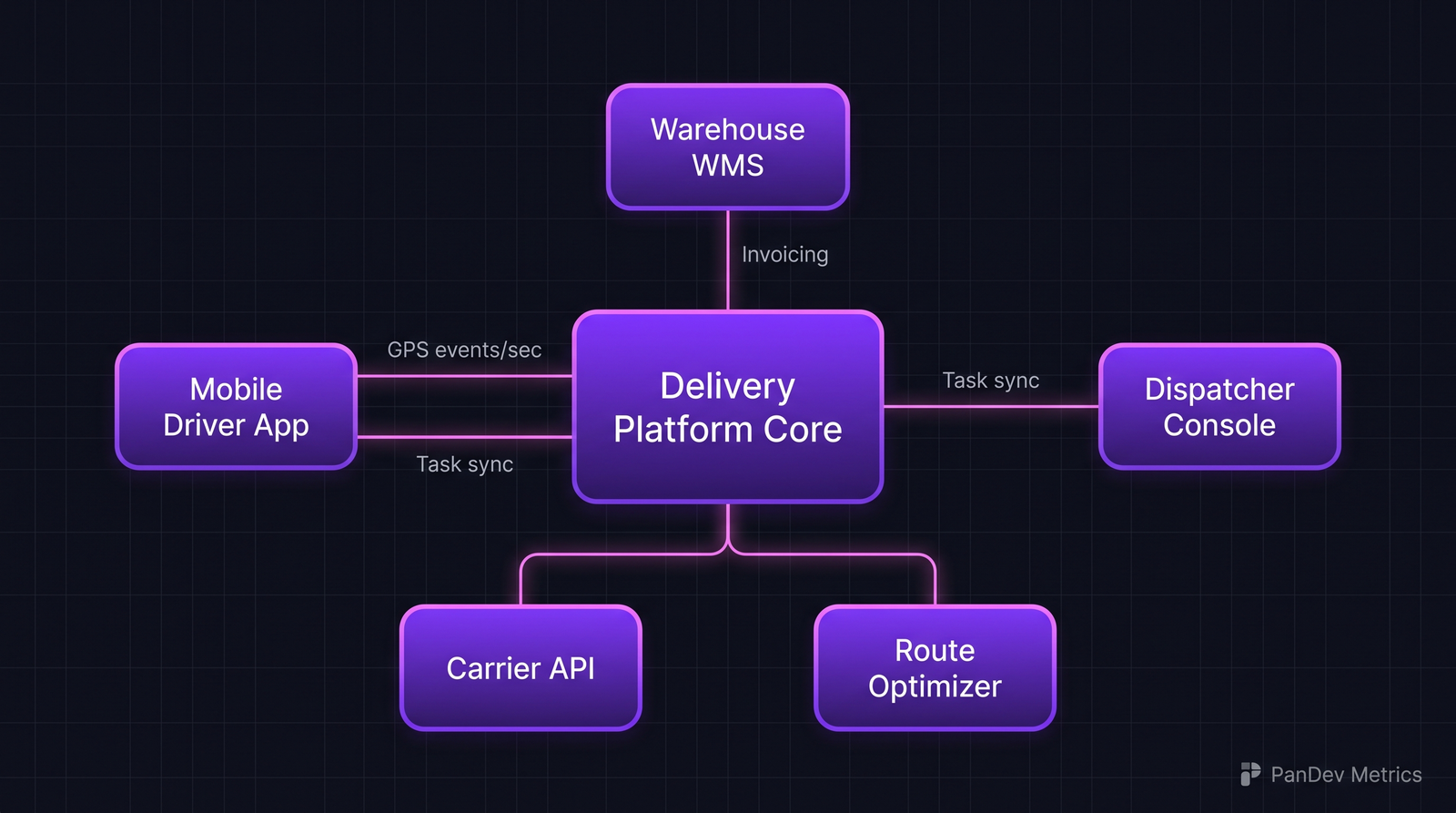 Типичная архитектура delivery-платформы. У пяти окружающих систем разные latency- и reliability-бюджеты — поэтому одного дашборда не хватит.
Типичная архитектура delivery-платформы. У пяти окружающих систем разные latency- и reliability-бюджеты — поэтому одного дашборда не хватит.
Какие метрики здесь действительно важны
1. Запас ёмкости на пике, а не uptime
Uptime 99.95% звучит хорошо. И скрывает, что в пятницу в 18:00 у вас 92% CPU и нет запаса даже на 10% скачка.
Трекайте peak-hour capacity headroom как отдельную метрику:
| Сервис | Целевой запас | Почему такое число |
|---|---|---|
| Ingest courier-трекинга | ≥40% | GPS-бёрсты в час-пик скачут в 5× во время пересменки |
| Order assignment | ≥25% | Цель sub-200ms, иначе очередь диспетчера пухнет |
| Ночной route-optimizer | Закончить к 04:30 местного | Смены водителей стартуют 05:00–06:00 |
| Потребительское приложение | ≥30% | Абсорбция Black Friday / flash-sale |
| Админка / аналитика | 0–10% ок | Не time-critical, может деградировать |
Инженерный блог Pinterest (2023) описал практику «capacity runway» — они трекают, сколько пиковых дней осталось до пробития 70% CPU. Для логистики та же идея: «мы в 18 пиковых днях от capacity-аварии».
2. p95 latency, а не среднее
Среднее — неправильный инструмент для логистики. Внутреннее исследование Amazon, которое Werner Vogels озвучил в 2022, отмечает: пользователь помнит 95-й перцентиль. Одно из двадцати назначений заказа в 2 секунды — достаточно, чтобы диспетчер начал жаловаться.
Трекать:
| Эндпоинт | p50 | p95 | p99 |
|---|---|---|---|
/orders/assign | 80ms | 180ms | 350ms |
/courier/heartbeat | 20ms | 60ms | 120ms |
/route/recalculate | 400ms | 1.2s | 2.5s |
/customer/track/{id} | 100ms | 250ms | 500ms |
p50 — обычная жизнь. p95 — то, что ощущают. p99 — где звенят пейджеры.
3. Change failure rate по сегментам поверхности
DORA'шную change failure rate обычно показывают одним числом. Для логистики это прячет критичный нюанс: провал деплоя на клиентский tracking — это стыдно; провал деплоя на диспетчерскую консоль — это остановка операций.
Разбивайте:
| Поверхность | Допустимая failure rate | Ожидания по откату |
|---|---|---|
| Диспетчерская консоль | < 5% | До 2 минут |
| Мобильное приложение курьера | < 8% | 24 часа (App Store цикл — обязательны feature flags) |
| Клиентская tracking-страница | < 15% | До 5 минут |
| Внутренняя админка | < 20% | На следующий день ок |
Единая org-wide «change failure rate 12%» скрывает, что у диспетчера 3% (отлично), а у клиентского экрана 22% (аварийно).
4. Каденция мобильных релизов vs десктоп
Мобильный релиз нельзя откатить. iOS-релиз со сломанным запросом GPS-прав висит живым минимум 18–36 часов. Это диктует другую каденцию:
- Десктоп / веб: несколько деплоев в день — нормально
- Мобилка: недельный или двухнедельный ритм, через beta-rollout, всегда за feature flags
Здоровая логистическая команда считает мобилку как отдельную DORA-единицу со своей deployment frequency, lead time и change failure rate. Склеивание в org-wide число — самая частая ошибка интерпретации, которую мы видим.
5. Интенсивность on-call (только driver-impacting)
Не все алерты равны. Дэшборд-компонент ночью в 3 — больно. «Курьеры не могут залогиниться» в 3 ночи — авария уровня платформы.
Трекать:
- Driver-impacting инцидентов в неделю — цель < 2
- Среднее число алертов на смену on-call — цель < 5
- After-hours деплоев в курьер-сервисы — стремиться к нулю
Последнее — контринтуитивно. Ортодоксия DevOps говорит «деплойте часто, даже ночью». Для логистики ночные деплои в курьер-системы несут асимметричный риск: если водитель застрял — ответить некому.
Как compliance и масштаб меняют измерение
GPS-данные водителя — персональные данные по GDPR, UK DPA и многим региональным законам. Следствия:
- Access-логи GPS-телеметрии сами являются audit-артефактами. Инженер, который запросил маршрут водителя за прошлую неделю, должен быть записан.
- Политики хранения данных локации курьера зависят от юрисдикции (6 месяцев в ЕС, до 7 лет в некоторых штатах США для соответствия повесткам).
- Change review всего, что трогает
locations/gps_pointsтаблицы, должен включать compliance-ревьюера. Это замедляет ваш lead time — и это замедление правильное, а не метрика для оптимизации.
Именно поэтому копирование SaaS DORA-дашборда вводит в заблуждение: оно поощряет неправильное поведение в контексте регулируемых данных. Средний lead time по GPS-меняющим изменениям будет больше, чем по UI-изменениям, и это фича.
Типичная команда delivery-платформы
Как обычно выглядит инженерный отдел ~40 человек:
| Команда | Размер | Что владеет |
|---|---|---|
| Driver / мобилка | 6–8 | iOS, Android, мобильный бэкенд |
| Диспетчерская консоль | 4–6 | Web console, алгоритм назначения |
| Customer experience | 5–7 | Tracking, нотификации, клиентское приложение |
| Route & optimization | 3–5 | VRP solver, гео-индексация, ETA-сервис |
| Платформа / данные | 6–9 | Ingestion, БД, BI-пайплайны |
| SRE / DevOps | 3–5 | Infra, CI/CD, incident response |
| Интеграции | 3–5 | Carrier API, WMS, compliance-выгрузки |
Ломаются обычно Route & Optimization (маленькая, узкоспециализированная, высокая on-call нагрузка) и Интеграции (невидимы, пока carrier API не изменится за ночь и не сломает Black Friday).
Где тут PanDev Metrics
PanDev Metrics собирает IDE-heartbeat и Git-данные по нескольким репозиториям, что ложится на multi-service реальность логистического стека. Две зоны пользы:
- Multi-repo focus tracking — инженер route-optimizer часто трогает VRP-solver, ETA-сервис и диспетчерскую консоль. IDE-телеметрия, отмеченная проектным контекстом, отвечает на «насколько реально фрагментирована эта роль?» — чего self-report-опросники сказать не могут.
- Сигналы пиково-сезонного выгорания — паттерны ночного и выходного кода, кластеризующиеся вокруг Black Friday или региональных пиков, проявляются как те самые 5 сигналов, которые мы описали в гайде по выявлению burnout. У логистических команд это видно раньше и жёстче среднего.
Честная оговорка: мы не меряем пользовательский опыт курьера. Наши данные — про инженеров, строящих платформу, а не про курьеров, которые ею пользуются. Uptime и latency SLO всё ещё идут из вашего APM-стека (Datadog, New Relic, Grafana).