Cost attribution в микросервисах: кто платит за auth?

Платформенная команда из 6 инженеров стоит $156K в квартал. Они держат auth, observability, внутренний API gateway, общий кэш и деплой-пайплайн. Восемь продуктовых команд используют эти сервисы каждый день. Спросите CFO, кто за это платит — ответ «центральный R&D». Спросите тимлида платформы, кто это потребляет — ответ «все одинаково». Оба не правы, и зазор между ними — это место, где инжиниринг-финансы каждый год теряют шестизначные суммы на искажённых решениях.
Adrian Cockcroft изначально сформулировал этот аргумент, когда Netflix дробился на микросервисы: общая инфраструктура имеет unit cost, и unit cost должен следовать за запросом. CNCF FinOps Working Group в отчёте 2024 State of FinOps for Engineering нашли, что меньше 24% микросервисных организаций аллоцируют время платформенной команды обратно на команды-потребителей. Остальные 76% считают платформу overhead — то есть команда, потребляющая 41% запросов, получает тот же счёт, что и команда с 1%.
{/* truncate */}
Контр-интуитивный тезис
Большинство дискуссий по инжиниринг-финансам останавливаются на «платформа — это overhead». Именно из-за этого платформенные команды хронически недоукомплектованы, а продуктовые — хронически беспечны в том, что они от них требуют. Реальный chargeback говорит: каждая команда-потребитель платит за то время платформы, которое она реально съела. Запустите shadow chargeback на полгода, потом сделайте его реальным — и разговор по бюджету изменится за один финансовый год.
Сложно не философию принять, а выбрать одну из трёх моделей с разной точностью и операционной стоимостью. Мы катали все три у клиентов. Вот что узнали.
Три модели chargeback
Atlassian в State of DevOps 2024 выяснили, что средняя продуктовая команда в микросервисах зависит от 5.3 платформенных сервисов и кидает в платформу 17 тикетов в квартал. Вот эту нагрузку и нужно аллоцировать. Три варианта:
| Модель | Что измеряем | Точность | Операционная стоимость |
|---|---|---|---|
| Flat-tax | Стоимость платформы ÷ число команд-потребителей | Низкая | Никакой |
| Proportional | Тикеты платформы, привязанные к команде-потребителю | Высокая | Средняя (дисциплина тегирования) |
| Consumption | API-вызовы / запросы / события от команды-потребителя | Высочайшая | Высокая (телеметрия) |
Flat-tax — это то, к чему по умолчанию приходят CFO, когда их вынуждают распределять. И это почти специально неверная модель. Proportional и consumption обе работают, но требуют от организации разного.
Flat-tax: просто, часто несправедливо
Берём квартальную стоимость платформы ($156K), делим на 8 команд, шлём каждой счёт на $19.5K. Готово за пять минут.
Проблема: команда A создала 35% тикетов и сделала 41% API-вызовов. Команда H — два тикета и 1% вызовов. Обе платят $19.5K. Команда H субсидирует команду A примерно на $15K в квартал. У команды A нет ни одного стимула оптимизировать использование платформы — стоимость фиксирована независимо от поведения.
Flat-tax уместна ровно в одной ситуации: когда разброс потребления между командами действительно мал (все используют платформу примерно одинаково) и когда chargeback нужен ради бухгалтерской чистоты, а не ради поведенческого сигнала. На практике это редкость.
Proportional: по числу Jira-тикетов
Считаем тикеты платформенной команды, привязанные к каждой команде-потребителю за период. Аллоцируем стоимость пропорционально. Команда A драйвила 35% тикетов — команда A платит 35% от $156K = $54.6K.
Это работает, потому что время платформенных инженеров — связывающий ресурс. Будь это однострочный конфиг или двухнедельная миграция, единица потребления — инженеро-час. Тикеты приближают часы с точностью ±20%, если команда работает в более-менее однородных по размеру задачах.
Операционная стоимость реальна. Каждый тикет платформы должен иметь поле consumer_team или label. Без этого модель деградирует до flat-tax под другим именем. Механику issue-level атрибуции мы разбирали в Cost per Jira Ticket: Trace Spend to a Single Issue — proportional chargeback это просто кросс-командная свёртка той же примитивной операции.
Consumption: по API-вызовам или запросам
Инструментируем платформенный сервис. Считаем запросы по командам-потребителям. Аллоцируем стоимость пропорционально потреблению. Если auth-сервис обрабатывает 10M запросов в квартал, а команда A сделала 4.1M — её доля 41% × $156K = $63.9K.
Это самая точная модель, потому что она измеряет ровно то, что сервис делает. И самая дорогая в настройке. Нужно консистентное тегирование команды на API-границе (X-Team-ID header, service-mesh label, OAuth client claim — выберите одно и форсайте). Без этого вы не отличите 10K запросов от order-сервиса команды A от такого же количества от recommendation-сервиса команды H.
Consumption-chargeback также вытаскивает наружу проблемы, которые flat-tax не видит: команда со сломанной retry-логикой, дубасящая платформу в 5 раз больше, чем нужно, платит в 5 раз больше. Замечает, чинит баг, нагрузка падает. Сигнал ровно тот, что нужен.
Разбор: $156K платформы на 8 продуктовых команд
Реальная команда платформы — 6 инженеров, $52K loaded cost в месяц, $156K в квартал. Восемь продуктовых команд, обозначим A–H по убыванию зависимости от платформы. Три месяца данных. Вот что каждая команда должна по каждой модели.
| Команда | Тикеты | Доля API | Flat-tax | Proportional | Consumption |
|---|---|---|---|---|---|
| A | 35% | 41% | $19.5K | $54.6K | $63.9K |
| B | 22% | 19% | $19.5K | $34.3K | $29.6K |
| C | 18% | 14% | $19.5K | $28.1K | $21.8K |
| D | 9% | 11% | $19.5K | $14.0K | $17.2K |
| E | 7% | 7% | $19.5K | $10.9K | $10.9K |
| F | 5% | 4% | $19.5K | $7.8K | $6.2K |
| G | 3% | 3% | $19.5K | $4.7K | $4.7K |
| H | 1% | 1% | $19.5K | $1.6K | $1.6K |
| Итого | 100% | 100% | $156K | $156K | $156K |
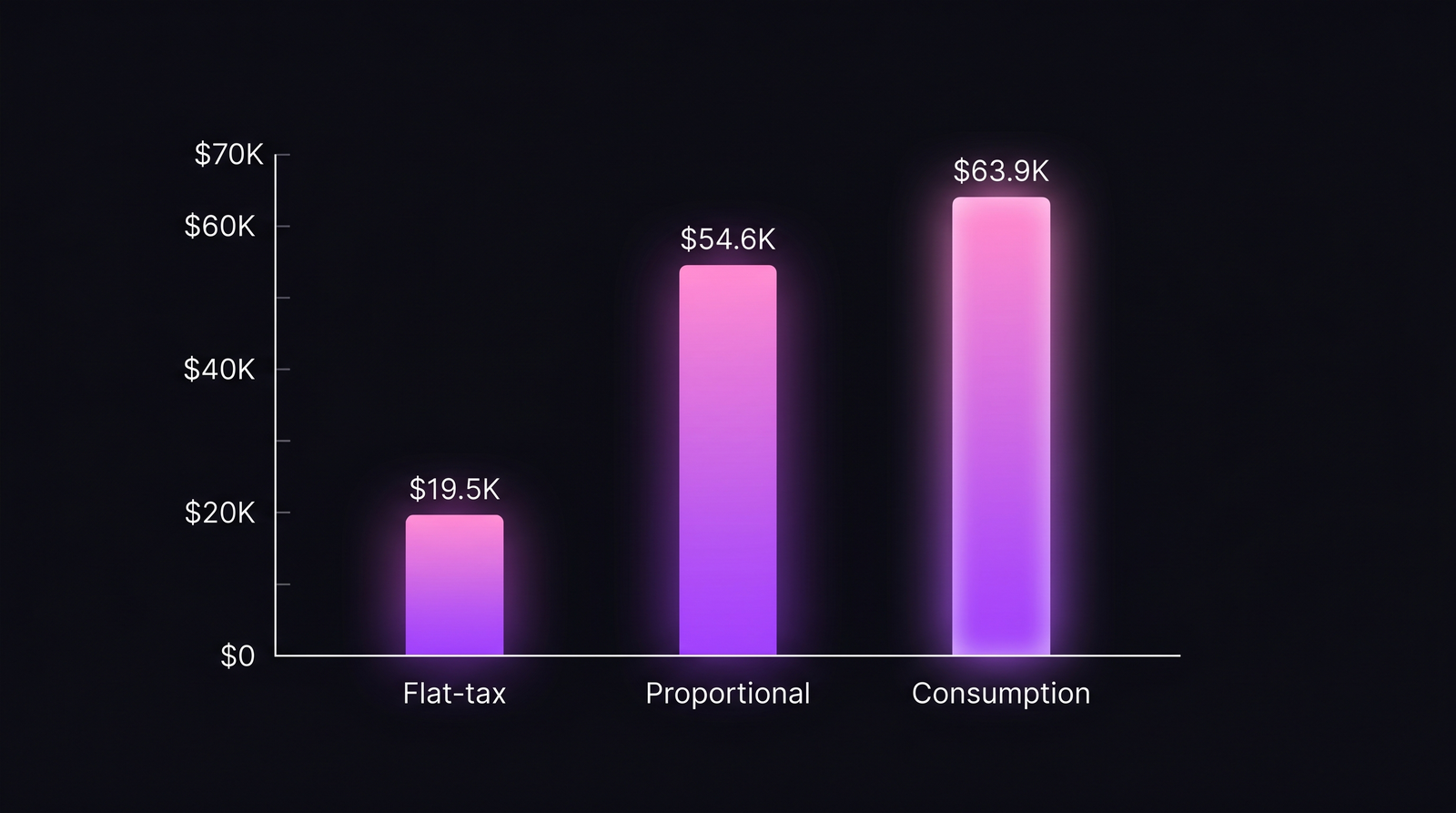 Один и тот же квартал, та же платформа, та же команда A. Flat-tax счёт примерно в три раза меньше того, что выставила бы consumption-модель.
Один и тот же квартал, та же платформа, та же команда A. Flat-tax счёт примерно в три раза меньше того, что выставила бы consumption-модель.
Три наблюдения, которые таблица заставляет сделать.
Команда A сильно зависит от платформы. По proportional платит $54.6K, по consumption — $63.9K. Их доля API (41%) обгоняет долю тикетов (35%) — обычно это значит, что они автоматизировали использование платформы: меньше тикетов на единицу извлечённой ценности. По flat-tax платят $19.5K и выглядят как все. Тимлид платформы понятия не имеет, что A — самый тяжёлый клиент.
Команда H платит в 12 раз больше своей реальной доли. По flat-tax — $19.5K за 1% потребления. Это $17.9K трансфер от H к среднему. Если H — это маленький продуктовый направление, пытающееся доказать unit-экономику, оно решит, что у них сломанная база затрат. База не сломана. Аллокация сломана.
Proportional и consumption не всегда совпадают. Команда B драйвила 22% тикетов, но только 19% вызовов. Их тикеты тяжелее среднего — меньше запросов, больше штучной работы. Proportional выставляет им больше ($34.3K vs $29.6K). Обе цифры защитимы. Выбирайте модель под то поведение, которое хотите видеть: хотите, чтобы меньше просили — proportional; хотите, чтобы меньше дёргали — consumption.
Как PanDev Metrics реализует proportional и consumption
Большинство команд тормозят на proportional chargeback из-за неровной Jira-гигиены. PanDev считает per-ticket стоимость через mv_activity_total_user_issue_daily — материализованное представление, агрегирующее секунды IDE-активности по пользователю, Jira issue и дню. Свёртка по полю consumer_team тикета — и у вас есть proportional cost без ручной арифметики со ставками.
Кросс-командная аллокация работает через членство в gitProject в user_departments. Когда инженер платформы коммитит в репозиторий, принадлежащий департаменту команды A, время автоматически отправляется в chargeback-бакет команды A. Teams Widget на /dashboard/finances показывает это как radar chart — один взгляд на то, какая команда-потребитель сколько платформенной работы спровоцировала за период.
Для consumption-chargeback платформенный сервис всё равно придётся инструментировать самим (PanDev не собирает телеметрию API-gateway). Что PanDev даёт — это математика cost-per-engineer-hour, которая превращает доли потребления в реальные доллары; конверсия «команда A сделала 41% запросов» → «команда A должна $63.9K» консистентна по всем командам с одной loaded rate. Подложку по бюджетной математике мы разбирали в Bottom-up Engineering Budget: From Rate to Annual P&L.
Когда chargeback работает, а когда это театр
Chargeback работает только если у команды-потребителя есть бюджетная власть над тем, что она тратит. Если платформа финансируется централизованно и продуктовая команда не может отказаться — счёт это просто отчёт. Интересный, но не инструмент решения. Команда читает цифру, рычага у неё нет, а команда платформы тоже не может конвертировать данные в headcount.
Лекарство — shadow chargeback. Гоните модель полгода. Шлите командам phantom-счета. Смотрите, что происходит. Большинство потребителей корректируется добровольно ещё до того, как chargeback станет реальным — никто не хочет быть командой, которая драйвит 41% стоимости платформы, когда дашборд видит VP. Поведенческий сигнал работает, даже когда финансовый трансфер не работает.
Делайте его реальным после того, как организация приняла цифры как справедливые. Реальный chargeback означает, что у команд-потребителей есть бюджетная строка на платформу в их P&L и они могут выбрать тратить больше (просить больше платформенной работы) или меньше (строить альтернативу in-house). Это и есть тот разговор, который инжиниринг-финансы должны включать.
Чего данные не скажут
Цифра chargeback говорит, кто заплатил. Она не говорит, правильно ли укомплектована платформенная команда. Тяжёлый потребитель (команда A) может быть знаком, что платформа делает ровно то, что должна — даёт leverage. А может быть знаком, что платформа построила не ту абстракцию, и команда A вынуждена обходить её через дорогие workaround-ы. Цифра одна, диагнозы противоположные.
Наша IDE-телеметрия показывает инженерное время. Она не показывает, родило ли это время правильные результаты. Мы честно про лимит: chargeback подсвечивает стоимость, не ценность. Парьте chargeback-вид с удовлетворённостью команд-потребителей и трендом инцидентов платформы перед выводами о её здоровье.
Второй лимит: общие сервисы, которые реально являются общественным благом (security review, сбор SOC2-доказательств, compliance), должны быть flat-tax. Аллоцировать security review по числу тикетов — создавать порочный стимул проскочить ревью. Часть выхлопа платформы недискреционна, и chargeback здесь — не тот инструмент. Прежде чем выбирать модель, поделите платформенные сервисы на discretionary vs mandatory.
Что отгрузить в следующем квартале
Запустите proportional shadow первым. Это самая дешёвая модель для старта — Jira-данные уже есть, нужно только добавить label consumer_team к платформенным тикетам. Три месяца phantom-счетов скажут, реален ли разброс потребления (обычно да) и являются ли самые тяжёлые потребители теми, кого вы ожидали (часто нет). Когда цифры перестают удивлять — включайте финансовый трансфер и смотрите, как меняется поведение. Atlassian-исследование показывает, что объём тикетов в платформу падает на 12-18% в первые два квартала после реального chargeback — не потому, что спрос исчез, а потому что потребители расставили приоритеты на том, что им реально нужно.
Это падение и есть весь смысл упражнения. Стоимость платформы не изменилась. Её leverage — изменился.