MTTR это: метрика восстановления в DORA с формулой и бенчмарками

Два production-инцидента, одна и та же причина — плохой конфиг положил платёжный сервис. Команда A восстановила сервис за 2 часа 14 минут. Команда B — за 6 минут. У команды B MTTR ниже не потому что инженеры умнее. У них была одна команда rollback, отрепетированная раз в месяц, runbook закреплён в on-call канале, и доступ на запись в прод выдан дежурному заранее. Разрыв — 134 минуты против 6 — это именно то, что измеряет MTTR. И это же отделяет elite-кластер из DORA 2023 State of DevOps Report от всех остальных.
{/* truncate */}
MTTR это одно число для тяжёлого вопроса
MTTR (Mean Time to Recovery) — среднее время, за которое команда восстанавливает сервис после production-инцидента. В рамках DORA метрику также называют Time to Restore Service, и она стоит рядом с Deployment Frequency, Lead Time for Changes и Change Failure Rate как одна из четырёх метрик доставки.
Тяжёлый вопрос, на который отвечает MTTR: когда (не «если», а именно «когда») прод падает, как быстро команда возвращает пользователей к нормальной работе? Не как быстро нашли root cause. Не как быстро выкатили постоянный фикс. Как быстро пользователям стало нормально. Rollback, который восстановил сервис за 4 минуты, даёт MTTR = 4 минуты — даже если разбор причины продолжается ещё два дня после этого. Книга Google Site Reliability Engineering разделяет это явно: цель incident response — восстановить сервис, а root-cause investigation идёт параллельно или после.
Формула MTTR
MTTR = sum(длительность_восстановления_по_инцидентам) / число_инцидентов
Длительность восстановления по одному инциденту считается так:
длительность_восстановления = время_восстановления_сервиса − время_начала_инцидента
Конкретный пример, март 2026, одна команда:
| Инцидент | Начался | Восстановлен | Длительность |
|---|---|---|---|
| INC-412 | 03:14 | 03:21 | 7 мин |
| INC-418 | 11:02 | 11:45 | 43 мин |
| INC-421 | 16:30 | 16:36 | 6 мин |
| INC-427 | 22:11 | 23:54 | 1ч 43м |
MTTR за месяц = (7 + 43 + 6 + 103) / 4 = 39,75 минут.
Нюанс, который большинство команд пропускают: среднее арифметическое чувствительно к выбросам. Один 14-часовой инцидент перекрывает десять 5-минутных восстановлений. SRE-команды зрелого уровня вместе со средним считают p50 (медиану) и p95 — медиана 12 минут с p95 в 4 часа рассказывают про эксплуатацию совсем другую историю, чем то же среднее.
MTTR бенчмарки 2026 (DORA)
Отчёт DORA 2023 разделил команды на четыре уровня. Обновление 2024 года сократило разрыв elite-vs-rest по некоторым метрикам, но пороги по MTTR остались по сути теми же:
| Уровень | MTTR | Типичный паттерн организации |
|---|---|---|
| Elite | Менее 1 часа | Rollback автоматизирован, runbook'и отрепетированы, у on-call есть прод write-доступ |
| High | Менее 1 дня | Документированный rollback, on-call пейджится за 5 мин, blameless postmortem'ы |
| Medium | От 1 дня до 1 недели | Ручной rollback, культура «сначала root cause», нужны аппрувы |
| Low | Больше 1 недели | Runbook'ов нет, фиксят только корневую причину, у дежурного нет полномочий |
Границы категорий намеренно широкие — кросс-индустриальное сравнение на более тонкой шкале ломается. Финтех с регулятором, который накладывает change window, ведёт себя совсем не так, как consumer SaaS, но обе компании могут быть «elite» по определению DORA.
Что считать инцидентом
Эту часть большинство разговоров про MTTR пропускает — и именно она делает число либо доверенным, либо шумом. Инцидент для целей MTTR это production-impact failure, зафиксированный алертом или жалобой пользователя. Два критерия, оба обязательны:
- Прод-импакт — пользователи (внутренние или внешние) видят деградацию. Упавший staging deploy — это не инцидент.
- Detection — есть таймстемп «мы заметили» или «алерт сработал». Баг, который клиент нашёл в письме через полгода, в MTTR не попадает — это дефект, не инцидент.
Большинство зрелых команд используют severity tier'ы и в основной MTTR включают только SEV-1 и SEV-2:
| Severity | Определение | Считается в DORA MTTR? |
|---|---|---|
| SEV-1 | Полный outage, серьёзный revenue/safety impact | Да |
| SEV-2 | Значительная деградация, частичный outage | Да |
| SEV-3 | Незначительная деградация, есть workaround | Опционально, обычно трекается отдельно |
| SEV-4 | Косметика / не задевает пользователей | Нет |
Подмешивание SEV-3 шума в то самое число, которое должно драйвить инвестиции в incident response, — одна из самых частых ошибок отчётности. Команды обычно исправляют её во втором квартале трекинга DORA.
Как снижать MTTR
Контр-интуитивный тезис этой статьи: MTTR в 5 минут почти всегда достигается скучной инфраструктурой — быстрым rollback, отрепетированными runbook'ами, заранее выданными полномочиями — а не сложными AI-инструментами для root-cause analysis. Умные тулы помогают, когда нужно понять, почему система сломалась. Они редко помогают, когда нужно сделать так, чтобы она перестала ломаться прямо сейчас.
Пять инвестиций, которые двигают MTTR сильнее, чем покупка любого тулинга:
- Rollback одной командой до последнего зелёного деплоя. Если путь rollback требует Slack-аппрувов или code freeze — твой пол по MTTR равен задержке аппрувов.
- Runbook'и для топ-5 failure mode. Не «всеобъемлющие» — пять самых вероятных инцидентов по статистике последних 12 месяцев. Прикреплены в on-call канале. Репетируются раз в квартал.
- On-call authority выдан заранее. У дежурного есть прод write-доступ до инцидента, а не после танца с правами в 3 часа ночи.
- Blameless postmortem с полем «обновление runbook». Каждый postmortem заканчивается минимум одной правкой runbook. Нет правки — команда ничему не научилась.
- Observability для скучных вопросов. «Было ли что-то задеплоено в последние 30 минут? Был ли всплеск трафика на этом эндпоинте? Уперлась ли БД в connection limit?» Эти три ответа решают 60-70% инцидентов по нашему опыту.
Чего в этом списке нет: ML-аномали-детекшн, AIOps-платформы, автоматический root-cause analysis. Они полезны на масштабе, но это не тот рычаг, который двигает команду с 4-часовым MTTR на 40 минут. Автоматизация rollback — двигает.
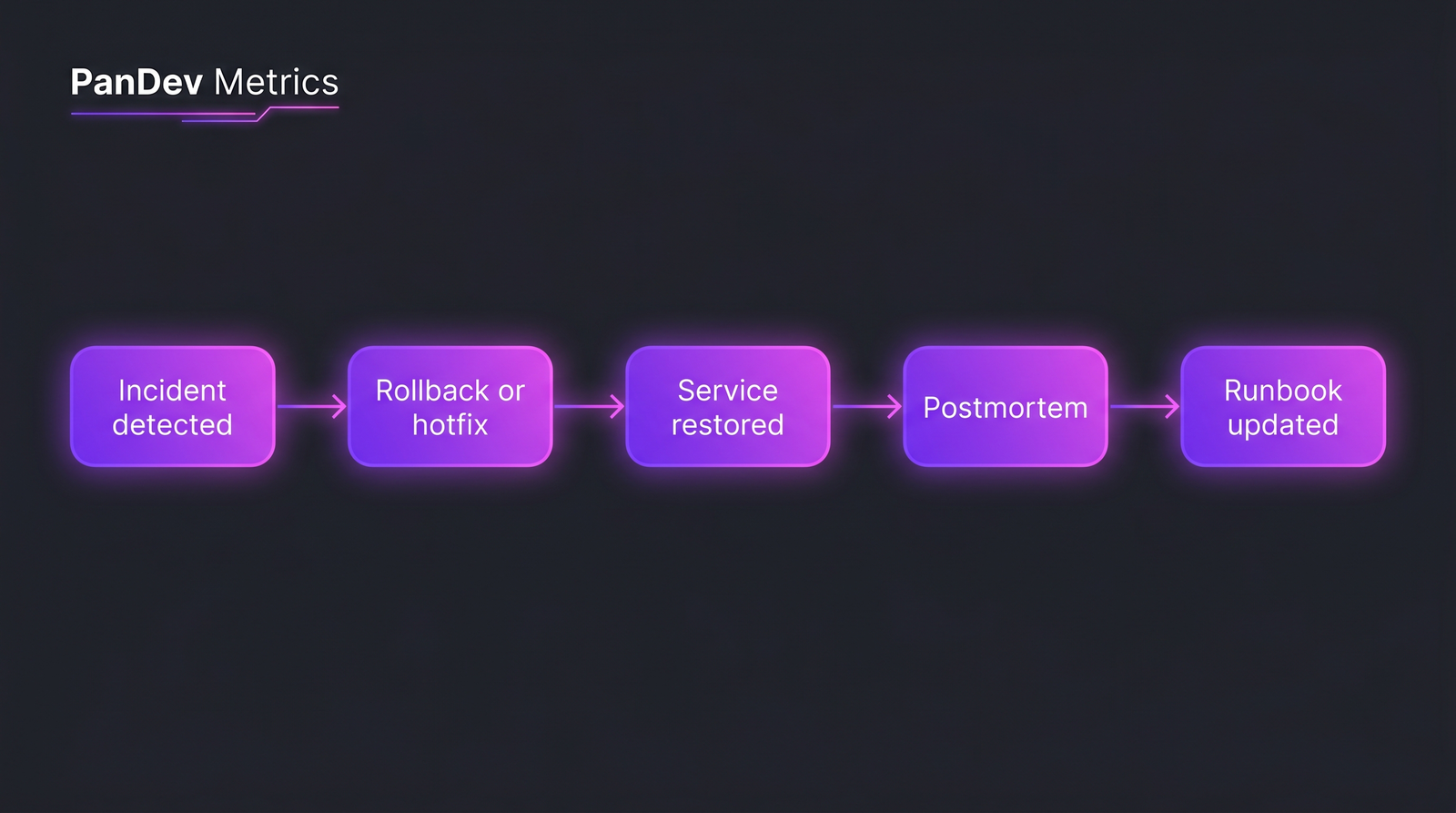 Пять стадий быстрого восстановления — большинство команд оптимизируют стадию 4 (postmortem) и игнорируют стадию 2 (rollback).
Пять стадий быстрого восстановления — большинство команд оптимизируют стадию 4 (postmortem) и игнорируют стадию 2 (rollback).
MTTR vs MTBF vs MTTD — смежные метрики
Эти три постоянно путают. Они измеряют разное:
| Метрика | Расшифровка | Что измеряет |
|---|---|---|
| MTTR | Mean Time to Recovery | Detection → сервис восстановлен |
| MTBF | Mean Time Between Failures | Время между двумя последовательными инцидентами |
| MTTD | Mean Time to Detect | Инцидент начался → команда заметила |
MTBF — это метрика предотвращения. MTTD — метрика алертинга. MTTR — метрика реакции. Вместе с Change Failure Rate они описывают полный жизненный цикл инцидента. Команда с отличным MTBF (инциденты редки) и плохим MTTR (каждый тянется часами) хрупкая в том смысле, который заголовочная цифра надёжности скрывает.
Честное ограничение метрики: MTTR в одиночку измеряет восстановление, а не предотвращение. Команда может иметь elite MTTR при 20% Change Failure Rate — они просто очень хорошо научились убирать за собой. Поэтому DORA трекает четыре метрики как систему. Если смотреть только на MTTR — оптимизируешь скорость уборки и пропускаешь то, что сам же и устраиваешь слишком много пожаров.
Как PanDev Metrics считает это
Если инциденты живут в Jira (или PagerDuty, или ClickUp), PanDev Metrics подтягивает их через интеграцию с трекером и считает MTTR по команде, по сервису, по severity автоматически. Модуль MTTR читает таймстемпы incident_start и service_restored из инцидент-тикета и сверяет их с deployment events из интеграции CI/CD, так что инцидент, закрытый через rollback, показывается с привязанным rollback-деплоем. Тот же pipeline кормит дашборды Change Failure Rate и Deployment Frequency, поэтому четыре DORA-метрики видны на одном экране, а не в четырёх отдельных экспортах.
Это и есть практический ответ на «как трекать MTTR без сборки своего pipeline» — она живёт рядом с остальной DORA в delivery-дашборде.
FAQ
MTTR это что? Mean Time to Recovery (иногда Mean Time to Restore Service в формулировке DORA). Среднее время от detection инцидента до восстановления сервиса.
Какой нормальный MTTR? По DORA 2023: меньше 1 часа — elite, меньше 1 дня — high, от 1 дня до 1 недели — medium, больше недели — low. Большинство команд в первый год трекинга попадают в medium и переходят в high после целенаправленной работы над rollback.
MTTR это в DORA? Да. MTTR (или «Time to Restore Service») — одна из четырёх метрик DORA: Deployment Frequency, Lead Time for Changes, Change Failure Rate и MTTR. Их специально трекают вместе — улучшение одной метрики в отрыве обычно ломает другую.
Как считать MTTR?
MTTR = сумма(длительность восстановления по инцидентам) / число инцидентов. Длительность восстановления — wall-clock время от момента detection (сработал алерт или пожаловался клиент) до момента, когда сервис полностью восстановлен, независимо от того, найден ли root cause. Большинство команд также трекают p50 и p95 отдельно — среднее чувствительно к выбросам.
MTTR метрика и SLA — связь? SLA обычно обещает availability в течение периода («99,9% uptime в месяц»). MTTR — один из входов в эту цифру: если MTTR высокий, downtime съедает error budget быстрее. У команды с 99,9% месячной availability есть всего около 43 минут разрешённого простоя в месяц — это одно elite-восстановление от одного серьёзного инцидента. Трекать их надо вместе: MTTR — операционная метрика, SLA — контрактная.