Observability Stack: Datadog vs Grafana vs Honeycomb

SRE-лид в mid-size fintech сказал фразу, определяющую observability-решения 2026: «Datadog — это iPhone observability: дорого, отполировано, и я жалею, что у меня есть выбор». На рынке сейчас три credible позиции: Datadog как интегрированный дефолт, Grafana как open-source-first альтернатива, Honeycomb как wide-events-специалист. Каждый оптимизирован под разный failure mode, и выбор не того не вылезет в первый квартал — он вылезет через $2M годового счёта и команду, всё ещё не отвечающую на «почему latency скакал во вторник?».
Annual Survey CNCF 2024 зафиксировал: 86% cloud-native организаций используют OpenTelemetry в той или иной форме — звучит как стандартизация рынка. На практике OTel — пайплайн, не destination; каждый шоп, гоняющий его, всё равно выбирает один из этих трёх стэков (или Splunk, New Relic, Dynatrace — их коснёмся кратко), чтобы реально хранить, запрашивать и визуализировать данные. Собственное исследование observability maturity от Honeycomb показывает: команды, переходящие на wide events, режут время расследования новых инцидентов на 40-60%, но только когда культура адаптируется — одним инструментом lift не даётся.
{/* truncate */}
Позиционирование
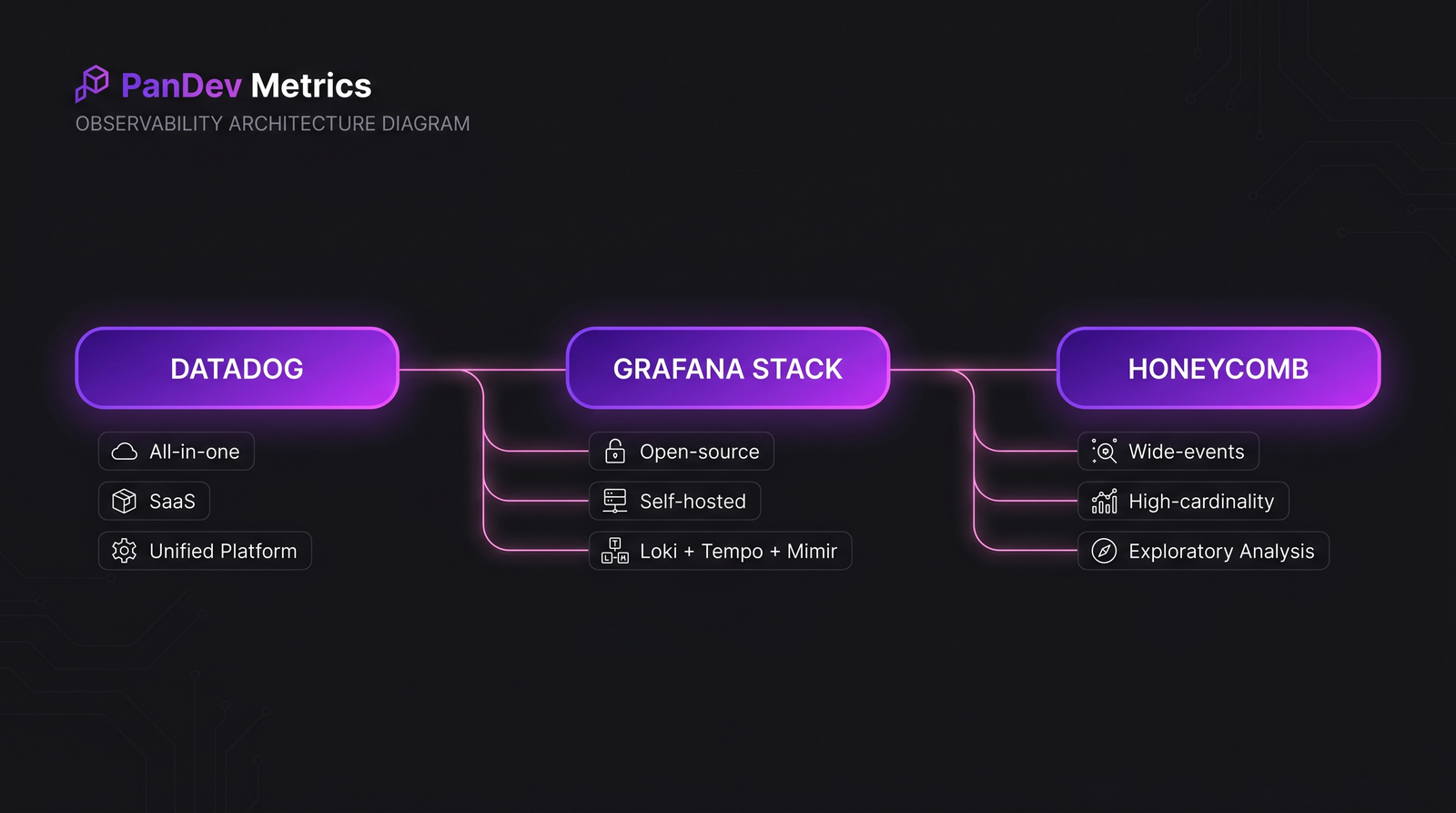
Datadog. All-in-one SaaS. Infrastructure monitoring, APM, логи, RUM, synthetic, security, CI visibility — один UI, один счёт, согласованный query-язык между пилларами. Самая большая доля рынка, больше всего интеграций, самая высокая unit-стоимость.
Grafana stack (Loki + Tempo + Mimir + Grafana Cloud или self-hosted). Open-source-first, с managed cloud-опцией. Best-in-class по цене за GB для логов и метрик на больших объёмах. Цена гибкости — вы собираете систему, а не покупаете её.
Honeycomb. Wide-events first. Дизайн вокруг предпосылки, что интересный вопрос неизвестен заранее, поэтому вы храните всё с high cardinality и нарезаете post-hoc. Best-in-class для дебага новых production-инцидентов. Уже scope, чем у двух других — нет infrastructure monitoring, нет RUM.
 Три инструмента — не прямые субституты. Выбор одного против других — обычно выбор того, какой failure mode вы можете себе позволить иметь.
Три инструмента — не прямые субституты. Выбор одного против других — обычно выбор того, какой failure mode вы можете себе позволить иметь.
Сравнение фича-за-фичей
Покрытие пилларов
| Пиллар | Datadog | Grafana stack | Honeycomb |
|---|---|---|---|
| Metrics | Нативно, first-class | Mimir (best-in-class на масштабе) | Выводятся из событий |
| Logs | Нативно | Loki | Через ingest; не primary shape |
| Traces (APM) | Нативный APM | Tempo | Нативные wide-events (трейсы — subset) |
| RUM | Нативно | Faro | Нет |
| Synthetic monitoring | Нативно | k6 Cloud | Нет |
| Infrastructure monitoring | Нативно | Разные экспортеры | Нет |
| CI visibility | Нативно | Ограничено | Нет |
| Security monitoring (SIEM) | Нативно | Ограничено | Нет |
Single-vendor история Datadog реальна — если нужен один инструмент на все пиллары, Datadog единственная опция в сравнении. Grafana совпадает на большинстве пилларов, но требует сборки. Honeycomb намеренно не пытается.
Мощь query-языка
| Возможность | Datadog | Grafana | Honeycomb |
|---|---|---|---|
| Metric queries (rate, avg, p99) | Отлично (DDSQL + legacy) | Отлично (PromQL) | N/A — не metric-first |
| Log querying | Хорошо, SaaS-hosted | LogQL (Loki) — хорошо, но ограничено на scale | N/A |
| Trace exploration | Хорошо, flamegraph-heavy | Tempo explorer — solid | Отлично — BubbleUp, slice-by-anything |
| Cardinality limits | Жёсткие на custom metrics | Жёсткие на Prometheus cardinality | Сделан для high cardinality |
| Ad-hoc исследование | Умеренно | Умеренно | Лидер категории |
BubbleUp + slice-by-anything UI у Honeycomb — самая ясная дифференциация на рынке: спросите «чем отличаются медленные запросы от быстрых?» и получите ранжированный ответ за секунды по любому полю. Datadog добавил похожее в 2024 (Error Tracking Explorer), но всё ещё отстаёт на high-cardinality атрибутах.
Модель хранения
| Аспект | Datadog | Grafana | Honeycomb |
|---|---|---|---|
| Где живут данные | Облако Datadog | Ваша инфра (или Grafana Cloud) | Облако Honeycomb |
| Стратегия сэмплинга | Index + retention tiers | Retention по таблице | Deterministic + dynamic sampling |
| Retention (default) | 15 мес metrics, 15 дней логов | Настраивается | 60 дней (events) |
| Data residency | US / EU / JP регионы | Где задеплоите | US / EU |
Для регулируемых отраслей — fintech, healthcare, оборонка — история «где задеплоите» решающая. Grafana self-hosted — единственная опция в сравнении, позволяющая инженерной телеметрии не покидать ваш периметр. Это та же причина, по которой наши on-prem клиенты часто паруют PanDev Metrics с self-hosted Grafana, а не с Datadog.
Реальность ценообразования
Публичные list-prices, сравнённые на реалистичном mid-size (150-инженерном) workload. Реальное enterprise-ценообразование всегда договорное — ожидайте 20-40% от list за committed usage, больше на большом масштабе.
Типовая годовая стоимость: 150 инженеров / 500 сервисов / умеренный объём
| Компонент | Datadog | Grafana Cloud | Grafana self-hosted | Honeycomb |
|---|---|---|---|---|
| Infra monitoring | $75-120K | $30-50K | Стоимость инфры | N/A |
| APM / traces | $60-120K | $25-45K | Стоимость инфры | $50-100K |
| Logs | $80-200K | $30-80K | Стоимость инфры | N/A (events) |
| RUM + Synthetic | $25-60K | $15-30K | Стоимость инфры | N/A |
| Время инженеров (эксплуатация) | Минимально | Умеренно | 1-2 FTE | Минимально |
| Всего | $250-500K | $100-200K | $80-150K + FTE | $50-100K |
Honeycomb выглядит самым дешёвым в таблице, потому что не конкурирует на всех пилларах — сравнивать wide-events инструмент с full-suite это яблоки к апельсинам. Честное чтение: стэк «Honeycomb + что-то ещё» стоит $150-250K, конкурентно с Grafana и дешевле Datadog.
Скрытые расходы
| Gotcha | Datadog | Grafana | Honeycomb |
|---|---|---|---|
| Custom metric overages | Жёстко — $0.05 за метрику в мес суммируется | Cardinality limits вызывают OOM, не overage | Нет |
| Log volume spikes | Биллится по ingest GB | Storage + query cost | Не применимо |
| New-feature creep | Каждый новый продукт добавляет line item | Open-source, но managed tier добавляет cost | Фокусный scope |
| Multi-region | Надбавка на enterprise | Бесплатно с self-host | Надбавка |
Ценообразование Datadog компаундирует по headcount И по adoption продуктов. Команды, приходящие в Datadog на 50 инженерах и растущие до 200, регулярно видят утроение годового счёта — больше сервисов, больше custom metrics, больше infrastructure monitoring, больше объёма логов.
Decision framework
Выбирайте Datadog, если:
- Нужен один инструмент на все observability-пиллары, и нет инженерных циклов интегрировать три
- Инженерная орг < 100 человек, и вы быстро растёте (Datadog масштабируется без operator-бремени)
- Security / compliance хочет одного аудитабельного вендора, не четверых
- Вы в облаке (AWS/GCP/Azure) и никогда не планируете уходить
Выбирайте Grafana (self-hosted или Cloud), если:
- У вас 1-2 FTE, которые могут owned observability-инфру
- Стоимость за GB важнее time-to-value (вы на > 100TB/мес)
- Нужен контроль резидентности данных (on-prem, суверенное облако, регулируемая отрасль)
- Стандартизировались на OpenTelemetry и хотите избежать vendor lock-in на query-слое
Выбирайте Honeycomb, если:
- Время расследования инцидентов — bottleneck, и вы хотите wide-events first
- Infrastructure / RUM уже решены где-то ещё
- Команда имеет дисциплину инструментировать wide events (не только метрики)
- Production-загадки более частые, чем reliability-проблемы
Integrated-stack альтернатива (честное упоминание)
Splunk, New Relic, Dynatrace не появляются в большинстве 2026 greenfield-обсуждений, но доминируют в enterprise. Splunk владеет security + логами в Fortune 500. New Relic развернулся на usage-based pricing в 2020 и конкурентен на APM для небольших команд. Dynatrace владеет APAC-enterprise рынком и имеет лучший AI-driven auto-instrumentation. Для стартапа или mid-size компании в 2026 три инструмента сравнения — реальное решение; для банка на 50,000 инженеров разговор обычно Datadog vs Splunk vs Dynatrace с Grafana self-hosted как open-source escape valve.
Итоговая матрица
| Измерение | Datadog | Grafana | Honeycomb |
|---|---|---|---|
| Покрытие пилларов | Лучшее | Хорошее (со сборкой) | Узкое (события) |
| Стоимость на масштабе | Дорого | Самое дешёвое (self-host) | Умеренно |
| Простота эксплуатации | Лучшее | Умеренно (self-host: сложно) | Лучшее |
| Data residency | Ограниченные регионы | Где угодно | Ограниченные регионы |
| High-cardinality дебаг | Умеренно | Умеренно | Лучшее |
| Time-to-value | Быстрее всего | Самое медленное (self-host) | Быстро |
| Vendor lock-in риск | Высокий | Низкий | Умеренный |
| Под 50-500 инженеров | Хорошо | Умеренно | Хорошо (как один инструмент стэка) |
| Под 5,000+ инженеров | Дорого | Хорошо | Хорошо (как один инструмент стэка) |
Контрарианское утверждение
Нарратив рынка observability оформляет выбор как рациональный cost-benefit. Это не так. Выбор инструмента — утверждение организационной идентичности: Datadog-шопы обычно имеют сильную product engineering и тонкий SRE-бенч; Grafana-шопы — сильную platform engineering и инвестируют в строительство; Honeycomb-шопы — инженеров, читающих академические статьи по теории observability. Инструменты успешны, потому что подходят культуре. Частый failure mode — не выбор «не того» инструмента, а выбор инструмента, не подходящего культуре, которая у вас есть, с последующим обвинением инструмента в стагнации adoption. Перед сравнением фич спросите, какая культура описывает вашу инженерную орг сегодня.
Честный лимит
Наше прямое наблюдение — 60+ инженерных команд на разных observability-стэках, чаще всего на комбинации Datadog + Grafana + self-hosted Prometheus. Сигнал по Honeycomb тоньше (3-5 команд, все в США или ЕС). Оценки ценообразования выше — из публичных list, разговоров с клиентами, публичных disclosures; реальное enterprise-договорное ценообразование может быть материально другим и меняется быстрее, чем любой блог-пост может отследить. Оценки query-языка и UX отражают 2026-Q2 состояние — все три вендора релизят существенные фичи поквартально, так что специфика UI-affordances лучше сверять с текущей документацией перед коммитом.
Где PanDev Metrics встраивается
PanDev Metrics — платформа инженерного интеллекта, не observability — мы работаем на слой выше. Мы потребляем сигналы из observability-стэков (commit → CI → deploy → alert), не конкурируя с ними. DORA-метрики, которые мы производим, требуют deployment events и incident timestamps — обе категории течёт через ваш observability-инструмент. Наши данные показывают, что команды, гоняющие Grafana self-hosted рядом с PanDev Metrics on-prem, группируются вокруг требований data-residency — та же причина self-host'ить observability часто причина self-host'ить engineering-intelligence.
Дополнительное чтение
- Top 15 Engineering Intelligence Tools 2026: полное рыночное сравнение — смежный рынок (engineering-intelligence, не observability) со своим вендорским ландшафтом
- MTTR: почему скорость восстановления важнее частоты предотвращения — метрика, которую выбор инструмента в конечном счёте двигает или не двигает
- PanDev Metrics vs Sleuth: за пределами DORA-трекинга — смежное сравнение для DORA + deployment-events слоя над observability
- External: CNCF Annual Survey — тренды adoption observability — публичная референсная работа по общерыночному направлению