Prompt engineering для dev-команд: общий плейбук

В большинстве инженерных команд 2026 года сидят на одной зарплатной ведомости три разных типа промпт-юзеров. Есть power user с 60-строчным Cursor rules, вычитанным за полгода. Есть casual user, который копипастит «fix this bug please» и в целом рад. И есть скептик, попробовавший два раза, получивший мусор и решивший, что AI-кодинг — хайп. AI-продуктивность вашей команды стягивается к среднему этих трёх, не к вершине.
Индивидуальный prompt skill — это личный лайфхак. Командный prompt engineering — это процесс. И большинство команд пока так его не воспринимают. Распишем плейбук: что шарить, что оставлять индивидуальным, какие метрики говорят, что работает, и какие failure mode мы видели у клиентов.
{/* truncate */}
Проблема: prompt skill — tacit knowledge
Stack Overflow Developer Survey 2024: 76% разработчиков используют AI-инструменты, но только 12% оценивают результат как «высоко надёжный» без ревью. Gap между использованием и доверием — и есть место, где живёт командный prompt engineering. Индивидуалы компенсируют личными привычками. Команды — общим набором этих привычек.
Внутреннее исследование GitHub по Copilot (Kalliamvakou et al., 2024): команды с общими prompt-библиотеками имели на 35% выше acceptance rate AI-кода, чем команды, где каждый пишет промпты с нуля. Механизм не таинственный: общие промпты кодируют имплицитное знание команды (конвенции, стиль, паттерны тестов), которое сырой промпт передать не может.
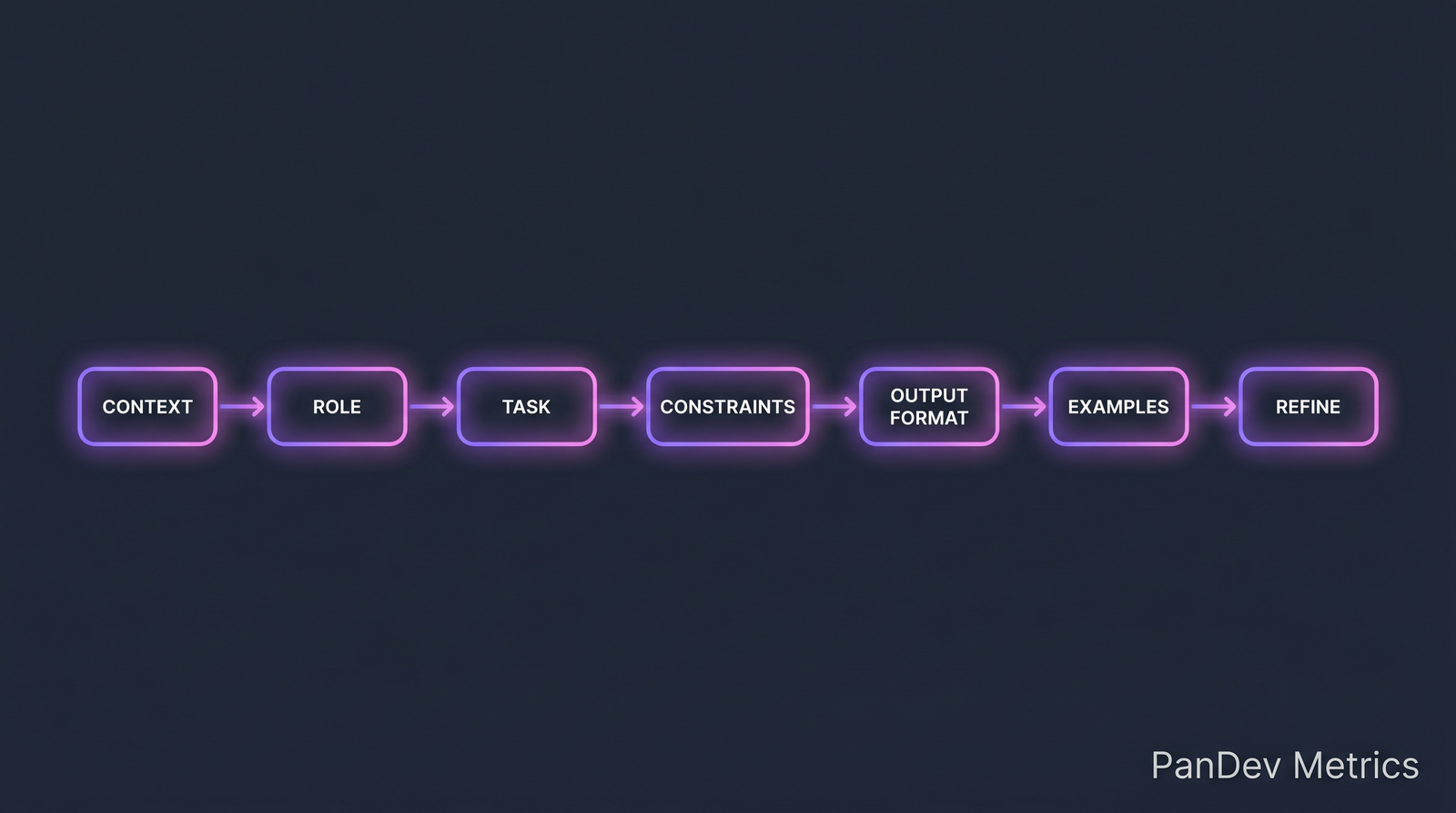 Семичастная структура промпта, которая работает для генерации кода. Команды сходятся на вариациях этого.
Семичастная структура промпта, которая работает для генерации кода. Команды сходятся на вариациях этого.
Что шарить, а что оставить индивидуальным
Общее (команда):
- Конвенции стиля кода (именование, структура, обработка ошибок)
- Паттерны тестов (фреймворк, стиль assert, моки)
- Архитектурные ограничения (слои, запрещённые паттерны)
- Security-правила (валидация input, работа с секретами, auth)
- Ожидания к докам (JSDoc/TSDoc, плотность комментариев)
Индивидуальное (разработчик):
- Когнитивный стиль (кто-то хочет пошаговое рассуждение, кто-то one-shot)
- Личные шорткаты и алиасы
- Контекст конкретной задачи (например, «я сейчас дебажу поток платежей»)
Общий набор идёт в командную prompt-библиотеку (.cursor/rules, .github/copilot-instructions.md, или что использует ваш инструмент). Индивидуальный остаётся в голове или в personal config.
7 частей полезного промпта
Полезный промпт для кодовых задач имеет 7 компонентов. Пропуск — за ваш счёт:
| Часть | Что делает | Пример |
|---|---|---|
| Context | Заземляет модель в ситуации | «Мы делаем Node.js/Express API для платежей, TypeScript strict». |
| Role | Устанавливает ожидания поведения | «Действуй как сеньорный backend-инженер, ревьюящий безопасность». |
| Task | Конкретное действие | «Отрефактори handler — вынеси валидацию, бизнес-логику, persist». |
| Constraints | Чего НЕ делать | «Не добавляй зависимостей. Сохрани существующие типы ошибок». |
| Output format | Как подать ответ | «Верни полный рефакторенный файл + bullet list изменений поведения». |
| Examples | Фиксирует стиль (few-shot) | «Вот как у нас структурированы похожие handlers: [пример]» |
| Refine | Возможность уточнить | «Если контекст неоднозначен — спроси, не додумывай». |
Большинство команд правильно делает Task и Context, остальное — пропускают. Компаундная ценность — от Constraints (не даёт модели полезно всё сломать) и Examples (учит стилю быстрее правил).
Prompt-библиотека: что в version control
Структура prompt-библиотеки — именованные композируемые промпты. Минимальная форма, как у одного из наших клиентов:
.team-prompts/
rules/
style.md # стиль кода команды
testing.md # паттерны тестов
security.md # security-правила
templates/
new-endpoint.md # шаблон нового API endpoint
new-component.md # шаблон нового React-компонента
refactor-legacy.md
add-tests.md
examples/
handler-example.ts
component-example.tsx
В каждом шаблоне — 7 частей заполнены. Разработчики вызывают через механику инструмента (@new-endpoint в Cursor, #new-endpoint в Copilot Chat).
Киллер-фича: разработчик, никогда продуктивно не использовавший AI, в первый же день вызывает оттестированный командный шаблон и получает хороший результат. Библиотека — это общая мышечная память.
Метрики, что это работает
Четыре измеримые вещи:
| Метрика | Здоровый диапазон | Сигнал тревоги |
|---|---|---|
| % AI-кода, который мержится без переделки | >60% | <40% |
| Часов в неделю, сэкономленных на разработчика (self-report) | 3-8 | <1 (инструмент не приживается) или >15 (over-trust) |
| % команды, использующей шаблоны (еженедельно) | >70% | <30% = библиотека мертва |
| Defect rate AI-кода vs рукопис | Равно или ниже | Выше — недостаточное ревью |
Over-trust — реальный риск. Разработчики, заявляющие «15 часов в неделю», обычно переоценивают и обычно мержат AI-код с меньшей скрупулёзностью. GitClear 2024: репы с активным Copilot показали +25% churn (код, откачиваемый в течение 2 недель) по сравнению с не-Copilot. Продуктивность, выигранная на генерации, частично теряется на переделке.
Типовые failure mode
1. Непроверенный образец
Кто-то в Slack пишет «идеальный промпт». Никто не тестирует на 5 реальных задачах. Он копируется в библиотеку. Через три месяца все ругают шаблон, и никто не знает, чей он. Фикс: у каждого шаблона есть CODEOWNER и тест-кейсы (3-5 реальных с ожидаемыми output).
2. Раздувшийся rules-файл
Cursor rules команды разрастается до 400 строк. У каждого разработчика претензия на одно правило, никто не хочет удалять чужое, модель тонет — все получают хуже результат. Фикс: rules-файл имеет лимит строк (50-80). Прореживается квартально.
3. Конфликтующие шаблоны
Два шаблона «new endpoint» — старый и новый, — никто не знает, какой актуальный. Фикс: единый источник истины, старое помечается deprecated, удаляется после grace period.
4. Скрытый герой
Один разработчик пишет крутые промпты. Никто не учится, все просто пингуют его. Фикс: pair-prompt сессии в ретро. Знание должно течь по команде.
Как разворачивать командную prompt-практику
Работающий 4-недельный план:
Неделя 1 — аудит. Опрос команды: кто чем пользуется, что работает, что нет. Выявить 2-3 power user как соавторов библиотеки.
Неделя 2 — 3 шаблона. Не 20. Три самых частых задачи (new endpoint, add tests, refactor). Power user-ы делают драфт, команда ревьюит.
Неделя 3 — пилот. Каждый разработчик использует шаблон хотя бы раз. Собираются заметки о трениях.
Неделя 4 — итерация и формализация. Шаблоны в репо с CODEOWNERS. Квартальная ревизия. Добавить в onboarding.
Команды, стартующие с 20 шаблонами, проваливаются. Команды, стартующие с 3 хорошими, — выигрывают и органически растут за полгода.
Где вписывается PanDev Metrics
Две применимые к измерению вещи:
Трекинг AI-origin кода. Наша Git-интеграция может помечать коммиты, рождённые из AI-сессии (детектится по IDE-сигналу: длительные периоды высокой скорости вывода без соответствия human typing cadence). Сравнение качества AI-origin коммитов (defect rate, циклы ревью, revert rate) с рукописью даёт жёсткое число: положителен ли AI-инструментарий net-net для команды.
Adoption шаблонов как сигнал. Корреляция паттернов PR с использованием шаблонов — если PR разработчика стабильно следует структуре шаблона, библиотека работает. Если паттерны разрознены — нет.
Это дополняет наше исследование AI copilot effect — Cursor-пользователи пишут 65% больше кода, чем VS Code, но оно не разделяло «больше зашипили» и «больше написали того, что откатили». Хорошо управляемая библиотека этот gap закрывает. Общая измерительная рамка — в AI Assistant deep-dive.
Честный лимит
Мы видим IDE-активность и Git, но не содержимое промптов — мы не знаем, что вы запромптили, только что сессия родила код. Числа по ROI библиотеки (35% прирост acceptance) — из публичного ресёрча GitHub, не из нашей телеметрии. Мы можем сказать, помогают ли AI-инструменты команде шипить больше; не можем сказать, какой из ваших промптов хороший.
Ещё: prompt engineering движется быстро. Техника, работающая сегодня, может стать избыточной с выходом следующей модели. Инвестируйте в практику (библиотеки, ревью, итерация), а не в конкретное содержимое.
Самый жёсткий тезис
Команда с лучшими промптами в 2026 — не та, где самый остроумный индивидуал. А та, что обращается с промптами как с кодом: version-control, ревью, депрекация, владение. Те же практики, что сделали вашу кодовую базу поддерживаемой, сделают и библиотеку промптов. Команды, пропускающие этот шаг, переизобретают ad hoc knowledge management и проиграют тем, кто не пропустил.
По теме
- The AI Copilot Effect: Cursor +65% — базовые данные использования
- AI Assistant: Natural Language — как устроен наш AI-ассистент
- Code Review Checklist 2026 — где оценивается AI-код
- Внешнее: GitHub Copilot Research (Kalliamvakou et al., 2024) — измеримое влияние prompt-библиотек
- Внешнее: Stack Overflow Developer Survey 2024 — базовые показатели использования и доверия