RAG или fine-tuning для документации: что выиграет?

Платформенная команда в компании на 600 инженеров потратила $340 000 за 9 месяцев, дообучая 13B-параметровую модель на своей внутренней документации. Launch day: модель отвечала правильно примерно на 72% частых вопросов и уже на 3 недели устарела в день запуска. После этого за 2.5 недели и $18 000 они построили RAG-пайплайн поверх того же корпуса. Он отвечал на 88% частых вопросов и всегда был актуален. Fine-tuned-модель тихо отправили на пенсию через полгода параллельной эксплуатации.
Это доминирующий паттерн 2025-2026: для внутренней документации разработчика RAG выиграл по экономике и свежести. Fine-tuning всё ещё побеждает в отдельных кейсах — специфика домена, выравнивание стиля, жёсткие требования по латенси. Но "дообучить LLM на нашей вики" — уже неправильный дефолт. Бенчмарки OpenAI DevDay 2024 показали, что RAG обгоняет fine-tuning в 14 из 16 сценариев QA по документации по точности и свежести, при стоимости в 8-40 раз ниже. Разберём, когда что реально имеет смысл.
{/* truncate */}
Позиционирование
RAG (Retrieval-Augmented Generation): доставать релевантные куски документации на момент запроса, подсовывать LLM как контекст, ответ генерировать ею. Корпус изменился? Переиндексировать. Дёшево, свежо, цитирование источника получается естественно.
Fine-tuning: взять базовую LLM, дообучить её на вашем корпусе, знания живут в весах. Корпус изменился? Переобучать (медленно, дорого). Ответы идут из "памяти", не из lookup.
Meta в статье по Llama 2024 (Dubey et al.) явно разделили "knowledge injection" и "behavior shaping" как два use case fine-tuning — и заключили, что fine-tuning слаб для knowledge injection в сравнении с RAG. Для поведения (тон, формат, паттерны отказов, словарь домена) fine-tuning остаётся правильным. Для "что делает наш API?" — побеждает RAG.
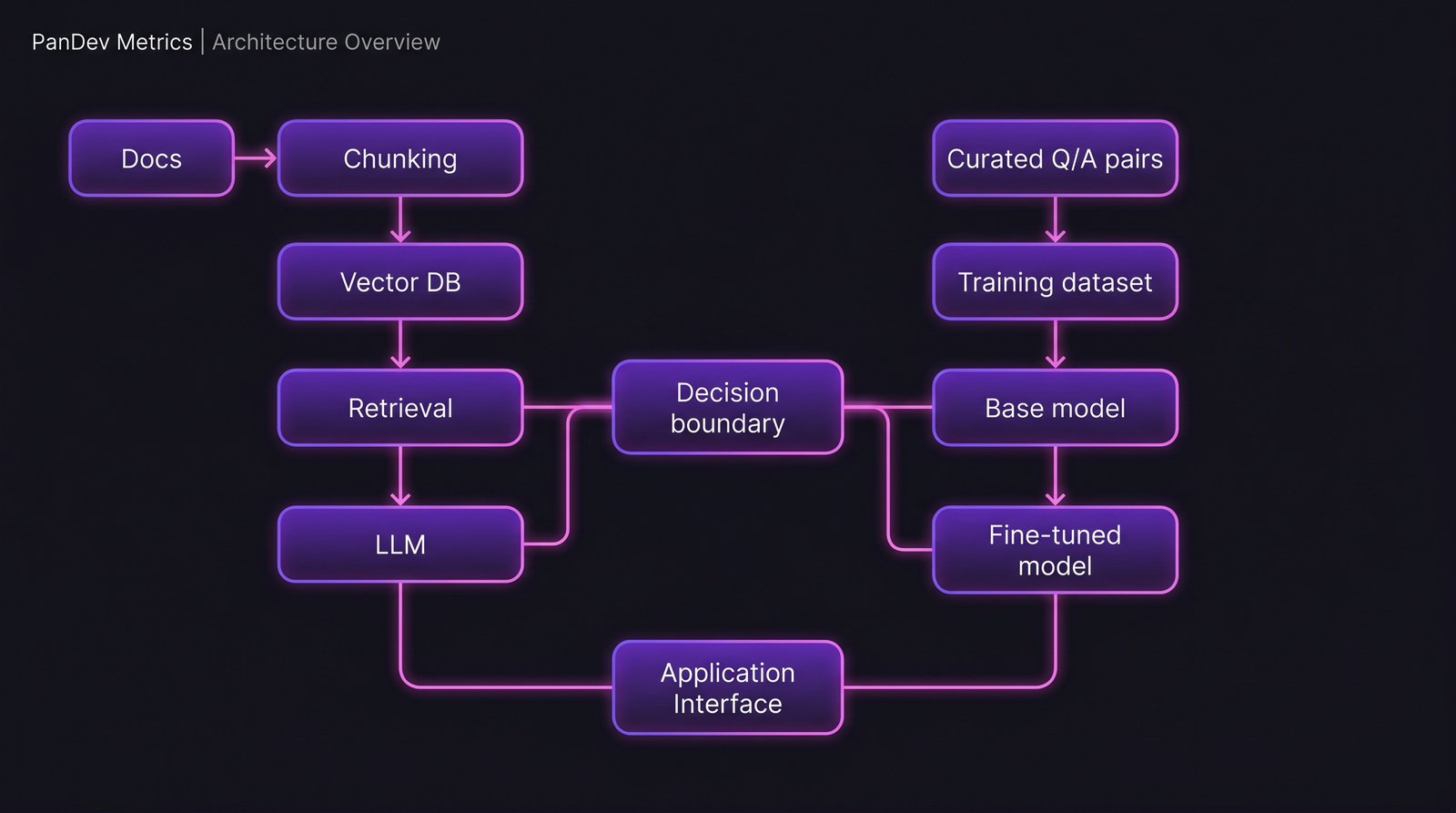 Два пайплайна. У RAG больше движущихся частей; у fine-tuning одна тяжёлая часть. Эта форма предсказывает большую часть различий в стоимости и поддержке.
Два пайплайна. У RAG больше движущихся частей; у fine-tuning одна тяжёлая часть. Эта форма предсказывает большую часть различий в стоимости и поддержке.
Сравнение по функциям
Стоимость (build + run)
| Тип затрат | RAG | Fine-tuning |
|---|---|---|
| Initial build (малый/средний корпус) | $5-30k | $50-400k |
| Re-ingest при изменениях | $100-500 | Полный retrain: $50k+ |
| Inference за запрос (GPT-4-класс) | $0.003-0.02 | $0.001-0.01 (чуть дешевле) |
| Vector DB / хостинг | $200-2000/мес | $500-5000/мес (хостинг модели) |
| Инженерная поддержка | 0.3-0.5 FTE | 1-2 FTE |
Для команды с корпусом до 1M токенов, меняющимся еженедельно, RAG выигрывает в 10-40 раз. Для корпуса до 100k токенов, меняющегося ежегодно, с миллионами запросов в сутки и жёстким латенси (скажем, customer-facing продукт), fine-tuning начинает экономически окупаться.
Свежесть
| Сценарий | RAG | Fine-tuning |
|---|---|---|
| Добавлен новый документ | Индексируется за минуты | Устарело до retrain |
| Документ обновлён | Следующий запрос читает новую версию | Устарело до retrain |
| Документ удалён | Сразу пропадает из результатов | "Призрачное" знание остаётся в весах |
| Compliance требует удалить (GDPR, утечка секрета) | Фильтр на retrieval | Retrain (медленно, неидеально) |
Свежесть — аргумент, ломающий fine-tuning для большинства внутренних доков. Инженерные доки меняются постоянно. В тот момент, когда fine-tuned-модель ответит "используйте deprecated endpoint", потому что retrain ещё не прошёл, вы создали liability. RAG падает мягко (нет ответа, старый кусок с датой) так, как fine-tuning не умеет.
Точность
Здесь важны нюансы. Ни один не точнее универсально.
| Сценарий | Типичный победитель | Почему |
|---|---|---|
| Фактический lookup ("какой rate limit?") | RAG | Прямой retrieval источника, верифицируемое цитирование |
| Выравнивание стиля/словаря | Fine-tuning | Изученные паттерны вшиты в веса |
| Multi-hop рассуждение по докам | Смешанно (RAG + reranker) | Требует аккуратной стратегии чанкинга |
| Новые комбинации / экстраполяция | Fine-tuning | RAG не достанет то, чего не написано |
| Запросы с опечатками / плохой формулировкой | Fine-tuning | Устойчивость базовой модели |
| Синтез на длинном контексте | RAG (если куски помещаются) | Retrieval ограничивает контекст |
Исследование Anthropic по Constitutional AI (2024) показало: RAG с contextual re-ranking даёт на 18% меньше галлюцинаций, чем fine-tuned модели на factual QA — но fine-tuned модели лучше по "консистентности формата ответа". Оба утверждения верны и описывают разные оси.
Цитирование и аудит
Это крупнейшее и часто упускаемое преимущество RAG. Каждый RAG-ответ может цитировать кусок источника. Fine-tuned-модели — не могут: их ответ синтезирован из весов, и "откуда это взялось?" остаётся без ответа.
Для инженерных команд это важнее точности. Инженер, получивший RAG-ответ с "source: [runbook-auth.md line 47]", может проверить. Инженер с fine-tuned-ответом без происхождения должен либо верить, либо перепроверять. Стоимость верификации имеет значение.
Латенси
| Этап | RAG | Fine-tuning |
|---|---|---|
| Retrieval + rerank | 100-400мс | N/A |
| LLM generation | 1-5с | 1-5с |
| Total P95 | 1.5-6с | 1-5с |
Fine-tuning может быть быстрее при жёстком латенси (чат-UI, где sub-second ощущается лучше). Для инженерной документации, которую читают инженеры, 500мс retrieval-оверхеда — шум. Лишняя латенси важна в продуктовых интеграциях, не во внутренних инструментах.
Реальная экономика (что видим на практике)
Три реальных сценария из наших клиентов (анонимизированы):
Команда A — 40 инженеров, 80k-токенная вики, ~50 запросов/день. RAG: 2 недели на сборку, $800/мес в эксплуатации, ~90% качество ответов. Цена за первый год: $28k. Fine-tune-альтернатива (оценка): $150k на сборку, $4k/мес + ежеквартальный retrain. Отказались до старта.
Команда B — 220 инженеров, 3M токенов доков в вики + Slack + Jira, ~400 запросов/день. RAG: 6 недель на сборку, $2.8k/мес. Работает сейчас. Оценили fine-tuning, отклонили по свежести (доки обновляются ежедневно).
Команда C — 1100 инженеров, 40M-токенная документация, большое разнообразие запросов. Гибрид. RAG для lookup, fine-tuned для форматирования/отказов/стиля. Fine-tuning дополняет RAG, а не заменяет. Общая стоимость: $380k/год, 12 000 запросов/день.
Паттерн: на масштабе побеждает гибрид. На малом и среднем масштабе — один RAG. Fine-tuning сам по себе редко побеждает для документации.
Фреймворк решения
Берите RAG, если:
- Доки меняются чаще раза в месяц
- Нужны цитаты источников для доверия / аудита
- Размер корпуса больше 200k токенов
- Объём запросов меньше 10 000/день
- Команда сборки — меньше 3 инженеров
- Нужно отвечать "откуда ты это взял?"
Берите fine-tuning, если:
- Нужна специфическая консистентность тона/формата (бренд-голос, паттерны отказов)
- Латенси должна быть под 1 секунду P95
- Запросов больше 100 000/день и стоимость inference важна
- Корпус стабилен (обновления раз в квартал и реже)
- У вас уже есть ML-команда с fine-tuning-пайплайнами
Берите гибрид, если:
- Вы на масштабе 500+ инженеров
- Нужны и точность, и бренд-консистентность
- У вас >1 FTE ML-инженерии на поддержку
Где PanDev Metrics в этом разговоре
Мы не продаём внутренний-docs AI. Что наш продукт пересекает: измерение времени, которое инженер тратит на поиск информации. Наш IDE heartbeat ловит, когда инженеры уходят из редактора в вики, Slack, Stack Overflow. Команды, разворачивающие RAG или fine-tuned docs-ассистент, могут использовать это как baseline — если после деплоя time-to-answer в редакторе падает, инструмент окупается.
Одна честная нота: у нас нет контролируемого эксперимента по базе клиентов, сравнивающего "ассистент развернут" vs "не развернут" при всём равном. Наш сигнал — корреляция, не причинность. Что видим: команды с любым in-editor docs-search инструментом (включая простые) сокращают tab-switching на 12-18% в среднем. Стоит ли это цены сборки — зависит от размера команды.
Контринтуитивный тезис
Большинство проектов "дообучить LLM на доки" 2024-2025 — это маркетинг-driven технические решения, не прошедшие инженерное ревью. Экономика RAG слишком сильна для малого и среднего масштаба. Исключения узки и хорошо определены: стиль, латенси, очень высокий объём запросов. Для медианной инженерной команды, решающей "AI для внутренних доков", дефолт должен быть RAG first, fine-tuning добавлять только при появлении оси, которую RAG не закрывает.
Честный лимит: мы смотрим на это со стороны тулинга, не гоняем LLM-оценки сами. Наши цифры — это то, что клиенты сообщают, плюс публичные бенчмарки (Meta, OpenAI, Anthropic). Экономика LLM сдвигается каждые 6 месяцев — соотношения в статье могут выглядеть иначе к концу 2026, когда frontier-модели поменьше приближаются по fine-tuning-стоимости.
Что почитать
- Claude vs ChatGPT vs Copilot 2026: какой AI шипит production-код
- Self-Hosted LLM для инженерных команд
- Пользователи Cursor кодят на 65% больше: AI Copilot Impact
Если команда обсуждает RAG vs fine-tuning для внутренних доков, начните с одного вопроса: как часто меняется корпус? Ответ обычно решает архитектуру до любых бенчмарков.