Self-hosted LLM для инженерных команд: цена, приватность, задержка

Финтех на 40 инженеров, с которыми я говорил в прошлом месяце, платил $960 в месяц за GitHub Copilot Business на всю команду, но их юристы только что заблокировали использование после compliance-review: телеметрия code completion уходила через облако Microsoft. CTO задал мне обманчиво простой вопрос: «Можем ли мы self-host'ить эквивалент?»
Ответ — «да, но только если пройдёте три фильтра». Stack Overflow Developer Survey 2024 показал, что 76% разработчиков используют или планируют использовать AI-инструменты, но в регулируемых индустриях adoption отстаёт на 20-30 пунктов. Разрыв — не в скепсисе, а в инфраструктуре. Большинство команд хотят приватный inference, но недооценивают, во что «self-hosted» обходится по GPU capex, времени SRE и компромиссу в качестве модели.
Это фреймворк, который мы даём командам, обдумывающим переход: когда self-hosted LLM бьёт облако, когда нет, и три точки, где математика переворачивается.
{/* truncate */}
Проблема: облачные LLM проваливают три use-case
Copilot, Cursor, Claude Code — отличные продукты для своих случаев. Они предсказуемо проваливаются в трёх средах:
Код под compliance. Банкинг, страхование, оборонка, здравоохранение — отрасли, где отправка продового кода в чужое облако нарушает регуляцию или контракт. Юристы BigCo не хотят, чтобы PII клиента случайно оказался в training data, и не могут это полностью исключить даже на enterprise-тарифах.
Air-gapped или data-residency среды. Госконтракторы, EU-компании с GDPR-строгими клиентами, компании в СНГ под локальными законами о резидентности (РФ 152-ФЗ, закон Казахстана о персональных данных). Они не могут отправлять байты на api.openai.com независимо от цены.
High-usage команды, где per-seat становится иррациональным. Выше ~200 инженеров на heavy-completion плане per-seat превышает amortized cost собственного inference-кластера. Математика разворачивается.
Если ничего из этого не про вас — оставайтесь в облаке. Self-hosting сам по себе не добродетель: это ответ на конкретные ограничения, которые есть не у всех.
Честное сравнение стоимости
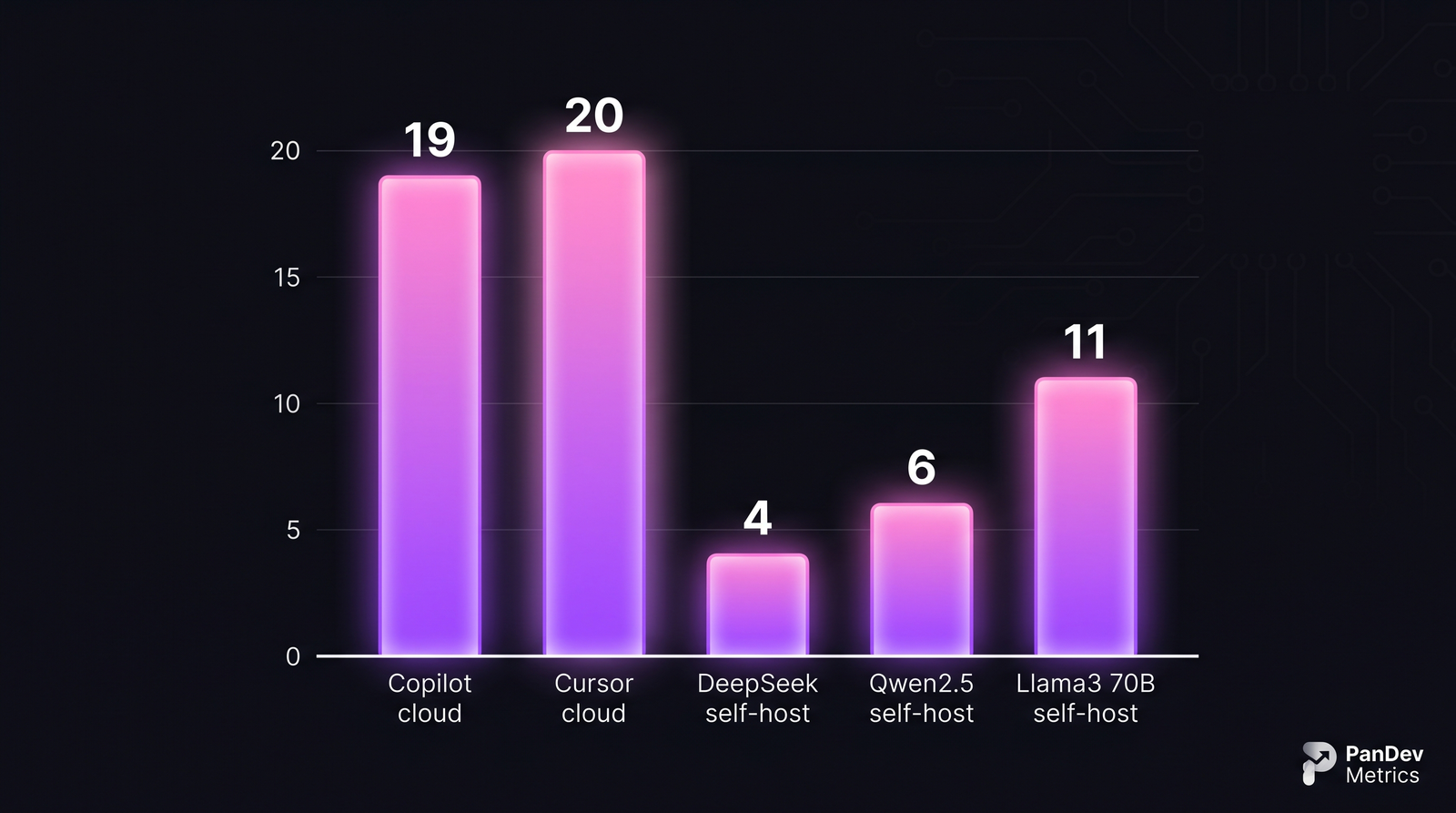 Амортизированная месячная стоимость на разработчика при размере команды 50, предполагая 24/7 доступность inference. Self-hosting выигрывает по цене только после амортизации — upfront GPU-расход реален.
Амортизированная месячная стоимость на разработчика при размере команды 50, предполагая 24/7 доступность inference. Self-hosting выигрывает по цене только после амортизации — upfront GPU-расход реален.
Цифры $4-$11 на self-host недостижимы в день один. Они предполагают:
- Амортизацию GPU на 30 месяцев. H100 ~$30K; L40S или Ada 6000 — $6-9K. Финансовый отдел должен быть спокоен с такой формой capex.
- Электричество и охлаждение уже оплачены. Команды в колокейшне или корпоративном ДЦ это покрыли; команды без инфраструктуры сравнивают cloud-hosted inference с cloud-hosted inference, что обнуляет смысл.
- Один SRE на ~20% аллокации. Self-hosted LLM нужен именованный владелец, а не «платформа, в целом». Обновления моделей, прогрев кэша, мониторинг GPU, failover — это реальная работа.
Если хотя бы одно из трёх не выполняется, добавьте 50-150% к per-developer cost и пересчитайте.
Trade-offs по моделям (baselines на конец 2026)
| Модель | Коммерческое использование | Качество code completion | Требуемая RAM/VRAM | Типичная задержка inference |
|---|---|---|---|---|
| DeepSeek Coder V3 236B | Коммерческая | Отлично (на уровне GPT-4o) | 4× H100 или 8× L40S | 300-700 мс первый токен |
| Qwen2.5-Coder 32B | Apache 2.0 | Очень хорошо для большинства задач | 1× H100 или 2× L40S | 150-400 мс |
| Llama 3.3 70B Instruct | Meta License | Очень хорошо (generalist) | 2× H100 | 200-500 мс |
| StarCoder2 15B | BigCode OpenRAIL | Хорошо для FIM completion | 1× L40S | 80-200 мс |
| Code Llama 34B | Meta License | Нормально (устаревает, 2023) | 1× H100 или 2× L40S | 250-600 мс |
Лицензия важнее, чем думают. Community-лицензия Meta содержит пункты по численности и выручке, которые крупные предприятия иногда не могут выполнить. Apache 2.0 (Qwen) и MIT (веса DeepSeek на 2025) — чище всего для коммерческого использования. Всегда подключайте legal до выбора базовой модели для регулируемой нагрузки.
Фреймворк из трёх точек
Когда нужно self-host'ить, в порядке проверки:
Точка 1: Регуляторный тест
Вопрос: Нужно ли вашему compliance или legal заверить, что продовый код не ходит через third-party провайдера?
Если да — цена и качество вторичны. Self-host, точка. Вопрос — какая модель, а не стоит ли. Переходите к точке 3 для выбора модели.
Если нет — переходите к точке 2.
Точка 2: Тест масштаба
Вопрос: Сколько разработчиков и насколько интенсивно используют AI?
Формула (грубо): годовая cloud-стоимость = разработчики × цена_плана × 12. Годовая self-host = capex / 30 × 12 + opex × 12.
| Размер команды | Лёгкое использование (~5 completions/день) | Среднее (~50/день) | Тяжёлое (~500/день, Cursor Pro) |
|---|---|---|---|
| 20 инженеров | Облако уверенно | Облако | Близко, облако чуть впереди |
| 50 инженеров | Облако | Близко | Self-host выигрывает |
| 100 инженеров | Близко | Self-host выигрывает | Self-host уверенно |
| 200+ инженеров | Self-host начинает выигрывать | Self-host уверенно | Self-host доминирует |
Таблица считает одну модель. Если нужны две (маленькая быстрая для autocomplete, большая для chat), точка безубыточности смещается вверх на 30-50 инженеров.
Если масштаб или регуляция оправдывают self-host — идём дальше.
Точка 3: Тест задержки и качества
Вопрос: Какая допустимая first-token latency и минимальное качество completion, которое команда вытерпит?
Self-hosting почти всегда увеличивает first-token latency относительно Copilot (у которого глобальные POP и агрессивный кэш). 150-400 мс — приемлемо для большинства chat-потоков; для inline autocomplete разработчики замечают всё выше ~200 мс.
Варианты:
- Autocomplete: Qwen2.5-Coder 32B или StarCoder2 15B. Достаточно маленькие, чтобы отвечать быстро.
- Chat / рефакторинг: DeepSeek Coder V3 или Llama 3.3 70B. Медленнее, но качественно сильнее.
- Оба use-case: запускайте обе модели. Конфигурация, на которую приходит большинство enterprise self-host.
Качество моделей меняется быстрее, чем этот пост останется актуальным. Пока вы читаете, DeepSeek Coder мог выпустить V4 или быть обойдён новым Qwen. Фреймворк держится; конкретные выборы — нет. Сверяйте бенчмарки (HumanEval, MBPP, SWE-bench) за последние 60 дней до коммита.
Пошаговая настройка
Шаг 1 — Выбрать inference runtime
Модель будет работать на одном из:
- vLLM — дефолт для большинства. Быстрый, поддерживает OpenAI-совместимый API.
- TGI (Text Generation Inference, Hugging Face) — стабильный, хорош для команд в HF-экосистеме.
- SGLang — новее, силён в structured output; стоит оценить, если строите инструменты поверх LLM.
- llama.cpp server — для CPU-only или скромных GPU; потолок качества ниже, но цена радикально ниже.
В прод начинайте с vLLM, если нет конкретной причины не делать этого.
Шаг 2 — Выбрать интерфейс для разработчика
Ваши инженеры привыкли к Copilot. Workflow «вставить в web UI» они не примут. Нужен IDE-интегрированный клиент, указывающий на ваш self-hosted endpoint. Хорошие варианты:
- Continue.dev — open-source плагин VS Code + JetBrains, поддерживает любой OpenAI-совместимый backend. Дефолт в 2026.
- Tabby — полный стек (serving модели + IDE-плагины), opinionated, но поднимает за час.
- Cody Enterprise (Sourcegraph) — коммерческий, может указывать на self-hosted модели; хорош, если уже используете Sourcegraph.
Adoption команды зависит почти целиком от этого слоя, а не от модели. Отличная модель с неуклюжим IDE-опытом бросается за две недели.
Шаг 3 — Построить observability
Вы не будете знать, помогает ли LLM, пока не меряете. Трекать:
- Completion acceptance rate (доля подсказок, которые разработчик оставляет)
- Распределение latency (p50, p95, p99 first-token)
- Использование по командам/проектам (кто принял, кто нет, почему)
- Error rate (галлюцинированные импорты, неверный синтаксис, out-of-context completions)
Наши клиенты, хорошо это делающие, видят acceptance rate 25-40% для autocomplete на Copilot-классе моделей; значительно ниже (10-20%) на первых self-hosted конфигурациях до тюнинга. Низкий acceptance fixable; невидимый acceptance — нет. Данные, которые PanDev Metrics выдаёт через IDE heartbeat плюс трекинг completion-событий, замыкают цикл — видно, какой IDE/проект/команда реально выигрывает.
Шаг 4 — Агрессивно прогревать кэш
Self-hosted LLM без прогрева кэша демонстрирует жёсткое cold-start поведение — первый запрос после смены модели или рестарта занимает секунды. vLLM и SGLang поддерживают prefix caching; включите и прогрейте типовые промпты при деплое.
Команды, пропускающие этот шаг, получают «self-hosted LLM медленный» и винят модель. Почти всегда — холодный кэш.
Шаг 5 — Заложить fine-tune или RAG-слой
Из коробки базовая модель не знает ваши внутренние API, конвенции, выборы библиотек. Два пути:
- Fine-tuning (Qwen2.5-Coder и Llama 3 поддерживают LoRA-адаптеры) — хорошо, если у вас >10K внутренних примеров из репозитория.
- Retrieval-augmented generation (RAG) — подкармливать модель вашим внутренним кодом и документацией на inference. Проще, меньше поддержки, обычно лучше для небольших организаций.
Большинство команд недооценивают этот шаг и переделывают шаг 1. Generic Qwen2.5-Coder, отвечающий про ваш 5-летний внутренний Python-фреймворк, производит уверенные неправильные ответы. RAG по кодовой базе чинит 70% этого без fine-tune.
Типичные ошибки
| Ошибка | Почему вредит | Как исправить |
|---|---|---|
| Покупка H100 до пилота | Capex до сигнала — вы не знаете, какая модель зайдёт | Стартовать на 2× L40S или облачном GPU на 60 дней |
| Инженеры выбирают модель неформально | 10 инженеров — 7 моделей, adoption нет | Централизованное решение платформы, одна-две модели на всю организацию |
| Пропуск слоя IDE-интеграции | Модель работает — никто не пользуется | Заложите на Continue.dev/Tabby столько же времени, сколько на serving |
| Нет RAG / нет fine-tune | Уверенные галлюцинации по внутренним API | Минимум: вектор-поиск по топ-50 репозиториям |
| Inference на GPU dev-команды | Контеншн убивает latency | Отдельный inference-кластер, полностью выделенный |
Как мерить успех
Если через 90 дней после rollout вы не можете ответить на эти вопросы — проект в беде:
- Какой у вас completion acceptance rate? Меньше 15% — модель или prompt-слой требуют работы.
- Какой процент активных инженеров пользуется еженедельно? Меньше 50% — IDE-интеграция или latency мешают adoption.
- Стоимость на активного пользователя? Сравнение с cloud-альтернативой — это CFO-обоснование.
PanDev Metrics отслеживает IDE-сессии, включая установлены ли AI-assist плагины и активно ли они эмитят события; мы также видим, какие языки и проекты получают heavy AI-completion активность, а какие нет. Данные позволяют инженерному лидеру ответить «LLM помогает команде A, а команде B нет — почему?» — это более actionable вопрос, чем «какой средний acceptance rate?».
Контрарная позиция
Большинство гайдов про «self-hosted LLM для разработчиков» обсуждают качество модели. Я утверждаю, что качество — третий по важности фактор, после IDE-интеграции и прогрева кэша. Middle-модель с отличным тулингом бьёт top-tier модель с неуклюжим плагином каждый раз. Команды, проваливающие self-hosted LLM, обычно проваливают workflow-слой, а не слой весов.
Следствие: если ваша команда полгода работала с Copilot или Cursor, её неявный baseline «хороший AI coding assist» включает IDE-опыт, а не только качество модели. Догоните baseline или adoption рухнет.
Когда self-hosting не подходит
Три сценария, где оставаться в облаке правильно:
- Меньше 50 инженеров без регуляторных ограничений. Cloud дешевле, качество выше, у команды есть дела поважнее.
- Команда без платформенного инженера или SRE. Self-hosted LLM нужен владелец. Нет 20% capacity ни у кого — не начинайте.
- Организация, где adoption AI-инструментов ещё обсуждается. Не решайте инфраструктурные проблемы до решения adoption-проблем. Докажите ценность на облаке, потом думайте о переходе.
Честное ограничение
Наш датасет покрывает паттерны использования IDE, adoption плагинов и распределение языков в 100+ B2B-компаниях. Чего у нас нет — прямой телеметрии по completion acceptance rates для self-hosted LLM в масштабе. Эти данные живут в inference-стеке (vLLM, TGI), а не в IDE heartbeat. Числа по acceptance взяты из интервью с клиентами и публичных данных вендоров (Tabby, Continue.dev бенчмарки). Относитесь к ним как к точке отсчёта, а не к измеренной истине в вашей среде.
Похожие материалы
- Cursor Users Code 65% More: AI Copilot Impact — измеренное влияние облачных AI-инструментов на объём кода
- VS Code vs JetBrains vs Cursor 2026 — с какой IDE-средой ваша self-hosted модель должна интегрироваться
- On-Premise деплой: PanDev Metrics с Docker и Kubernetes — деплой-модель, которую используют compliance-тяжёлые клиенты для телеметрии
- Внешнее: Документация vLLM — канонический референс по высокопроизводительному LLM-serving в 2026