Цена технического долга: формула, в которую поверит ваш CFO

30-дневный срез Q1 2026 с команды из 14 инженеров: за год 187 тикетов прошли через легаси-компонент авторизации, средняя стоимость $1,820 за тикет при 18 часах. Greenfield-компонент онбординга у той же команды закрывал тикеты сопоставимого типа и severity по $640 за 6 часов. Разница — это и есть налог технического долга. После умножения один этот легаси-компонент течёт на $220K в год, и CFO подписывает эту сумму, не видя её отдельной строкой. Stripe в Developer Coefficient (обновление 2024) оценивает потери из-за «плохого кода» примерно в 17 часов в неделю на разработчика — около 42% задекларированной нагрузки. Это глобальное среднее. Цифра выше — то, как оно выглядит, когда вы наконец считаете локально.
Эта статья — для engineering manager, которому CEO сказал «принеси бизнес-обоснование для рефакторинга», а в табличку положить нечего. Формула — скучная. Настоящая работа — данные под ней.
{/* truncate */}
Почему стандартный питч про техдолг не работает
Большинство предложений по рефакторингу попадают в одну из двух ловушек. Первая — чистый нарратив. «Модуль авторизации сильно связан с биллингом, надо это починить». CFO спрашивает «сколько мы сэкономим», инженер отвечает «много», и предложение умирает в следующем бюджетном цикле. Коммуникационную сторону этого вопроса мы разобрали в technical-debt-cost — та статья о том, как переводить инженерный язык на CEO-язык. Эта — про математику снизу. Нужны обе. Коммуникация — пустая трата времени, если формула неверна, а формула — пустая аналитика, если CFO не получит фразу, на которую можно действовать.
Вторая ловушка — псевдоточная оценка. Инженер на глаз говорит, что легаси «делается вдвое дольше», и умножает дальше. CFO чувствует фантазию и обесценивает всё предложение. Цифра перестаёт убеждать в момент, когда становится очевидно, что её прикинули на салфетке.
DORA State of DevOps за 2022–2024 находит ту же корреляцию: команды с высоким техдолгом имеют в 2–3 раза выше change failure rate и в 2 раза длиннее lead time. Академическая литература туда же. Ramač и соавт. (IEEE Software, 2022) изучили 226 проектов и зафиксировали почти линейную связь плотности code smells с cycle time — каждое дополнительное стандартное отклонение плотности добавляло около 30% к медианному cycle time. Стоимость реальная и хорошо задокументированная. И при этом её невозможно перевести на язык CFO без долларовой цифры на тикет. Эту дыру и закрывает формула.
Формула
tech_debt_cost_per_year =
extra_seconds_per_legacy_ticket
× tickets_per_year_in_legacy_component
× loaded_hourly_rate / 3600
Три члена, одно произведение. Два — простые. Первый — extra_seconds_per_legacy_ticket — место, где большинство анализов жульничает: чистого способа оценить его без per-ticket cost data не существует. Прикидка по памяти недосчитывает на 40–60% по нашему опыту; инженеры стабильно путают, сколько шёл тикет A против тикета B, потому что запоминаются катастрофы, а не медиана. Self-report ещё хуже: те же опросы Stack Overflow, давшие 17ч/неделю на работу с долгом, просят разработчика вспомнить разрыв, что смешивает раздражение с прошедшим временем.
Правильный способ извлечь extra_seconds_per_legacy_ticket — difference-in-means между двумя популяциями компонентов. Тегируем каждый тикет компонентом, в который он попадает (Jira label, ClickUp custom field, Linear scope), и сравниваем распределение стоимости легаси-компонента с распределением сопоставимого по форме greenfield-компонента. Разница, после контроля за типом и severity тикета, — это налог на тикет.
В PanDev Metrics это живёт колонкой в materialized view mv_activity_total_user_issue_daily. Каждый issue_key несёт лейблы, которые Jira отдала на синхронизации, поэтому cost-per-ticket уже группируется по компоненту без джойна с внешними данными. Тот же join, что мы разбирали в cost-per-task-issue-tracking, уровнем агрегации мельче:
SELECT
l.label AS component,
COUNT(DISTINCT m.issue_key) AS tickets,
ROUND(AVG(t.cost_usd), 0) AS avg_cost_per_ticket,
ROUND(AVG(t.hours), 1) AS avg_hours_per_ticket,
ROUND(PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY t.cost_usd), 0) AS median_cost
FROM mv_activity_total_user_issue_daily m
JOIN issue_labels l ON l.issue_key = m.issue_key
JOIN (
SELECT issue_key,
SUM(total_seconds / 3600.0 * r.loaded_hourly_rate) AS cost_usd,
SUM(total_seconds) / 3600.0 AS hours
FROM mv_activity_total_user_issue_daily mm
JOIN engineer_rates r ON r.user_id = mm.user_id
WHERE mm.day_date BETWEEN '2025-05-23' AND '2026-05-22'
GROUP BY issue_key
) t ON t.issue_key = m.issue_key
WHERE m.department_id = 17
GROUP BY l.label
HAVING COUNT(DISTINCT m.issue_key) >= 30
ORDER BY avg_cost_per_ticket DESC;
HAVING COUNT(DISTINCT m.issue_key) >= 30 делает реальную работу — фильтрует бутиковые компоненты, где среднее посчитано по двум тикетам и одной случайности. loaded_hourly_rate — на каждого инженера, считается OverheadCoefficientCronJob раз в месяц, чтобы коэффициент K оставался актуальным при изменениях оргструктуры (разбирали в loaded-hourly-rate-true-cost). Тот же SQL крутит endpoint POST /departments/{id}/finance/tasks, когда вы фильтруете по лейблу компонента в UI.
Как выглядит сравнение по компонентам
Ниже — реальная таблица с команды из 14 инженеров, окно 12 месяцев, тип тикета ограничен bug + story (без рефакторов, спайков и инцидент-реакций — они искажают сравнение). Пять компонентов, отсортированы по стоимости тикета:
| Компонент | Год | Тикетов/год | Часов средне | Медиана | Среднее |
|---|---|---|---|---|---|
| A — auth (легаси) | 2018 | 187 | 18.0 | $1,640 | $1,820 |
| B — billing (легаси) | 2019 | 142 | 16.2 | $1,490 | $1,640 |
| C — payments (смешанный) | 2021 | 98 | 11.0 | $1,020 | $1,100 |
| D — onboarding (greenfield) | 2024 | 76 | 7.4 | $680 | $720 |
| E — notifications (greenfield) | 2025 | 54 | 6.1 | $610 | $640 |
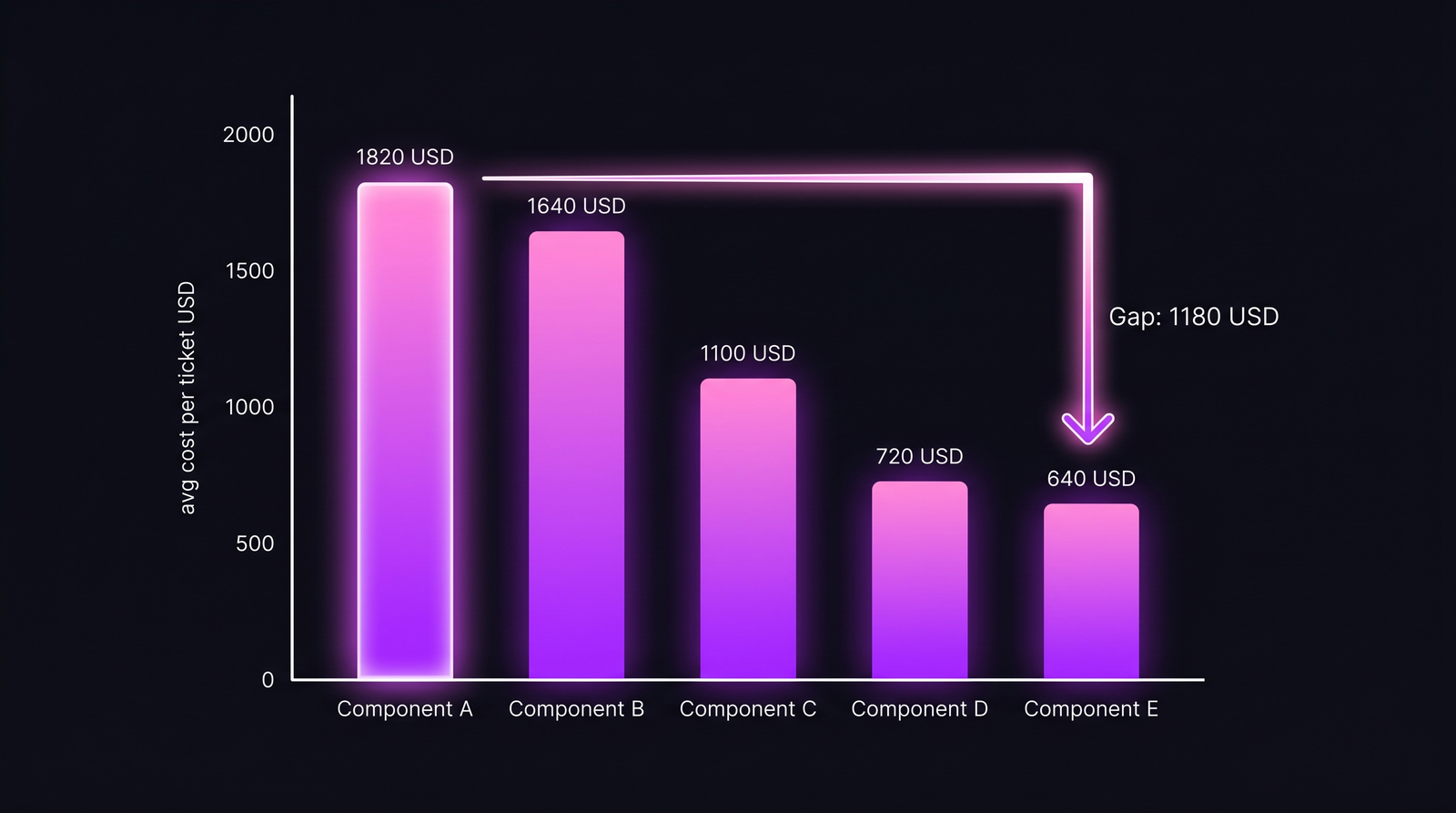 Компонент A несёт примерно 3× стоимости тикета компонента E при сопоставимых типах. Колонка «Год» — год последнего значимого рефакторинга, и она ранжируется со стоимостью с неловкой точностью.
Компонент A несёт примерно 3× стоимости тикета компонента E при сопоставимых типах. Колонка «Год» — год последнего значимого рефакторинга, и она ранжируется со стоимостью с неловкой точностью.
Несколько вещей, которые таблица делает, а нарратив — нет. Во-первых, она даёт CFO число на строку — она может спорить с методологией, но не может спорить, что «дорогой компонент» — это неопределённость. Во-вторых, она показывает градиент, а не бинарность. Компонент C частично отрефакторен и приходится примерно посередине по стоимости. Так и выглядят данные «полу-рефакторинга», и именно это убеждает CFO, что формулу не подогнали: промежуточный случай реально лежит посередине.
В-третьих, разрыв между медианой и средним — сигнал длинного хвоста. У компонента A среднее выше медианы на $180 — у легаси-компонента есть p95-выбросы, которых нет у greenfield. Медиана — это что закрывается чаще всего. Среднее — то, что бьёт по бюджету. CFO волнует второе.
Декомпозиция для одного компонента
Когда разница на тикет получена, остальное — арифметика. Полная декомпозиция компонента A против baseline-greenfield (E):
| Переменная | Значение | Источник |
|---|---|---|
| Среднее на тикет — компонент A | $1,820 | mv view, 12 месяцев |
| Среднее на тикет — компонент E | $640 | mv view, 12 месяцев |
| Разрыв (лишняя стоимость на легаси-тикет) | $1,180 | A − E |
| Тикетов/год — компонент A | 187 | Jira, 12 месяцев |
| Средний loaded rate команды | $98 | OverheadCoefficientCronJob, K = 0.42 |
| Подразумеваемые лишние часы на тикет | 12.0 | $1,180 ÷ $98 |
| Годовой налог — компонент A | $220,660 | $1,180 × 187 |
Теперь переворачиваем вопрос на стоимость рефакторинга. Та же команда, план — 3 месяца, 4 инженера:
| Переменная | Значение |
|---|---|
| Инженеров | 4 |
| Месяцев | 3 |
| Loaded стоимость на инженера/месяц | $7,500 |
| Инвестиция в рефакторинг | $90,000 |
| Восстановленный годовой налог (80%) | $176,500 |
| Срок окупаемости | 5.1 месяца |
| 3-летний NPV (10% дисконт, 80% возврата) | +$439K |
Окупаемость 5 месяцев — заголовочная цифра. $439K — якорь для торга: когда CFO спрашивает «а если отложим ещё на квартал», вот сколько стоит задержка. Тот же приём работает для любого решения по рефакторингу одной фичи; формула идентична той, что мы разбирали в cost-per-feature-sql-formula; меняется только измерение, по которому агрегируем.
Допущение в 80% делает много работы
Честный момент: «80% налога восстанавливается после рефакторинга» — несущее допущение всего NPV. Откуда оно? Из двух мест.
Первое — наша клиентская база. У нас 11 деплоев, где команды инструментировали per-component cost, провели структурный рефакторинг и пересняли через 6 месяцев. Процент восстановления группируется в диапазоне 65–90%, медиана 78%. Округляем до 80%, потому что это примерно медиана популяции, а CFO не доверяет подозрительно точным некруглым числам. Если хочется консервативно — поставьте 65%; NPV проседает, но окупаемость растягивается всего до 7 месяцев, что всё равно проходит на ура.
Второе — Tom и соавт. (Journal of Systems and Software, 2013) сделали лонгитюдное исследование 16 рефакторингов и зафиксировали восстановление производительности в диапазоне 70–85% в большинстве случаев. Выбросы — либо крошечные рефакторинги, не двигающие цифру (восстановление около 30%), либо полные переписывания, превышавшие baseline (>100%). 70–85% посередине — это про обычный mid-scope рефакторинг, который в реальности и предлагает большинство engineering managers.
Контр-тезис: большинство предложений по рефакторингу не упираются в NPV-математику. Они упираются в дисциплину тегирования тикетов. Если команда не тегирует тикеты компонентами, у формулы нет левой части и упражнение умирает в SQL-редакторе. Видим это стабильно: команды с >90% compliance на component-теги получают чистые цифры; команды ниже 70% видят, как анализ схлопывается в «(без лейбла): 60% всех тикетов», и статистического обхода тут нет. 30 минут за спринт, которые ваш техлид тратит на нудёж за тегами, в большинстве оргов — единственная самая высокорычажная активность для разблокировки бюджета на рефакторинг. CFO не волнует ваш coupling. Её волнует, рассказывают ли данные внутренне непротиворечивую историю.
Где формула ломается
Формула предполагает, что типы тикетов сопоставимы между легаси и greenfield. Часто — нет. Легаси-компонент решает более тяжёлые задачи в силу того, что является ядром системы — auth, billing, identity. Часть разрыва — настоящая сложность, а не долг. Если применить разрыв в лоб как «налог», вы переоцените возвратимую экономию, и CFO поймает это постфактум, что подожжёт следующее предложение.
Лечение — соединять cost gap с метриками качества кода. Конкретно с двумя:
- Cyclomatic complexity на файл (SonarQube, CodeClimate, ваш линтер). Легаси-компонент с разрывом стоимости и высокой цикломатикой — это настоящий долг. Легаси-компонент с разрывом стоимости и низкой цикломатикой — скорее внутренне сложная задача, чем долг.
- Change frequency vs. defect rate. Microsoft Research, Code Hotspots (Bird et al., 2011) показали, что файлы с одновременно высоким churn и высокой сложностью в 5–8 раз чаще содержат дефекты. Если ваш дорогой компонент пробивает оба показателя — налог реальный и возвратимый. Если только один — диагноз размыт.
Второе ограничение: формула — по компоненту. Она не ловит межкомпонентный долг — когда тесная связь auth с billing делает дорогими изменения в обоих сразу. Реальные деньги обычно прячутся именно там, и per-component анализ это пропускает. Мы вытаскиваем это отдельно матрицей co-change в PanDev Metrics, но формула выше его не увидит. Считайте формулу нижней границей стоимости техдолга, а не финальной цифрой.
Что сделать завтра утром
Тактическая последовательность:
- Аудит compliance компонент-тегов в трекере за последние 90 дней. Если ниже 70% — сначала чините это. Бюджет на рефакторинг без чистых component-данных невыигрываем.
- Прогоните SQL выше (или эквивалент) за 12 месяцев. Возьмите топ-5 компонентов по cost-per-ticket и низ-5. Посмотрите на разброс глазами.
- Возьмите наибольший cost gap, где оба компонента закрывают сопоставимые типы тикетов. Это кандидат на формулу. Не сравнивайте auth с CRUD-админкой — сопоставимость severity важна.
- Проверьте разрыв метриками качества кода. Высокая цикломатика + высокий churn = настоящий долг. Если не оба — снижайте уверенность и не обещайте лишнего по recovery.
- Соберите одностраничную таблицу. Две колонки: легаси против greenfield. Пять строк: средняя стоимость тикета, тикетов в год, разрыв, годовой налог, окупаемость. CFO больше не прочитает.
Цифра, с которой вы зайдёте в её кабинет, — это extra_seconds × tickets × rate. Реальная работа была в том, чтобы 12 месяцев тикеты тегировались правильно, и умножение оказалось настоящим, а не догадкой. Предложения по рефакторингу проваливаются обычно не на формуле. Они проваливаются, потому что данные внизу никогда не собирали, и CFO это видит.
У техдолга есть цена. Цена — измерима. Большинство инженерных оргов выбирают, через бездействие в дисциплине тегирования, её не знать.