Terraform: метрики внедрения для infra-команд

Команда внедрила Terraform 18 месяцев назад. Деплои медленнее, чем при старом click-ops, ревью занимают больше, и трое ваших лучших инженеров теперь тратят по полному дню в неделю на чтение вывода terraform plan. Старшее руководство спрашивает, окупилась ли миграция, и никто не может дать чистого ответа. Честный: вы никогда не определили, как «окупилась» выглядит в метриках. HashiCorp State of Cloud Strategy 2024 говорит, что 76% enterprise-компаний внедрили IaC, но только 31% меряют результаты против пред-внедренческого baseline. CNCF Annual Survey 2023 зафиксировал аналогичный gap по IaC-тулингу в целом.
Эта статья — фреймворк измерений для infra-команд, которые уже используют Terraform, OpenTofu или Pulumi. Мы не спорим, нужен ли IaC — этот корабль ушёл. Мы определяем шесть метрик, которые покажут, здорово ли идёт внедрение или деградирует, плюс бенчмарки по 37 компаниям в нашем датасете, у которых Terraform работает в проде.
{/* truncate */}
Проблема
Большинство заявлений об «успешном» IaC строятся на конечных состояниях («у нас теперь модули!»), а не на траекториях. Траектория важнее. Команда с 200 модулями и 15% reuse-rate в худшей позиции, чем команда с 40 модулями и 80% reuse, хотя на слайде первая выглядит «более внедрённой».
Самый частый failure mode: Terraform sprawl без консолидации. Через 18-24 месяца у команды копятся сотни .tf-файлов, десятки слабо-разделённых модулей, а apply-time выходит за 20 минут. В этой точке IaC тормозит команду вместо того, чтобы ускорять. Thoughtworks Technology Radar отмечал «Terraform sprawl» как антипаттерн с 2022 года.
6 метрик, которые надо трекать
Метрика 1 — Module reuse rate
Процент ресурсов, созданных внутри общего модуля vs. inline в root-конфиге. Низкий reuse = каждая команда переизобретает aws_s3_bucket с немного разными тегами и lifecycles.
Цель: 65-80% на инфраструктуре старше 12 месяцев. Красный флаг: ниже 40% после 18 месяцев внедрения.
Как мерить: считать блоки resource, смотреть, находится ли каждый внутри module. path или в root. Скриптуется за ~30 строк парсера.
Метрика 2 — Plan-to-apply ratio
Соотношение terraform plan к terraform apply за неделю. Планы, никогда не доходящие до apply = усталость ревьюеров, чрезмерно осторожные процессы или проблемы с plan-timeout.
Здоровый диапазон: 3:1 — 5:1 (планов больше, чем apply — нормально). Красный флаг: выше 10:1 (планы — шум, не сигнал) или ниже 1.5:1 (вы применяете слишком много без ревью).
Метрика 3 — Длительность apply (p50 + p95)
Медиана и хвост prod-apply. Это ваша частота деплоя инфраструктуры — метрика deployment frequency из DORA, применённая к IaC. Apply на 45 минут превращается в политику «батчить изменения» — так вы и оказываетесь с рискованными пятничными изменениями.
| Размер команды | Здоровый p50 | Здоровый p95 | Красный p95 |
|---|---|---|---|
| <10 infra-инженеров | 2-5 мин | 10 мин | 30+ мин |
| 10-30 инженеров | 5-10 мин | 20 мин | 45+ мин |
| 30+ инженеров | 5-15 мин | 25 мин | 60+ мин |
Метрика 4 — Plan failure rate
Доля планов, которые не запускаются (state lock, ошибки провайдера, drift). Это IaC-эквивалент change failure rate. Небольшой стабильный процент (2-5%) здоров. Растущий тренд — инфра дрейфует от кода.
Наши данные по 37 Terraform-компаниям:
| Этап внедрения | Медианный plan failure rate | 90-й перцентиль |
|---|---|---|
| Первые 6 месяцев | 8.2% | 18% |
| 6-18 месяцев | 4.1% | 11% |
| 18+ месяцев (зрело) | 2.7% | 7% |
| 18+ месяцев (sprawl) | 9.4% | 22% |
Сегмент «sprawl» — неприятный: команды на 18+ месяцах, у которых стало хуже, а не лучше. Причина почти всегда одна — модули плодились быстрее, чем консолидировались.
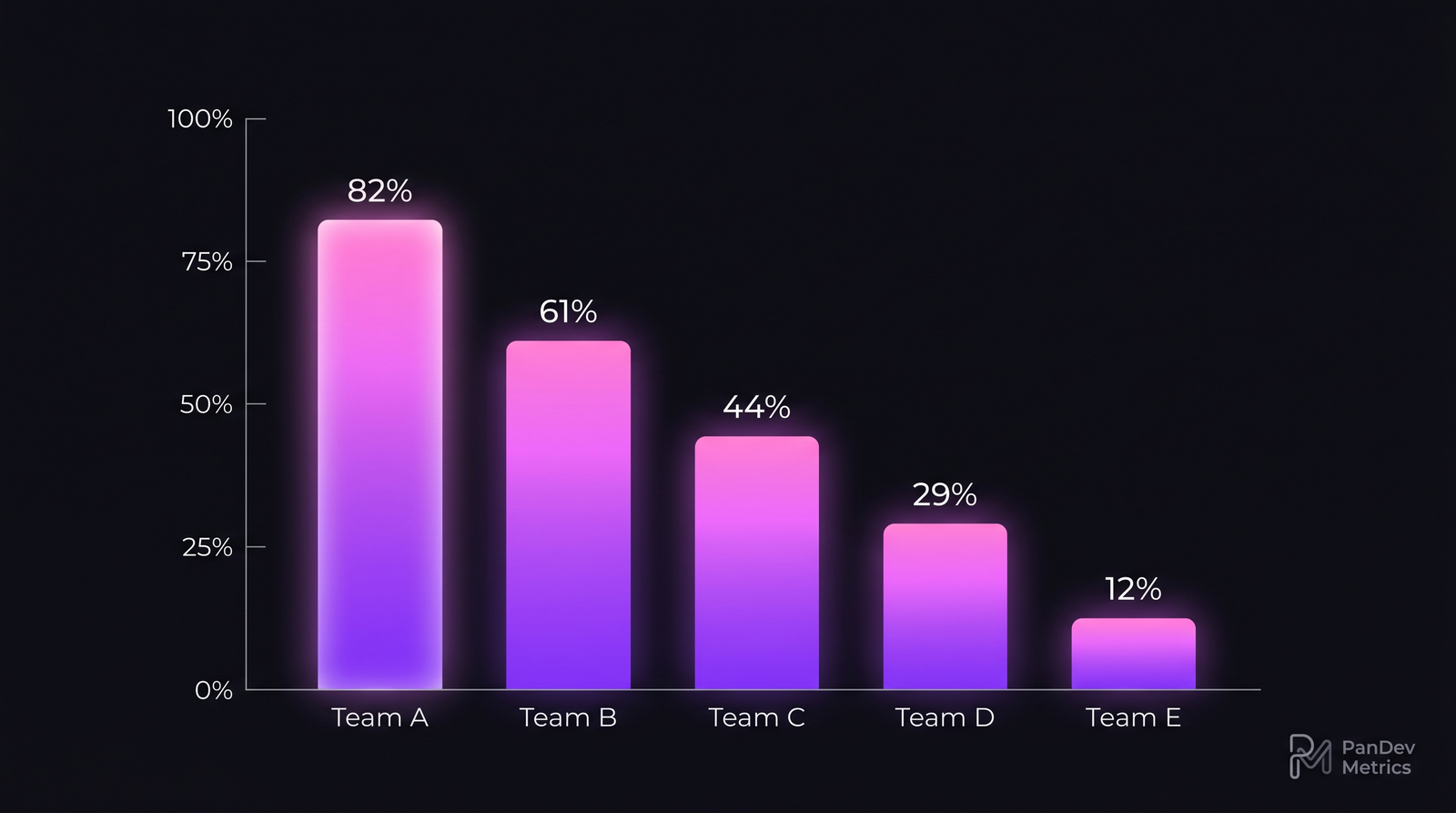 Module reuse rate отделяет здоровое внедрение Terraform от sprawl. Команда на 12% не получает выгоды от IaC — они пишут многословный boilerplate на HCL вместо реального языка.
Module reuse rate отделяет здоровое внедрение Terraform от sprawl. Команда на 12% не получает выгоды от IaC — они пишут многословный boilerplate на HCL вместо реального языка.
Метрика 5 — Каденс drift-детекции
Как часто вы сканируете прод на state drift (terraform plan без ожидаемых изменений, ловит неожиданные диффы). Команды без drift-детекции узнают реальность инфры во время инцидента.
Здорово: ежедневный drift-скан с алертами в команду-владельца. Допустимо: раз в неделю. Красный флаг: on-demand / по случаю.
Drift-сканы — feedback loop, который держит Terraform честным. Без них кто-то сделал console-change во вторник — код врёт до пятницы, когда следующий релиз ломается.
Метрика 6 — Инженеро-время на infra-задачу
Вот где IDE-телеметрия полезна. Трекайте время в .tf, .hcl, .tfvars — наше language-distribution разбирает это автоматически. Если IaC-работа выросла с 8% времени infra-команды (до внедрения) до 45% (1-й год) до 22% (3-й год), у вас здоровая S-кривая. Если застряла на 45% или полезла выше — sprawl.
| Фаза | Ожидаемая доля времени infra-команды на IaC |
|---|---|
| До внедрения (click ops) | <5% |
| Внедрение год 1 | 30-50% |
| Внедрение год 2 | 20-30% |
| Зрелое состояние | 10-20% |
Цифра стабильного состояния важна. IaC-внедрение, которое не вернулось под 30%, не окупается. Либо кодовая база слишком сложна для масштаба команды, либо модули так и не консолидировались.
Типичные ошибки внедрения
| Ошибка | Почему больно | Как чинить |
|---|---|---|
| Один гигантский state-файл | Apply-time взрывается, одно изменение блочит всё | Разделить по env + сервисам, remote state + data sources |
| Копипаст модулей вместо шаринга | Reuse падает, security-hardening не доезжает | Общий module-registry, блок новых resource-блоков вне модулей в CI |
| Нет drift-детекции | Реальность прода расходится с кодом, следующий деплой ломается | Ежедневный drift-скан, alert на diffs |
terraform apply с локальных машин | Нет audit-trail, расползание креденшлов | Apply только из CI/CD с OIDC, не long-lived keys |
| Модули без версий | Breaking changes тихо попадают в даунстрим | Обязательный version = pin во всех вызовах |
Как мерить успех через PanDev Metrics
Infrastructure-инженеры показываются в нашей IDE-heartbeat дате иначе, чем feature-инженеры. Их язык — HCL-heavy, активное coding-time ниже (планы идут), context-switching часто триггерится алертами, а не задачами. Language-distribution view в PanDev Metrics отделяет HCL / YAML / Starlark от Python / Go / Terraform-module-Go, чтобы вы видели реальную долю IaC в инженерных усилиях.
Три view, которые важны:
- Доля HCL-времени в времени infra-команды — сигнал метрики 6 выше.
- Context switching на infra-инженера — высокие значения коррелируют с firefighting из-за дрифта.
- Cost per infrastructure change — используя cost-per-feature view на infra-проектах, получаем долларовые цифры на IaC-время.
Чеклист
- Module reuse rate измеряется ежемесячно, цель ≥65% к месяцу 18
- Plan-to-apply ratio видим лидам, alert на >10:1
- Apply p50 и p95 — per environment
- Plan failure rate в тренде; расследовать любой рост после месяца 12
- Drift-детекция ежедневно, unexpected diffs — инциденты
- HCL-время infra-команды ограничено; рост триггерит sprint консолидации
- Новые модули требуют version pin, README и владельца
- Apply только из CI, локальных credentials нет
Когда Terraform — не тот инструмент
Фреймворк предполагает, что Terraform (или OpenTofu, один шаблон) подходит команде. Не всегда. Случаи пересмотреть:
- Single-cloud, в основном serverless, маленькая команда (<5 инженеров): AWS CDK или Pulumi на реальном языке часто выигрывает. Ценность Terraform растёт с multi-cloud и reuse модулей между командами.
- Быстро меняющаяся прототип-фаза: click ops — не грех при <3 месяцев. Преждевременный IaC сжигает недели на абстракции, которые потом удаляются.
- Только Kubernetes: ArgoCD + Helm + Kustomize обычно покрывает 90% того, для чего вы бы взяли Terraform. Terraform поверх — это второй источник правды.
Контрарианский тейк: внедрение Terraform часто продаётся как монотонный выигрыш. Это не так. Команды в нашем датасете, которые внедрили Terraform и 2+ года остались на низком module-reuse, продуцировали больше инфра-багов, чем команды, которые не внедряли вовсе. Инструмент без дисциплины модулей — результат хуже baseline click-ops.