Основные индикаторы PanDev Metrics
Кратко. PanDev Metrics показывает на дашборде три семейства индикаторов: DORA (здоровье поставки), продуктивность и вовлечённость (куда уходит время) и AI coding (доля человека vs модели). Все они выводятся из одних и тех же потоков событий — активность плагина, Git и таск-трекер, — обновляются по cron-расписанию и хранятся без срока. Кастомные метрики намеренно не поддерживаются.
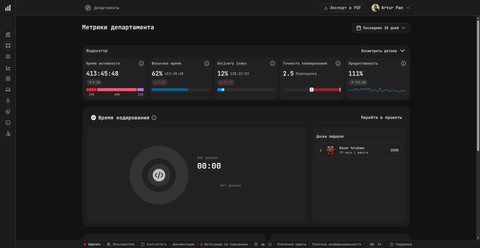
Дашборд департамента показывает сразу пять индикаторов продуктивности: Время активности, Фокусное время, Delivery Index, Точность планирования и Продуктивность — плюс отдельную карточку Время кодирования с Доской лидеров. У каждого индикатора видно абсолютное значение и изменение относительно предыдущего периода.
Три семейства индикаторов
Дашборд с тридцатью несвязанными числами — это шум. PanDev Metrics группирует индикаторы в три семейства, которые отвечают на три разных вопроса руководителя.
| Семейство | На какой вопрос отвечает | Главный источник |
|---|---|---|
| DORA | Команда нормально доставляет софт? | Git-провайдер + таск-трекер |
| Продуктивность и вовлечённость | Куда на самом деле уходит инженерное время? | События плагина IDE / browser / CLI |
| AI coding | Какая доля нашего вывода — человек, какая — модель? | IDE plugin + интеграции с AI |
Дальше — по каждому семейству: что значат числа и какие компромиссы заложил PanDev Metrics.
DORA-метрики
PanDev Metrics реализует четыре DORA-метрики из Accelerate State of DevOps Report программы Google DORA. Они измеряют поток доставки софта, а не объём работы — высокопроизводительные команды это не обязательно те, кто пишет больше кода.
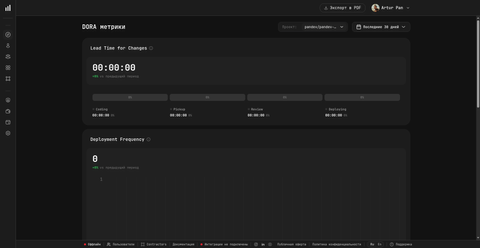
| Метрика | Что измеряет |
|---|---|
| Deployment Frequency | Как часто команда выкатывает на прод. |
| Lead Time for Changes | Сколько проходит от первого коммита до прода. Разбивается на четыре стадии: Coding / Pickup / Review / Deploying. |
| Change Failure Rate | Доля деплоев, повлекших инцидент или роллбэк. |
| Mean Time to Restore (MTTR) | Как быстро команда восстанавливается после провалившегося деплоя или инцидента в проде. |
PanDev Metrics показывает их в отдельном разделе DORA на дашборде с фильтрами по Project и Period и performance bands (Elite, High, Medium, Low) рядом с каждым значением. Бэнды соответствуют опубликованным DORA-определениям, чтобы число команды можно было сравнить с глобальным датасетом DORA.
Четыре стадии Lead Time видно прямо на дашборде — это делает Lead Time куда более операционным, чем единая агрегированная цифра: команда сразу видит, где теряется время — в Coding (само написание кода), Pickup (ожидание ревьюера), Review (итерации ревью) или Deploying (сам пайплайн).
DORA-метрики не считаются в реальном времени. Их пересчитывает плановая cron-задача, которая стартует в 02:30 UTC (см. Частота обновления ниже) — потому что входы (деплои, инциденты, роллбэки) накапливаются медленно, и пересчёт раз в минуту в основном повторял бы ту же арифметику. Точные определения «деплоя», «production-ветки» и «провального деплоя» для вашего тенанта смотрите в настройках DORA вашей организации — конвенции по компаниям различаются настолько, что PanDev Metrics сознательно их выставляет наружу, а не зашивает одну схему.
Время активности (Activity Time)
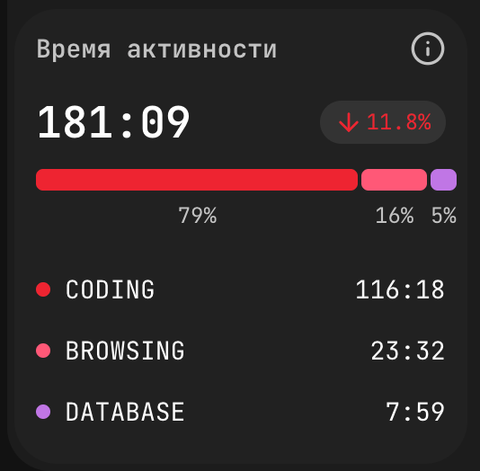
Время активности (англ. Activity Time) — это всё время, в которое система зафиксировала реальную работу у человека или команды. Это не «часы, когда IDE была открыта», а сумма интервалов между соседними событиями плагина, у которых gap меньше 15 минут. Длинные gap'ы вырезаются как перерывы. На карточке видно общее время и изменение относительно предыдущего периода. Полная механика — в Как работает плагин.
Индикатор разбивается на:
- Coding — написание и редактирование в IDE.
- Browsing — корпоративная документация, Jira, GitLab и другие разрешённые домены.
- Database — работа с БД в IDE-инструментах и вне их.
- Terminal — активность в CLI, включая операции с git.
- AI — взаимодействие с AI-инструментами (промпты).
Activity Time показывается как HH:MM (например, 181:09), с процентной динамикой относительно прошлого периода и разбивкой по категориям. Разделение на пять категорий позволяет руководителю с одного взгляда понять, ушли ли часы команды в код, в контекст (документация, тикеты) или в операции.
Фокусное время (Focus Time)
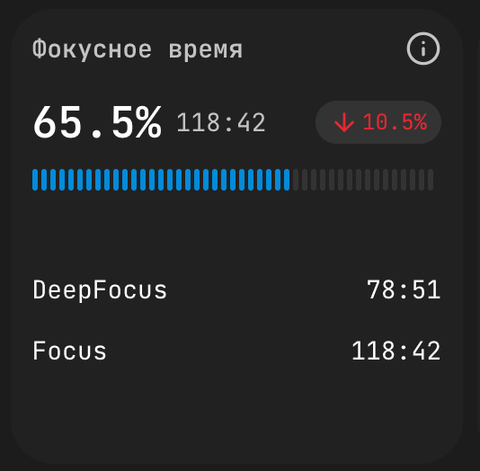
Фокусное время (англ. Focus Time) измеряет устойчивые непрерывные интервалы работы. Дашборд разделяет его по глубине:
- Focus — непрерывная работа над одной задачей с минимальным переключением контекста.
- DeepFocus — более длинные сессии без переключений, показатель способности к deep work.
Карточка показывает процент (фокусное время от общей активности), абсолютное значение HH:MM, динамику относительно прошлого периода и разбивку Focus / DeepFocus. Читать важнее именно разбивку, а не заголовочное число: высокий Focus при низком DeepFocus говорит, что команда сконцентрирована, но короткими всплесками; высокий DeepFocus — что есть пространство для по-настоящему сложных задач.
Продуктивность (Productivity)
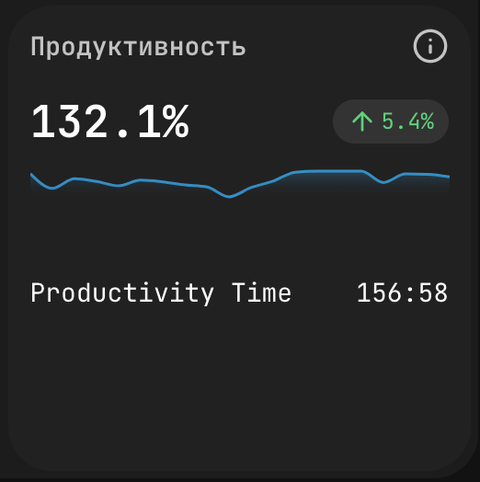
Продуктивность (англ. Productivity) сравнивает чистое время кодинга инженера с базовым ориентиром в 1 час в день. Значение 100% — попадание; на дашборде департамента можно увидеть, например, 111% (чуть выше цели) или 132.1% (превышение на треть), и рядом — изменение к предыдущему периоду (например, +102%). Карточка содержит спарклайн за выбранный период и стрелку динамики относительно предыдущего.
1 час — это не норма выработки, а калибровка под реальный инженерный день: большую часть времени занимают research, дизайн, ревью и обсуждения, и индикатор должен ловить факт реального кодинга, а не «полный рабочий день». Воспринимать это как норму — значит ломать сигнал: если инженеры начнут гнаться за числом, они его заиграют. Воспринимать как индикатор покрытия («был ли реальный кодинг сегодня?») — значит сохранить смысл.
Точность планирования (Planning Accuracy)
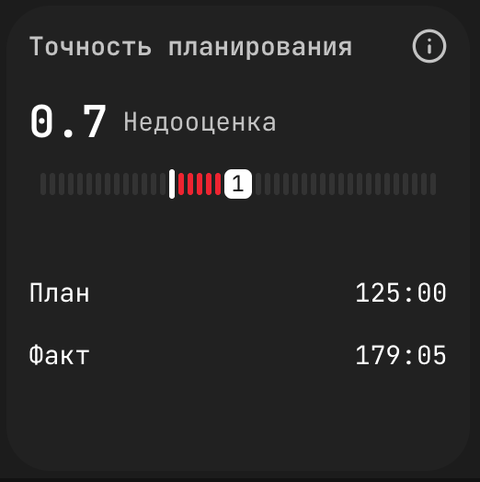
Точность планирования (англ. Planning Accuracy) — это отношение времени, запланированного на задачу в трекере, к времени, фактически зафиксированному плагином. Коэффициент 1.0 — идеал; < 1.0 — задача заняла больше, чем планировали; > 1.0 — задача сделана быстрее. На карточке отображается коэффициент, визуальная шкала и разбивка План / Факт — на дашборде департамента, например, можно увидеть значение 2.5 Переоценка, что значит: задача закрылась существенно раньше плана.
Индикатор полезнее всего в агрегате по большому числу задач — точность по одной задаче шумная. На горизонте квартала распределение показывает, систематически ли оценка оптимистична, пессимистична или хорошо откалибрована.
Время кодирования (Coding Time)
На дашборде департамента Время кодирования (англ. Coding Time) вынесено в отдельную карточку с Доской лидеров по сотрудникам. Если Время активности покрывает всю активность — код, браузер, терминал, AI, БД, — то Время кодирования изолирует только редактирование в IDE. Доска лидеров ранжирует инженеров по этому показателю за выбранный период, чтобы руководитель департамента одним взглядом видел, кто сейчас пишет больше всего кода.
Это не метрика-соревнование. Если воспринимать Время кодирования как норму выработки, сигнал ломается так же, как и в Продуктивности (см. выше): если инженеры начинают гнаться за местом в рейтинге, они перестают делать ревью, парнинг и думать — а это тоже часть работы. Доска лидеров — это вид на распределение, а не ранжирование; полезно, чтобы заметить выбросы в любую сторону.
CLI-метрики
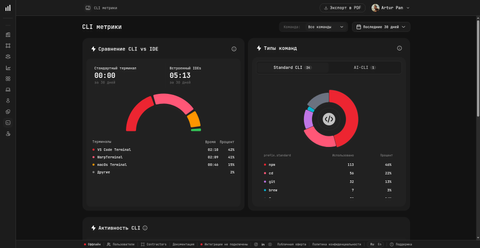
CLI-карточка берёт тот же поток событий, что описан в Как работает плагин, и отвечает на два вопроса: где инженеры запускают команды (распределение терминалов — например, VS Code Terminal 42%, WarpTerminal 41%, macOS Terminal 15%) и какие команды они запускают (разбивка на Standard CLI и AI-CLI). На карточке видны реальные названия команд, зафиксированные CLI-агентом — npm, cd, git, brew и т. п., — но никогда не аргументы, флаги или вывод.
На практике это позволяет менеджеру заметить, например, что инженер ушёл в AI-augmented терминал, или что команда сидит сразу в трёх разных терминалах, хотя унификация упростила бы поддержку.
Delivery Index
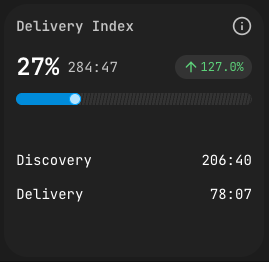
Delivery Index задаёт острый вопрос: из времени, потраченного на feature-ветке, сколько действительно доехало до merge request?
PanDev Metrics считает время на каждый файл. После создания MR каждый файл классифицируется:
- Delivery time — время по файлам, попавшим в MR.
- Discovery time — время по файлам, не попавшим в MR.
Индекс — это отношение Delivery к общему времени. Высокий Delivery значит, что разведка команды сошлась плотно к тому, что зарелизилось. Низкий — что много времени ушло в спайки, эксперименты и код, который выбросили. Иногда это нормально, иногда — сигнал нечёткого скоупа.
Учёт AI coding
PanDev Metrics ведёт два AI-связанных счётчика отдельно, потому что они отвечают на разные вопросы.
| Счётчик | Значение |
|---|---|
| AI prompts (активность разработчика) | Время, в которое инженер взаимодействует с AI-инструментом — пишет промпты, разбирает подсказки. Считается частью часов инженера. |
| AI-сгенерированный вывод (agent mode) | Время и объём работы, когда AI работает в режиме агента — самостоятельно правит файлы, бегает по репозиторию, выполняет команды. Inline-подсказки и автодополнения сюда не входят. |
Разделение позволяет видеть, как меняется соотношение «человек / модель» во времени, без взаимного загрязнения этих потоков. И «инженерные часы» при этом продолжают означать инженерные часы, даже когда половина команды сидит в Copilot или Cursor.
Расчёт стоимости
Стоимость задачи считается напрямую из тех данных, которые PanDev Metrics уже имеет: время × часовая ставка инженера.
Стоимость задачи = (время инженера на задачу) × (часовая ставка инженера) + пропорциональная доля нераспределённого рабочего времени этого же инженера.
Нераспределённое время — это активность, зафиксированная плагином, но не привязанная к конкретной задаче (ветка не совпала с соглашением, работа шла вне ветки и т. п.). PanDev Metrics распределяет его пропорционально между задачами этого инженера, чтобы итоги сходились с его реально оплачиваемыми часами. На выходе — стоимость на уровне задачи, проекта и подразделения, посчитанная по реальному времени, а не по сказке про story points.
Стоимость считается только в USD — конвертации валют в PanDev Metrics нет. Зарплаты задаются по сотруднику как hourly или monthly.
Переработки
PanDev Metrics определяет переработку просто: любая активность, зафиксированная в рабочий день вне рабочих часов сотрудника. Выходные и праздники определяются календарём компании и индивидуальным графиком сотрудника, причём личный график приоритетнее. Жёсткого порога «после 18:00» нет — граница задана рабочими часами сотрудника.
Орг-структура: проекты, департаменты, команды
В каждом индикаторе всплывают три структурных понятия.
| Понятие | Определение |
|---|---|
| Проект | Git-репозиторий. Один репо — один проект. |
| Департамент (Department) | Верхнеуровневая единица в дереве организации. |
| Команда (Team) | Единица, вложенная в департамент. |
По любой из них можно фильтровать индикаторы, и сотрудник, состоящий в команде, не выпадает из roll-up'а вышестоящего департамента.
Частота обновления
Индикаторы дашборда пересчитываются по расписанию, а не по каждому пришедшему событию. После очередной cron-задачи (DORA-пересчёт стартует в 02:30 UTC) PanDev Metrics перестраивает соответствующие materialized views и переносит свежие агрегаты в дашборд.
Компромисс осознанный: пересчёт по каждому событию задавил бы базу, не меняя числа, которые увидит пользователь. Интервал cron достаточно короткий, чтобы дашборд оставался полезен для дневных и недельных решений, и достаточно длинный, чтобы тяжёлые агрегаты (DORA, Delivery Index) считались эффективно.
Хранение данных
PanDev Metrics хранит все собранные данные без срока. Встроенной retention-политики и автозачистки нет. Логика прямая: сравнения «месяц к месяцу» и «год к году» — одни из самых полезных видов в инженерной аналитике, и срок хранения молча сломал бы их. Если для compliance нужна удалёнка — это обсуждается с поддержкой PanDev Metrics: удаление операционное, не продуктовая функция.
Кастомные метрики
PanDev Metrics не поддерживает кастомные метрики и редактор формул в самом продукте — набор индикаторов на дашборде фиксированный.
Логика двойная. Во-первых, каждая кастомная метрика становится контрактом на поддержку — схемы, обновления, производительность, нейминг — и небольшой набор хорошо отлаженных индикаторов стабильно бьёт длинный хвост штучных. Во-вторых, имеющиеся индикаторы закрывают вопросы руководителя, которые PanDev Metrics протестировал на своей клиентской базе; ощущение «нам нужен ещё один KPI» чаще всего значит, что текущие пока не читаются достаточно внимательно.
Если всё-таки нужны свои разрезы — Postgres под капотом
Под капотом PanDev Metrics — обычная реляционная PostgreSQL 17, доступная и в Cloud-, и в on-prem-инсталляциях. По договорённости команда даёт read-only доступ к выбранным таблицам и витринам, и любая компания может:
- Импортировать данные в собственное хранилище (BigQuery, ClickHouse, S3) и строить аналитику там
- Подключить Power BI, Tableau, Grafana, Metabase, Superset напрямую к Postgres и собирать свои дашборды и отчёты
- Гонять ad-hoc SQL по витринам — отдельный аналитик не теряет гибкость, которой нет в продуктовом UI
То есть фиксированный набор индикаторов — это про продуктовую поверхность, а не про границу данных: внутри Postgres у вас полная свобода интерпретации.
FAQ
Как часто обновляются индикаторы на дашборде?
Индикаторы пересчитываются плановыми cron-задачами, которые перестраивают materialized views PanDev Metrics и доносят свежие агрегаты до дашборда. Частота достаточная для дневных и недельных решений, но индикаторы не real-time и не задумывались такими. DORA в особенности накапливается медленно, и постоянный пересчёт был бы избыточным.
Можно ли добавить свою метрику или формулу?
Нет. PanDev Metrics сознательно поставляет фиксированный набор индикаторов, откатанный на многих тенантах, без редактора метрик. Если метрика нужна сразу нескольким клиентам — она добавляется в продукт. Точечные запросы под одного клиента не поддерживаются; типичный ответ — переложить исходные события на существующий индикатор так, чтобы он закрыл вопрос.
Сколько хранятся мои данные?
Без срока. Retention-политики и автозачистки в PanDev Metrics нет, потому что тренды на годовом горизонте — один из самых полезных видов для инженерного руководителя. Если по compliance данные нужно удалить, операционная команда сделает это вручную — продуктового переключателя для этого нет.
Как считается стоимость задачи?
PanDev Metrics умножает зафиксированное на задачу время на часовую ставку инженера и добавляет пропорциональную долю нераспределённого рабочего времени этого же инженера. Это разделение нужно, чтобы сумма стоимостей задач совпадала с фактически оплачиваемыми часами, а не только с чисто атрибутированными. Все суммы — в USD.
Что считается переработкой?
Любая активность, зафиксированная в рабочий день за пределами заданных рабочих часов сотрудника. Личный график приоритетнее календаря компании там, где они расходятся. Выходные и праздники определяются календарём плюс личным графиком. Плагин не следит за рабочим окном — он просто пишет, а классификация происходит уже на дашборде.
Проект — это репозиторий?
Да. PanDev Metrics считает один Git-репозиторий одним проектом. Объединение фич по нескольким репозиториям делается на уровне команды или департамента, а не схлопыванием репозиториев в один проект.
Чем команда отличается от департамента?
Департаменты — это верхнеуровневые единицы в дереве организации; команды вложены в департаменты. Инженер состоит в команде, которая состоит в департаменте, который состоит в тенанте. Индикаторы можно фильтровать и сворачивать на любом из этих уровней.
Связанные материалы
- Концепция: Как работает плагин — откуда берутся события.
- Концепция: Обзор продукта
- Концепция: Возможности PanDev Metrics